KMeans
典型的 划 分 聚 类 划分聚类 划分聚类
使用场景
- KMeans算法属于无监督学习,解决聚类的问题
- 对于数据集D, 不需提供数据标记,大大减少工作量
- 数据集D必须是凸集,非凸数据集难以收敛
- 必须先指定聚类簇数k
k-means优点
- 原理简单,实现容易,可解释性较强
- 聚类效果较好
- 主要的调参只有k
k-means缺点
- k值的选择不好把握
- 只适用于凸集,非凸数据集难以收敛
- 损失函数非凸,易收敛于局部最优解
- 对于噪声和异常点比较敏感
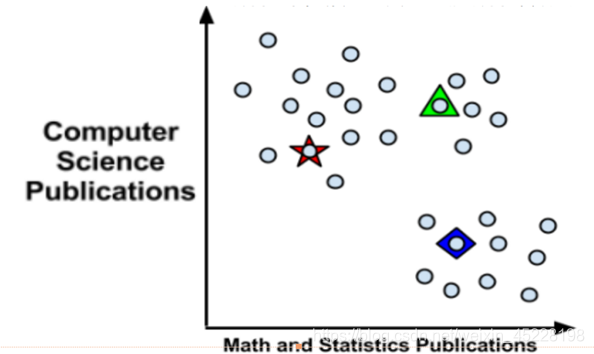
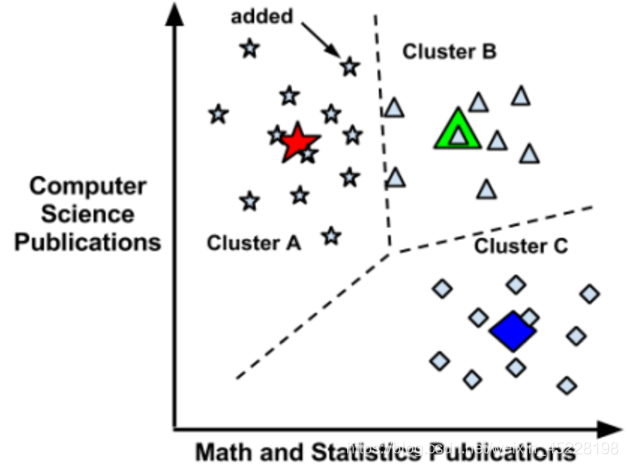
基本思想
簇内尽量紧凑,簇间尽量分散
算法步骤
- 随机初始化 k k k个聚类中心点:可以从样本集S中随机选择,也可以随机生成
- 遍历样本集S所有样本点,计算每个样本 x i x_i xi到 k k k个中心点的距离,将 x i x_i xi分配给距离最近的中心点所在的簇(给 x i x_i xi一个标记 y ^ i \hat y_{i} y^i)
- 取各个簇内所有样本的均值样本作为新的聚类中心点
- 重复2,3过程,直到达到一定的迭代次数或者聚类中心不再改变
python实现
import numpy as np
from matplotlib import pyplot as plt
import logging
logging.basicConfig(level=logging.INFO,format="%(asctime)s %(message)s")
import os
#计算欧式距离
def l2(x,y):
"""
x:样本点向量
y:样本点向量
return:距离标量
"""
return np.sqrt(np.sum(np.power(x-y,2)))
#初始化聚类中心 函数
def init_centers(S,k,method="select"):
"""
S:样本数据集,np数组
k:初始化聚类中心点的个数
method:初始化的方式
defaul,'select',random select k points from S
'random',random generation of k points
return np数值
"""
if method=="select":
#select k points from S
points=np.arange(S.shape[0])
select_points=np.random.choice(points,k)
return S[select_points]
elif method=="random":
#random generation
#样本集S每一列特征的min,max之间随机生成一个数值
#样本集的特征数
n=S.shape[1]
#初始化聚类中心点
centers=np.empty((k,n))
#生成聚类中心点每个特征的值
for j in range(n):
min_j,max_j=S[:,j].min(),S[:,j].max()
range_j=max_j-min_j
#生成第j特征的值,一维赋值
centers[:,j]=(min_j+range_j*np.random.rand(k,1)).ravel()
return centers
else:
#待扩展功能
pass
def nearest_neighbors(x,centers):
"""
x:单个样本向量
centers:聚类中心点,np数值
return (min_index,min_dist)
min_index:最近邻的索引
min_dist:最近邻的距离
"""
#初始化最小距离及其索引
min_index=-1
min_dist=np.inf #正无穷
#遍历中心点,计算距离
for idx,center in enumerate(centers):
x_center_dist=l2(x,center)
if x_center_dist<min_dist:
min_dist=x_center_dist
min_index=idx
return min_index,min_dist
#定义KMeans聚类函数
def kmeans(S,k,dist_measure=l2,max_iter=10,min_threshold=0.05):
"""
S:样本集,np数组
k:聚类簇数
dist_measure:距离度量,默认欧式距离
max_iter:最大迭代次数,int
min_threshold:聚类中心点变化的距离阈值,小于这个幅度则停止迭代
return (tag,centers,sse_list)
tag:样本标签
centers:聚类中心点
sse_list:误差平方和 list
"""
#样本总数,特征总数
m,n=S.shape
logging.info("current samples shape:%d,%d"%(m,n))
#1初始化k个聚类中心点
cluster_centers=init_centers(X,k,method="random")
#初始化样本标签 tag
tag=np.zeros(m)
#迭代过程中的sse
sse_list=[]
#控制迭代的轮数,只实现max_iter
iter_times=0
while max_iter and iter_times<max_iter:
#初始化误差平方和
sse=0
#2 计算所有样本的 最近邻 聚类中心
for i in range(m):
min_index,min_dist=nearest_neighbors(S[i,:],cluster_centers)
#样本i放入最近邻中心点所在簇
tag[i]=min_index
sse+=min_dist**2
sse_list.append(sse)
#重新计算聚类中心点
for idx in range(k):
cluster_centers[idx,:]=np.mean(S[y_hat==idx],axis=0)
iter_times+=1
return tag,cluster_centers,sse_list
if __name__=="__main__":
X=np.loadtxt("kmeansSamples.txt")
y_hat,centers,sse_list=kmeans(X,3,max_iter=6)
print("cluster tag:",y_hat)
print("sse list",sse_list)
fig=plt.figure()
plt.scatter(X[:,0],X[:,1],s=50,c=y_hat,label="samples")
plt.scatter(centers[:,0],centers[:,1],s=300,c=np.unique(y_hat),marker="*",label="centers")
plt.grid()
plt.legend(loc="best",frameon=True,framealpha=0.7)
plt.title("KMeans cluster")
plt.axis("equal")
fig.show()
sklearn库的实现
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
import numpy as np
from matplotlib import pyplot as plt
#实例化一个kmeans对象
kmeans=KMeans(n_clusters=3,random_state=9)
#加载数据
x=np.loadtxt("kmeansSamples.txt")
#数据归一化
ss=StandardScaler()
x_scale=ss.fit_transform(x)
#聚类拟合
kmeans.fit(x_scale)
#聚类标签
kmeans.labels_
#聚类中心点
kmeans.cluster_centers_
#对未知样本分簇
y_pred=kmeans.predict(x_new)
改进的kmeans
- 二分k-means:对每个簇进行k=2的kmeans聚类分簇,对SSE减少最多的簇优先二分聚类,促使算法收敛于全局最优解
- k-means++:初始化距离较远的聚类中心点(避免初始化中心点的扎堆),促使算法收敛于全局最优解
- k-mediods:重新选择聚类中心,而不是取每个簇的均值,让本簇所有其他样本点到该点的距离和最小,减少噪声的干扰
- mini batch kmeans:对大数据集时,采用抽样部分数据集做kmeans聚类,利用找到的聚类中心,对整个数据集分簇,从而降低kmeans的时间复杂度,但是以降低部分优化质量为代价。
基于kmeans项目
KMeans总结
