1、准备工作
数据集
| 数据集 | 图 | 节点 | 边 | 特征 | 标签(y) |
|---|---|---|---|---|---|
| Cora | 1 | 2708 | 5429 | 1433 | 7 |
| Citeseer | 1 | 3327 | 4732 | 3703 | 6 |
| Pubmed | 1 | 19717 | 44338 | 500 | 3 |
数据集划分方式:https://github.com/kimiyoung/planetoid (Zhilin Yang, William W. Cohen, Ruslan Salakhutdinov, Revisiting Semi-Supervised Learning with Graph Embeddings, ICML 2016)
| 数据集划分(数量) | 训练集 | 验证集 | 测试集 |
|---|---|---|---|
| Cora | 140 | 500 | 1000 |
| Citeseer | 120 | 500 | 1000 |
| Pubmed | 60 | 500 | 1000 |
实验环境
- 云服务器GTX 2080Ti。
- PyTorch 1.6.0
- PyTorch Geometric 1.6.0
2、实验结果
实验均使用2层SAGE层进行。
使用PyTorch进行实验
参考:
- https://github.com/FighterLYL/GraphNeuralNetwork/tree/master/chapter7。
- 官方复现:PyTorch GraphSAGE Implementation–github
使用监督学习的方法,增加了Citeseer和Pubmed数据集,并对其代码进行了重构和调试,排除了一些小bug。
完善后的代码(minibatch):https://github.com/ytchx1999/GraphSAGE-Cora-Citeseer-Pubmed。
| 聚合 + 更新方法 | Cora | Citeseer | Pubmed |
|---|---|---|---|
| mean_pool + sum | 0.78 | 0.57 | 0.73 |
| max_pool + sum | 0.75 | 0.57 | 0.75 |
| mean_pool + concat | 0.74 | 0.55 | 0.75 |
| max_pool + concat | 0.75 | 0.59 | 0.75 |
数据集划分对实验(公平性)的影响
根据paper原作者的实验代码,重新划分数据集,做了实验(lr=0.1)
| 数据集划分(数量) | 训练集 | 验证集 | 测试集 |
|---|---|---|---|
| Cora | 1208 | 500 | 1000 |
| Citeseer | 1812 | 500 | 1000 |
| Pubmed | 2000 | 500 | 1000 |
| 聚合 + 更新方法 | Cora | Citeseer | Pubmed |
|---|---|---|---|
| mean_pool + sum | 0.85 | 0.59 | 0.76 |
结果比之前好不少,但是这种私自划分数据集在多个模型对比实验的时候不能够保证公平性。
使用PyG进行实验
使用PyTorch geometric(PyG)自己重写了GraphSAGE的代码,也不麻烦。
数据集的划分同最开始,因为图都比较小,所以直接使用full-batch,发现效果要比minibatch好一些。
实现代码:https://github.com/ytchx1999/PyG-GraphSAGE。
| 聚合 + 更新方法 | Cora | Citeseer | Pubmed |
|---|---|---|---|
| mean_pool + sum | 0.81 | 0.67 | 0.77 |
3、问题分析
-
GraphSAGE原文使用的citation数据集是WoS(一个比较大的图),效果要比本实验小图的效果好一点(小训练集),不过差距也不太大,也进一步说明了GraphSAGE归纳学习的能力。
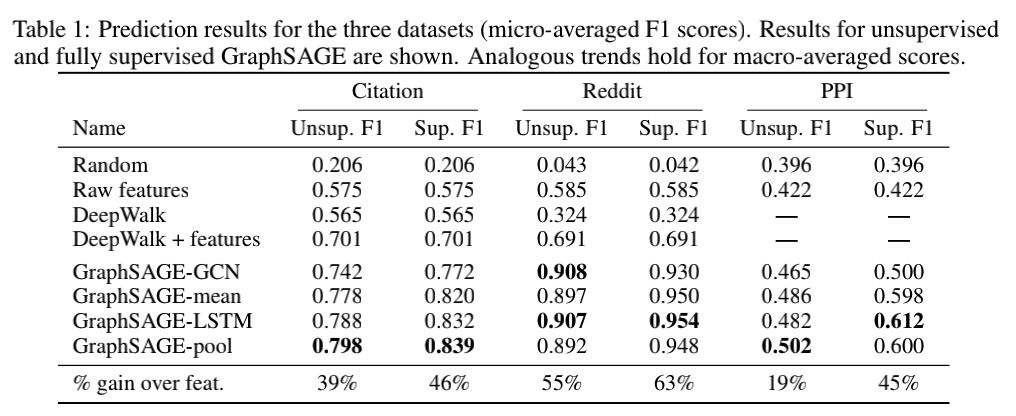
-
这是GNN综述《A Comprehensive Survey on Graph Neural Networks》中汇总各个paper的结果,但是GraphSAGE并没有使用到这几个数据集(Cora、Citeseer、Pubmed),可能是因为这几个数据集都比较小,而GraphSAGE对于大图来说效果比较好。GraphSAGE采样可能意味着邻居信息的丢失,这在小图中可能影响很大,因此,效果可能并不如GCN等模型。
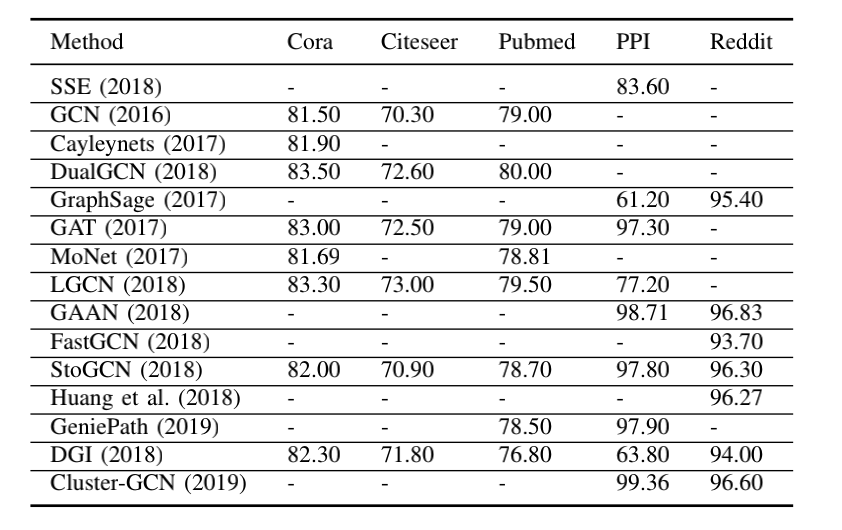
-
关于Citeseer数据集的问题。应该是有15个孤立节点,导致了程序出现问题以及训练精度都不好。
有2种思路来解决这个问题:①直接删除3312之后的节点;②补全法:Citeseer的测试数据集中有一些孤立的点没有在test.index中(15个),可把这些点当作特征全为0的节点加入到测试集tx中,并且对应的标签加入到ty中。
对于15个孤立节点,PyG采用了补全法强行将其补全为3327。。。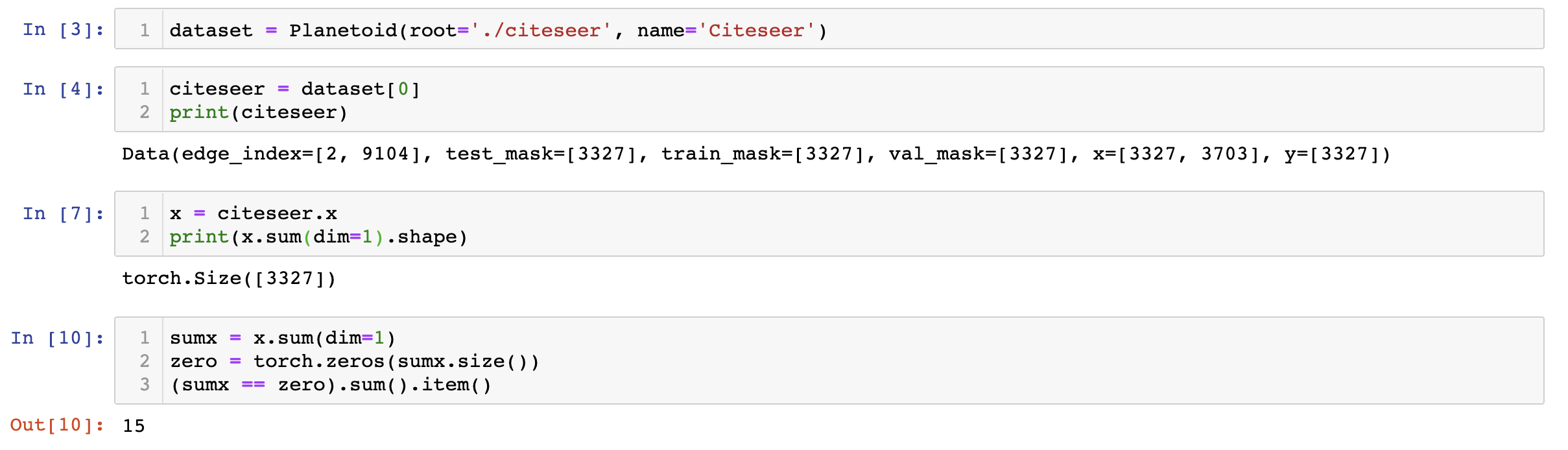
总之就是有问题,实际上总共有3327各节点,但是原始数据集是有向图,只有3312个节点有出边。只能说,数据集本身就有问题,这也导致了效果远不如Coras和Pubmed。
4、参考引用
代码:Chapter7:GraphSage示例(使用Cora数据集)–github
官方复现:PyTorch GraphSAGE Implementation–github
数据集划分:《Revisiting Semi-Supervised Learning with Graph Embeddings》–github
关于数据集:
《GCN使用的数据集Cora、Citeseer、Pubmed、Tox21格式》
《GCN数据集Cora、Citeseer、Pubmed文件分析》
《GCN的Benchmark数据集追溯》