接着信息量与熵,我们再来看看条件熵,相对熵,交叉熵,信息增益,互信息,信息增益比。
1 信息量

2 熵


3 条件熵

4 相对熵(KL散度)
详解链接https://blog.csdn.net/u013066730/article/details/112988733

5 交叉熵

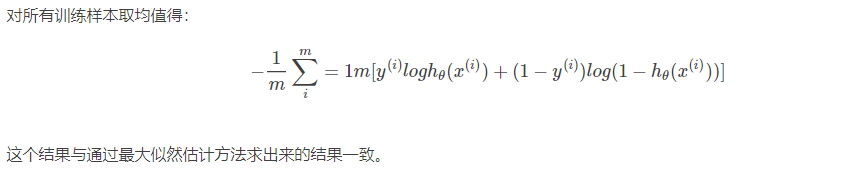
6 信息增益

西瓜书的第四章链接:https://pan.baidu.com/s/16xMD5CvTzO4TurNJ602Bmw 提取码:ydvv
推导公式:https://github.com/Sophia-11/Machine-Learning-Notes/blob/master/README.md
7 互信息

8 信息增益比

既然信息增益已经能够表明某一特征对于总体的信息的贡献,为什么还需要使用信息增益比呢?
具体请参照西瓜书4.2章节:https://pan.baidu.com/s/16xMD5CvTzO4TurNJ602Bmw 提取码:ydvv
简单来讲,就是当一个特征可能的取值数目非常多的时候,该类特征提供的信息往往越大,毕竟最终结果依据被分的更细了,获取的信息也更丰富了。但这并不代表就一定有效,这很容易导致他的泛化性能很差。
表示特征本身含有的熵。
本篇博客主要参考自:
《信息量、熵、最大熵、联合熵、条件熵、相对熵、互信息》
《交叉熵(Cross-Entropy) 》
《最大熵模型中的数学推导》
《我们为什么需要信息增益比,而不是信息增益? 》
https://blog.csdn.net/xg123321123/article/details/52864830#comments