先来了解下所需要的基本知识储备:
在计算机系统中,CPU高速缓存是用于减少处理器访问内存所需平均时间的部件。在金字塔式存储体系中它位于自顶向下的第二层,仅次于CPU寄存器。其容量远小于内存,但速度却可以接近处理器的频率。
当处理器发出内存访问请求时,会先查看缓存内是否有请求数据。如果存在(命中),则不经访问内存直接返回该数据;如果不存在(失效),则要先把内存中的相应数据载入缓存,再将其返回处理器。
缓存之所以有效,主要是因为程序运行时对内存的访问呈现局部性(Locality)特征。这种局部性既包括空间局部性(Spatial Locality),也包括时间局部性(Temporal Locality)。有效利用这种局部性,缓存可以达到极高的命中率。
在处理器看来,缓存是一个透明部件。因此,程序员通常无法直接干预对缓存的操作。但是,确实可以根据缓存的特点对程序代码实施特定优化,从而更好地利用缓存。
— 维基百科
1、CPU高速缓存最小的单位 : 缓存行(Cache Line),当从内存中取单元到Cache中时,会一次取一个Cache Line大小的内存区域到Cache中,然后存进相应的Cache Line中。
2、为什么需要CPU cache?因为CPU的频率太快了,快到主存跟不上,这样在处理器时钟周期内,CPU常常需要等待主存,浪费资源。
所以cache的出现,是为了缓解CPU和内存之间速度的不匹配问题(结构:cpu -> cache -> memory)。
3、局部性:分时间 / 空间。
A、时间局部性:如果某个数据被访问,那么在不久的将来它很可能被再次访问
B、空间局部性:如果某个数据被访问,那么与它相邻的数据很快也可能被访问
4、在单核CPU结构中,为了缓解CPU指令流水中cycle冲突,L1分成了指令(L1P)和数据(L1D)两部分,而L2则是指令和数据共存。
缓存行 (Cache Line)
Cache是由很多个 Cache line 组成的。Cache line 是 cache 和 RAM 交换数据的最小单位,通常为 64 Byte。当 CPU 把内存的数据载入 cache 时,会把临近的共 64 Byte 的数据一起加载放入同一个Cache line,以此来提升效率( 空间局部性:临近的数据在将来被访问的可能性大)。
比如有下面代码:
public void run() {
int[] row = new int[16];
for(int i = 0; i < 16; i++ ) {
row[i] = i;
}
}长度为16的row数组,在Cache Line 64字节数据块上内存地址是连续的,能被一次加载到Cache Line中。遍历的话也是直接从缓存行中读取,而不是主内存,效率极高。
public static void main(String[] args) {
long sum=0;
long c = 0;
arr = new long[1024 * 1024][8];
// 横向遍历
long marked = System.currentTimeMillis();
for (int i = 0; i < 1024 * 1024; i += 1) {
for (int j = 0; j < 8; j++) {
sum += arr[i][j];
c++;
}
}
System.out.println("Loop times:" + (System.currentTimeMillis() - marked) + "ms ,循环次数:" + c);
marked = System.currentTimeMillis();
c = 0;
// 纵向遍历
for (int i = 0; i < 8; i += 1) {
for (int j = 0; j < 1024 * 1024; j++) {
sum += arr[j][i]; // 不连续的拿
c++;
}
}
System.out.println("Loop times:" + (System.currentTimeMillis() - marked) + "ms,循环次数: "+c);
}
==============打印结果
Loop times:10ms ,循环次数:8388608
Loop times:38ms,循环次数: 8388608以上两段代码引用知乎,个人觉得博主举例很好的解释这个原理以及现象。
两次循环都是一样的次数,所耗的时间却大大的不同,纵向遍历比横向遍历花费的时间要少,是因为第二层都在缓存行中进行的。在java中long类型都是8个字节,因此在缓存行中(64个字节)可以存8个long类型。
说完CPU的缓存,再来说说CPU中缓存的状态协议
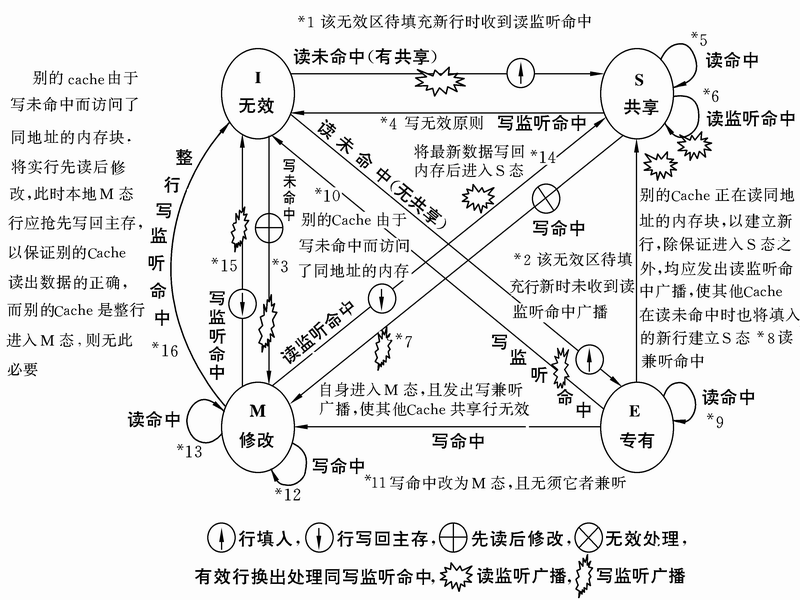
CPU MESI
该协议是处理器比较经典的Cache一致性协议,在单核Cache中每个Cache Line有两个标志:dirty、valid。而在多核处理器中,MESI协议描述了共享的状态。
每个Cache Line有4个状态。
| 状态 | 描述 |
| M(Modified) | 数据和Memory不一致,存在当前Cache |
| E(Exclusive) | 数据和Memory一致,存在当前Cache |
| S(Shared) | 数据和Memory一致,存在多个Cache |
| I(Invalid) | 无效数据 |
该图参考:https://blog.csdn.net/coslay/article/details/41790697
CPU切换状态阻塞解决-存储缓存(Store Bufferes)
如果你要修改当前缓存行,那么你必须将I(无效)状态通知到其他拥有该缓存行数据的CPU缓存中,并且等待确认。等待确认的过程会阻塞处理器,这会降低处理器的性能。因为这个等待远远比一个指令的执行时间长的多。
指令重排,store buffer(写队列)
指令重排是指程序在执行过程中,为了考虑性能,尽可能减少寄存器的读取、存储次数,重复复用寄存器的存储值,编译器和CPU会对指令重排序。
CPU会通过乱序的方式调整运行的效率,则会打乱程序原有顺序,但是绝对不可能出现两个线程被锁保护部分的指令交错执行的事情
CPU操作分为两种:load(读)、read(写)
那么读写会引发哪些问题?
JMM(Java内存模型)

JMM主要就是围绕着如何在并发过程中如何处理原子性、可见性和有序性这3个特征来建立的,通过解决这三个问题,可以解除缓存不一致的问题。而volatile跟可见性和有序性都有关。
1、原子性:
Java中,对基本数据类型的读取和赋值操作是原子性操作,所谓原子性操作就是指这些操作是不可中断的。比如a=2,这个赋值是原子操作,但是i++就不是原子操作,需要借助synchronized和Lock来保证原子性
2、可见性:
Java使用新的内存模型,使用happens-before的概念来阐述操作之间的内存可见性。
Java就是利用volatile来提供可见性的。 当一个变量被volatile修饰时,那么对它的修改会立刻刷新到主存,当其它线程需要读取该变量时,会去内存中读取新值。而普通变量则不能保证这一点。
其实通过synchronized和Lock也能够保证可见性,线程在释放锁之前,会把共享变量值都刷回主存,但是synchronized和Lock的开销都更大。
3、有序性:
JMM允许编译器和处理器对指令重排序
int a = 1; //A
int b = 2; //B
int c = a * b; //C执行顺序 A->B->C ,但是B->A->C的顺序也是可以,因为C依赖AB,AB可以重排序,但是C不可以排在AB前。JMM保证了单线程的执行,但是多线程就容易出问题。
比如:
int a = 0;
boolean flag = false;
public void write() {
a = 4; //1
flag = true; //2
}
public void multiply() {
if (flag) { //3
int ret = a * a;//4
}
}线程A执行write,然后线程B再执行multiply。最后的ret一定是16吗?

这时候可以给flag加上volatile,或者加上synchronized和Lock来保证有序性
JMM先天具有有序性,不需要任何手段就能保证有序性,通常称作happens-before原则,<<JSR-133:Java Memory Model and Thread Specification>>定义了如下happens-before规则:
1、程序顺序规则: 一个线程中的每个操作,happens-before于该线程中的任意后续操作
2、监视器锁规则:对一个线程的解锁,happens-before于随后对这个线程的加锁(在加锁之前,确定这个锁之前已经被释放了,才能继续加锁)
3、volatile变量规则: 对一个volatile域的写,happens-before于后续对这个volatile域的读
4、传递性:如果A happens-before B ,且 B happens-before C, 那么 A happens-before C (第一个例子就是这个规则)
5、start()规则: 如果线程A执行操作ThreadB_start()(启动线程B) , 那么A线程的ThreadB_start()happens-before 于B中的任意操作
6、join()规则: 如果A执行ThreadB.join()并且成功返回,那么线程B中的任意操作happens-before于线程A从ThreadB.join()操作成功返回
7、interrupt()原则: 对线程interrupt()方法的调用先行发生于被中断线程代码检测到中断事件的发生,可以通过Thread.interrupted()方法检测是否有中断发生
8、finalize()原则:一个对象的初始化完成先行发生于它的finalize()方法的开始
说完这么多,该说说Volatile到底有何作用
举例:
int a = 0;
volatile boolean flag = false;
public void write() {
a = 4; //1
flag = true; //2
}
public void multiply() {
if (flag) { //3
int ret = a * a;//4
}
}按happens-before原则,1在2前(volatile限制了指令重排序,1必须在2前),3在4前,2在3前,1在4前(传递性)
从JMM语义上来说
当写一个被volatile定义的变量,JMM会把变量从工作内存刷新到主内存
当读一个被volatile定义的变量,JMM会把工作内存中该变量失效,重新从主内存读取到自己的工作内存中
但是在多线程中,Volatile并不能保证原子性
Volatile的实现机制:
处理器有内存屏障----------
写内存屏障(Store Memory Barrier):处理器将存储缓存值写回主存(阻塞方式)。
读内存屏障(Load Memory Barrier):处理器,处理失效队列(阻塞方式)。
通过以上方式来保证操作之间数据的可见性。
volatile读前插读屏障,写后加写屏障,避免CPU重排导致的问题,实现多线程之间数据的可见性。
那么
lock:解锁时,jvm会强制刷新cpu缓存,导致当前线程更改,对其他线程可见
final:即时编译器在final写操作后,会插入内存屏障,来禁止重排序,保证可见性