目录
一、urllib
python自带的标准库 无需安装 直接可以用
提供以下功能:
网页请求、响应获取、代理和cookie设置、异常处理、url解析
扫描二维码关注公众号,回复:
12661587 查看本文章

urllib库的作用:网页爬虫、自动化处理表单、自动化测试脚本(如sqlmap
1.获取网页内容
根据url获取网页信息、网页信息实质是一段html、css、js代码
python2的代码,获取百度的网页信息
import urllib2
response = urllib2.urlopen("http://www.baidu.com")
print response.read()或者如下代码
import urllib2
request = urllib2.Request("http://www.baidu.com")
response = urllib2.urlopen(request)
print response.read()结果:
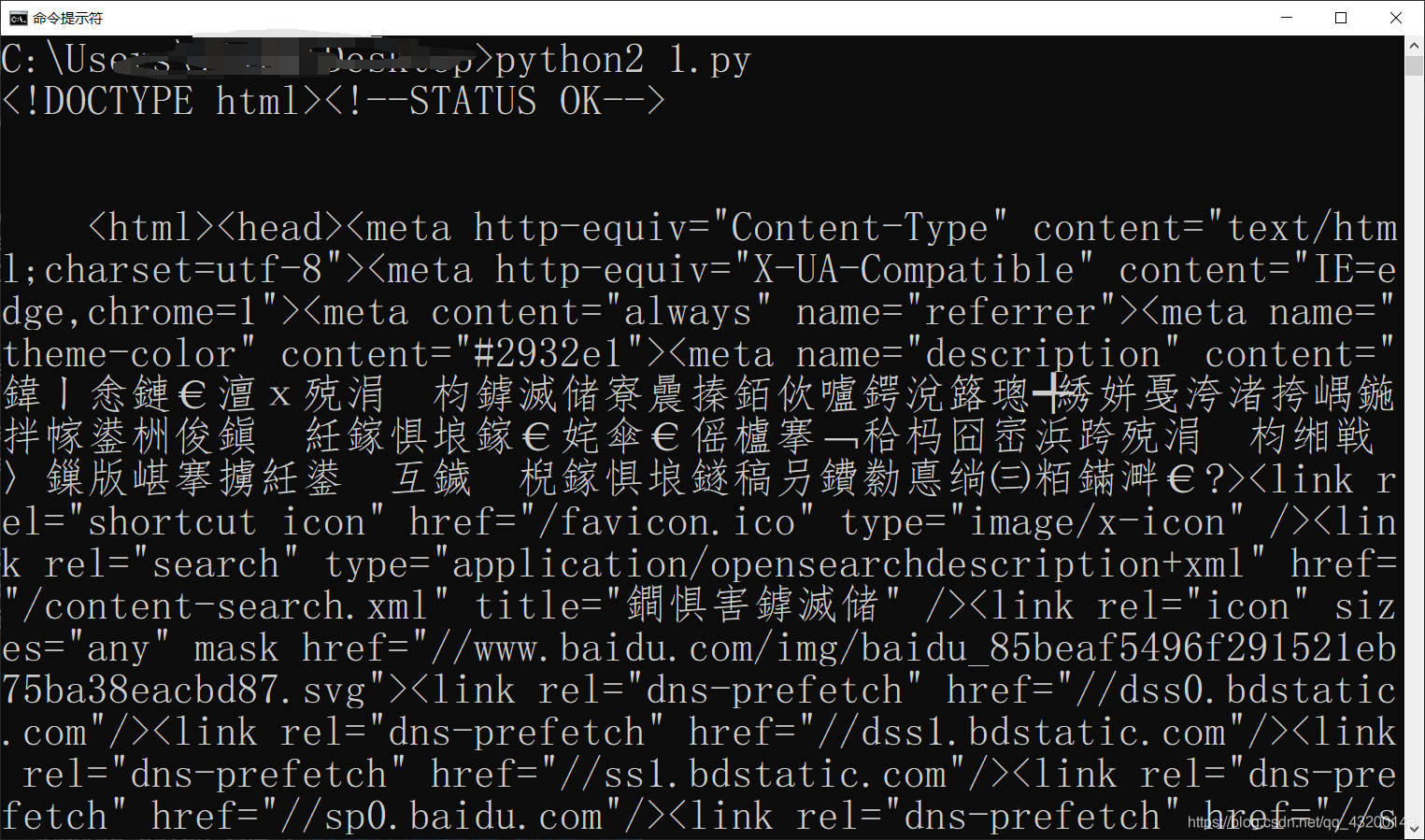
2.提交post请求、设置header
在request参数中加入data数据,request请求就会变为post类型
有些网站在处理http请求时需要验证header 防机器人爬虫什么的
timeout设置
异常处理
案例:地址错误
import urllib2
request = urllib2.Request('http://www.fdsafdsa.com')
try:
urllib2.urlopen(request)
except urllib2.URLError,e:
print e.reason
二、socket简单实例
服务端:
# -*- coding: utf-8 -*-
"""服务端"""
import socket #引入socket模块
s= socket.socket() #创建socket对象
host = socket.gethostname() #获取本地主机名
port = 12345 #设置绑定端口
s.bind((host,port)) #绑定主机和端口
s.listen(5) #设置最大连接数,开启等待连接
while True:
c,addr = s.accept() #建立客户端连接
print "连接地址: " ,addr
c.send('hello ')
c.close() #关闭连接
客户端:
# -*- coding: utf-8 -*-
"""客户端"""
import socket
s = socket.socket()
host = socket.gethostname()
port = 12345
s.connect((host,port))
print s.recv(1024)
s.close()
先运行服务端,等待连接

然后运行客户端,进行连接,客户端收到服务端发来的hello,然后关闭连接

服务端打印连接地址
