方法一(回溯+剪枝)
实现思路

实现代码
class Solution {
public:
void generate(int i,int sum,vector<int> item,vector<int> &nums,vector<vector<int>> &re,set<vector<int>> &re_set,int target){
if(i>=nums.size()||sum>target) return;
item.push_back(nums[i]);
sum+=nums[i];
if(sum==target&&!re_set.count(item)) {
re.push_back(item);
re_set.insert(item);
}
generate(i+1,sum,item,nums,re,re_set,target);
item.pop_back();
sum-=nums[i];
generate(i+1,sum,item,nums,re,re_set,target);
}
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
sort(candidates.begin(),candidates.end());
int pos=upper_bound(candidates.begin(),candidates.end(),target)-candidates.begin();
vector<int> nums(candidates.begin(),candidates.begin()+pos);
vector<vector<int>> re;
set<vector<int>> re_set;
vector<int> item;
if(target==0) re.push_back(item);
generate(0,0,item,nums,re,re_set,target);
return re;
}
};
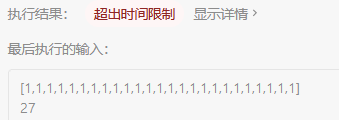
提交结果(TLE)
方法二(回溯+剪枝+重复元素处理)
实现思路
统计每个元素出现的次数,去除重复的元素
在回溯剪枝求解时:
查看当前数字的个数是否为1,
如果不为1,则还可以使用,
如果为1,就不能再使用
实现代码
class Solution {
public:
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
//记录每个数字的个数
for(auto c:candidates) {
auto iter = count.find(c);
if(iter == count.end()) {
count.insert(make_pair(c, 1));
}
else {
iter->second++;
}
}
//过滤掉重复数字,然后回溯
unordered_set<int> tmp(candidates.begin(), candidates.end());
candidates = vector<int>(tmp.begin(), tmp.end());
backtrace(candidates, 0, target);
return results;
}
void backtrace(vector<int>& candidates, int pos, int target) {
if(sum == target) {
results.push_back(result);
return;
}
if(sum > target) {
return;
}
for(int i=pos; i<candidates.size(); i++) {
result.push_back(candidates[i]);
sum += candidates[i];
//查看当前数字的个数是否为1,
//如果不为1,则还可以使用,
//如果为1,就不能再使用
auto iter = count.find(candidates[i]);
if(iter->second != 1) {
iter->second--;
backtrace(candidates, i, target);
iter->second++;
}
else {
backtrace(candidates, i+1, target);
}
result.pop_back();
sum -= candidates[i];
}
}
private:
map<int, int> count;
vector<vector<int>> results;
vector<int> result;
int sum;
};
//参考作者:damon-slh
这是别人书写的代码,值得参考如何去重,如何统计元素的个数,里面也用到了c++11之后新的数据结构unordered_set
提交结果

自己稍微修改了一点
核心伪代码:
- 当前和等于target压入结果
- 当前和大于targrt,剪枝不往下考虑
- 当前和小于target
- 从当前位置开始往后遍历考虑
1)放入当前元素,如果该元素大于1可以尝试再放入该元素,否则直接尝试放下艺元素
2)不放该元素,直接放下一元素
- 从当前位置开始往后遍历考虑
注意这里面sum实际上都是上一次操作完的结果,然后放在函数开头来进行判断,我之前实现的方式,是在函数中间来进行判断
class Solution {
public:
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
//记录每个数字的个数
for(auto c:candidates) {
auto iter = count.find(c);
if(iter == count.end()) {
count.insert(make_pair(c, 1));
}
else {
iter->second++;
}
}
//过滤掉重复数字,然后回溯
unordered_set<int> tmp(candidates.begin(), candidates.end());
candidates = vector<int>(tmp.begin(), tmp.end());
backtrace(candidates, 0, target);
return results;
}
void backtrace(vector<int>& candidates, int i, int target) {
if(sum == target) {
results.push_back(result);
return;
}
if(sum > target||i>=candidates.size()) {
return;
}
result.push_back(candidates[i]);
sum += candidates[i];
//查看当前数字的个数是否为1,
//如果不为1,则还可以使用,
//如果为1,就不能再使用
auto iter = count.find(candidates[i]);
if(iter->second != 1) {
iter->second--;
backtrace(candidates, i, target);
iter->second++;
}
else {
backtrace(candidates, i+1, target);
}
result.pop_back();
sum -= candidates[i];
backtrace(candidates, i+1, target);
}
private:
map<int, int> count;
vector<vector<int>> results;
vector<int> result;
int sum;
};
提交结果

class Solution {
private:
map<int,int> count;
public:
void generate(int i,int sum,int target,vector<int> item,vector<int> &nums,vector<vector<int>> &re){
if(sum==target){
re.push_back(item);
return;
}
if(sum>target||i>=nums.size())
{
return;
}
item.push_back(nums[i]);
sum+=nums[i];
auto iter = count.find(nums[i]);
if(iter->second!=1){
iter->second--;
generate(i,sum,target,item,nums,re);
iter->second++;
}
else{
generate(i+1,sum,target,item,nums,re);
}
item.pop_back();
sum-=nums[i];
generate(i+1,sum,target,item,nums,re);
}
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
for(auto c:candidates){
auto iter=count.find(c);
if(iter==count.end()){
count.insert(make_pair(c,1));
}else{
iter->second++;
}
}
unordered_set<int> tmp(candidates.begin(),candidates.end());
vector<int> nums(tmp.begin(),tmp.end());
vector<vector<int>>re;
vector<int> item;
int sum=0;
generate(0,sum,target,item,nums,re);
return re;
}
};
这是最后按我自己熟悉的编码方式,重新编写的代码

提交结果
总结
这道题其实挺值得思考的
两种方法的比较
第一个方法是我参照剪枝的思想和我自己的一点点优化,但最后结果超时了。
超时的样例:25个1构成的数组,target=27
扫描二维码关注公众号,回复:
12657309 查看本文章

- 超时的原因分析
实际上这27个1的子集有28个,但由于我的做法是相当于分别判断这个25个1放还是不放,需要判断2^25;
第二个方法处理了重复元素,先统计每个元素出现的次数,之后再回溯的时候判断是否还有该元素可用,可用的话就接着用,只有一个就用一个然后往后判断,所以针对上面方法的超时样例,可以只判断28个子集,由于去重后的数组中只有1这个元素,只需判断用几个1看看满不满足条件即可
方法二两种代码的比较
方法二给出了第一种代码,在一个尝试放该元素还是不放该元素后面使用了for循环,简化了一层递归;
第二种代码尝试放还是不放的最后我使用了递归而没用for循环,我觉得可能是这个原因导致这个的执行时间和内存消耗要更多一些;
第三个代码是按照我自己熟悉方法又重新编写了下代码,才发现自己有一个部分理解的不是很透彻,就是当计算得到sum==target的时候不仅要压入结果,而且要return,要不然会出现多个相同的子集。
需要掌握的代码片段
//利用map记录元素对应出现的个数
for(auto c:candidates){
auto iter=count.find(c);
if(iter==count.end()){
count.insert(make_pair(c,1));
}else{
iter->second++;
}
}
//去除vector中的重复元素
unordered_set<int> tmp(candidates.begin(),candidates.end());
vector<int> nums(tmp.begin(),tmp.end());