猿人学爬虫攻防大赛 | 第三题: 访问逻辑 - 推心置腹
其实这道题已经写了好久了,一直放在电脑里好久,最近想起来了,就运行一下,还是能跑了。那就趁着有空写一下,纪录自己的步伐,顺便分享出来。
我们看一下这道题的名字 访问逻辑 - 推心置腹
那就是跟访问逻辑有关,其实这也给了我们解决的方向。
我们先抓一下包看看,当然仅仅看一页是不够的,要多看几页
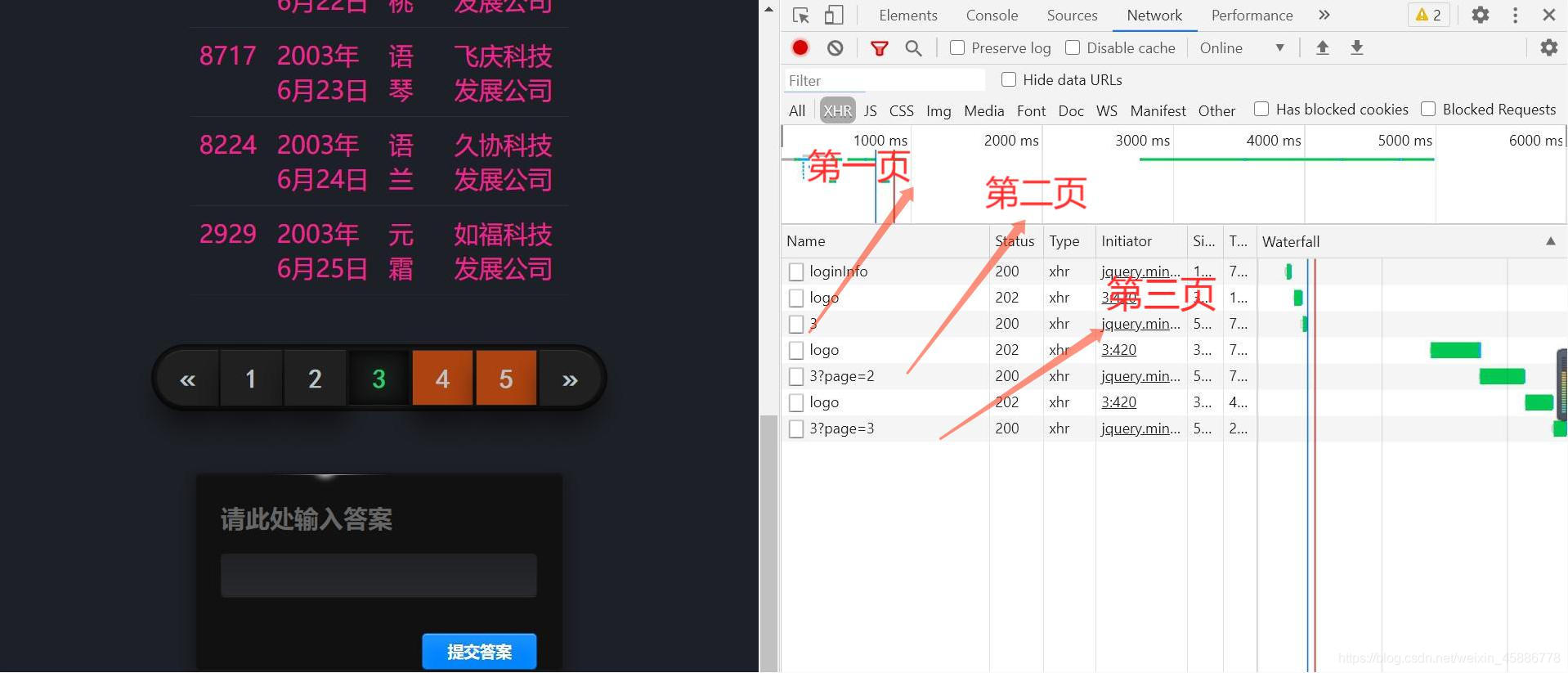
我们可以看到每个请求前都有一个logo请求。

当我们点第四页或者第五页时,会出现上面的弹窗。这也给了我们提示,与cookie有关。那我们就可以尝试一下。当然这里要用session进行共享cookie,
在经过我的尝试,成功了。还有就是它返回数据是json数据,很好处理。
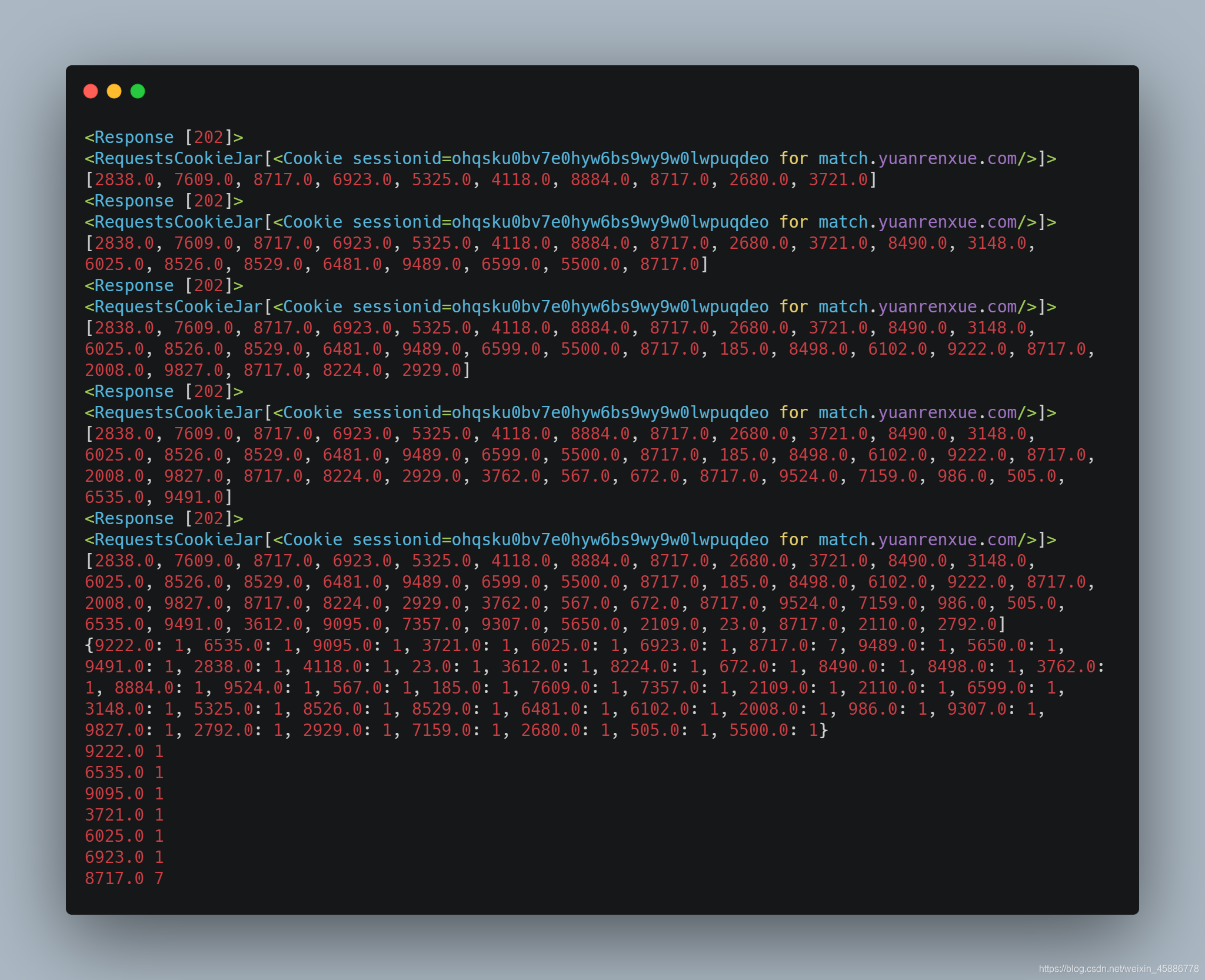
结果
代码
# author:Ajian
# 公众号:spiders
# datetime:2020/12/8 17:02
# software:PyCharm
import requests
session = requests.session()
headers = {
'Host': 'match.yuanrenxue.com',
'Connection': 'keep-alive',
'Content-Length': '0',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.55',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Origin': 'http://match.yuanrenxue.com',
'Referer': 'http://match.yuanrenxue.com/match/3',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
session.headers = headers
list = []
for page in range(1,6):
if page>=4:
headers['User-Agent'] = 'yuanrenxue.project'
else:
pass
url_logo = 'http://match.yuanrenxue.com/logo'
res = session.post(url_logo)
print(res)
print(res.cookies)
url_page = 'http://match.yuanrenxue.com/api/match/3?page={}'.format(page)
response = session.get(url=url_page,headers=headers)
data_list = response.json()['data']
list1 = [float(i['value']) for i in data_list]
list.extend(list1)
print(list)
set = set(list)
dic={
}
for i in set:
dic[i] = list.count(i)
print(dic)
max = 0
result = 0
for key in dic.keys():
if dic[key]>=max:
max = dic[key]
result = key
print(result,max)
好了,这一期到此结束,我们下期再见。
感觉可以的点个赞,顺便关注一下Ajian公众号(spiders).下面是二维码
