Hadoop集群搭建
前言
hadoop集群搭建一般都采用3条服务器来演练,为什么是3呢?之前以为跟redis类似,由主从投票策略决定,后来想了想应该不是,因为主节点是nameNode节点,而从节点是dataNode节点,你的从节点在此时升级为master也没用吧。。。
后边找到一些资料说是跟hadoop的副本策略有关系,默认为3。所以,服务器数量小于3,意味着一台机器至少存有2个副本,大于3对于目的只是模拟测试来说、又有点浪费。。
搭建
hadoop不同版本似乎有些差别,下面是搭建的基本环境:
- 本文采用Hadoop 2.10.0版本
- CentOS Linux release 7.6.1810 (Core)
- 3台服务器(一台master、两台salve)
- 已安装JDK1.8
hadoop version

域名设置
为了方便文件传输总得标记一个ip,采用域名可以减少这种麻烦。
在3台机器的hosts文件输入如下内容:
192.168.0.28 master
192.168.0.14 node2
192.168.0.23 node1
在master机器的hostname文件中输入如下内容,slave节点的机器的hostname文件则分别输入node1、node2
master

注意,如果域名设置好了之后,后边想更改机器时,比如把ndoe2分配给其他机器,此时可能因为DNS缓存设置不成功。
service nscd restart
服务器免密登录
master连接slave节点时如果需要密码,可能连接会失败,所以需要设置下免密登录:
安装openssh-server服务
yum install openssh-server
master服务器输入以下指令一直回车,生成公钥和私钥:
ssh-keygen -t rsa
在master上将公钥放入authorized_keys(linux 操作系统下,专门用来存放公钥的地方,只要公钥放到了服务器的正确位置,并且拥有正确的权限,你才可以通过你的私钥,免密登录linux服务器),命令如下
cat ~/.ssh/id_rsa.pub > ~/.ssh/authorized_keys
发送公钥到node1、node2节点上,然后在master主机上试试ssh node1或者ssh node2能不能成功。一开始可能还会提示输入一遍密码,后边就不用了
scp ~/.ssh/authorized_keys root@node1:~/.ssh/
scp ~/.ssh/authorized_keys root@node2:~/.ssh
下载
最好将下载的包移动到一个区别其他目录的目录。
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.10.0/hadoop-2.10.0.tar.gz
解压
tar zxvf hadoop-2.10.0.tar.gz
添加hadoop文件路径到配置文件中:
export PATH=$PATH:/hadoop/hadoop-2.10.0/bin:/hadoop/hadoop-2.10.0/sbin

source /etc/profile
配置
创建hdfs
创建我们的HDFS(hadoop file system)文件系统。数据存储于该位置。

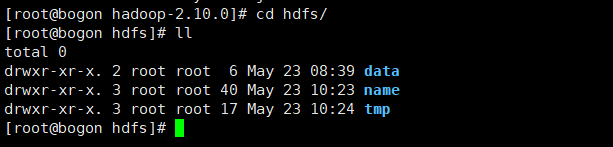
进入hdfs文件,分别创建如下目录:
name 存储namenode文件
data 存储数据
tmp 存储临时文件
修改XML文件
- core-site.xml
- hdfs-site.xml
- mapred-site.xml
- yarn-site.xml
- hadoop-env.sh
- slaves
上述文件都在hadoop的etc/hadoop/目录中:(图中漏了一个slaves的标记)

core-site.xml
注意,name属性不是想设置啥就设置啥的,它们是经过专业训练的,一开始傻傻的设置了一套,结果启动一直不行,重新改了回来,后来想想就觉得搞笑,如果可以随便设置的话,那hadoop启动扫描时岂不是得有很多繁琐的判断。

<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:8000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop/hadoop-2.10.0/hdfs/tmp</value>
</property>
</configuration>
hdfs-site.xml

<configuration>
<property>
<name>hdfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/hadoop/hadoop-2.10.0/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/hadoop/hadoop-2.10.0/hdfs/data</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
mapred-site.xml

<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-service</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>

hadoop-env.sh
这个文件主要配置了JDK的路径,注意!待会会将hadoop所有文件发送到从节点上,如果从节点的jdk路径跟master节点不一样,记得修改!!!

slaves
主要配置从节点的主机名,也就是node1和node2:

发送
将hadoop整个目录发送至node1和node2节点上:
scp -r hadoop-2.10.0 root@node1:/hadoop/
scp -r hadoop-2.10.0 root@node1:/hadoop/
启动
格式化
master运行如下命令,格式化后,name目录会多出current目录。
hadoop namenode -format

拓展
Current:里面包含edits、fsimage、seen_txid、VERSION文件。
- edits 日志文件:客户端执行写操作会先写入edits日志,并且在内存中保留。
- fsimage文件:nameNode的镜像文件,每次checkpoing(合并所有edits到一个fsimage的过程)产生的最终的fsimage,同时会生成一个.md5的文件用来对文件做完整性校验。
- Seen_txid :非常重要,代表namenode的edits*文件尾数,namenode重启时会循序从头跑 edits_0000001~到 seen_txid 的数字。但format格式化之后会是0。
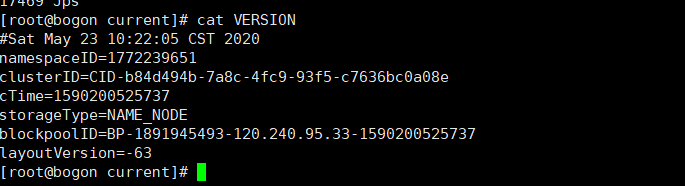
- Version :记录了集群的信息,如上图所示,它的信息有namespaceID/clusterID/blockpoolID。
在集群中,会有多个 NameNode 独立工作,每个NameNode 提供唯一的命名空(namespaceID),并管理一组唯一的文件块池(blockpoolID)。
cTime 存储系统创建时间,首次格式化文件系统为 0,当文件系统升级之后,该值会更新到升级之后的时间戳。
启动集群
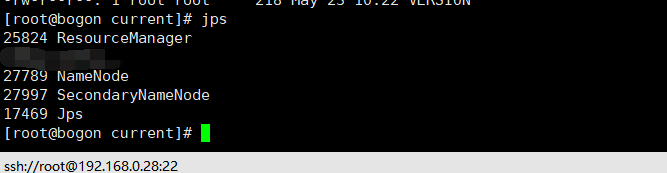
start-all.sh
master启动上述指令,输入JPS查看master进程
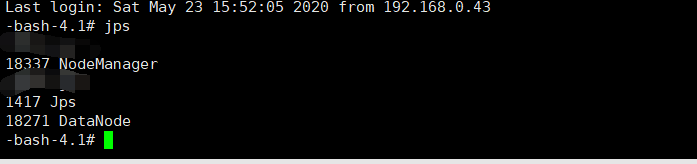
node节点输入jps查看进程
输入master网址,默认端口50070 http://192.168.0. 28:50070/
