实战项目:学习网站的用户日志分析
日志分析能做什么:1.推荐 2. 投放广告引流 3.统计 TOP N 4.预测
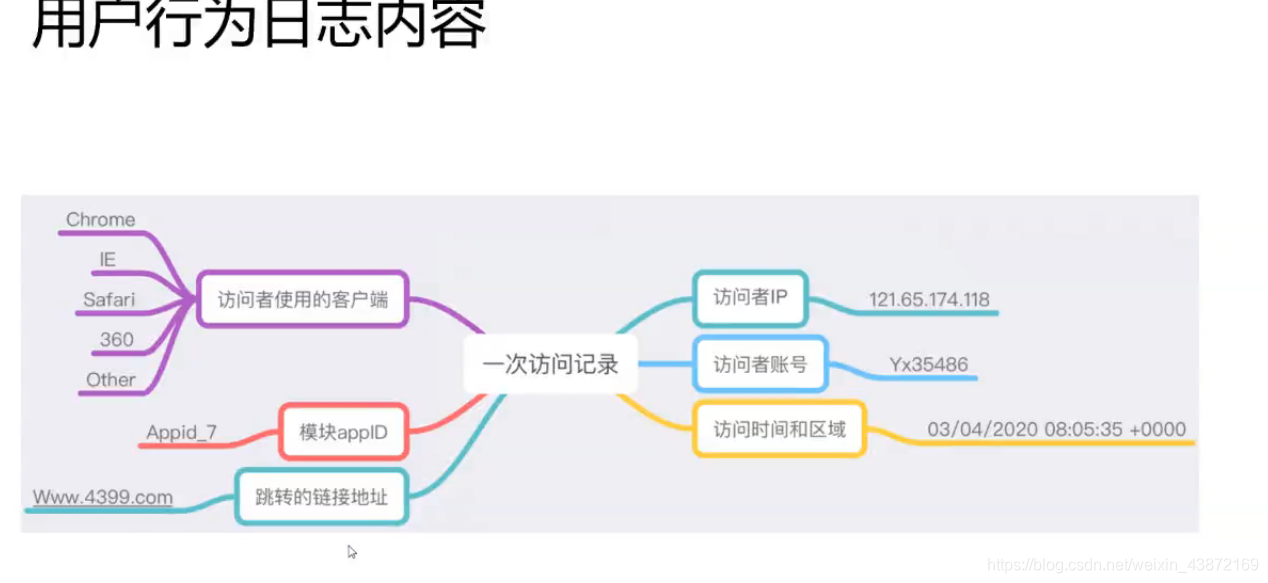
数据处理主要是两个:离线处理和在线处理
采集过来的日志:
1.数据不完整,不可用(脏数据)
用户行为日志分析的意义:
1.日志是网站的眼睛(引流,用户群体,网站的亮点)
2.日志是网站的神经(网页的布局非常重要,导航是否清晰)
3.日志是网站的大脑(统计最受欢迎的课程,每个城市喜欢的课程)
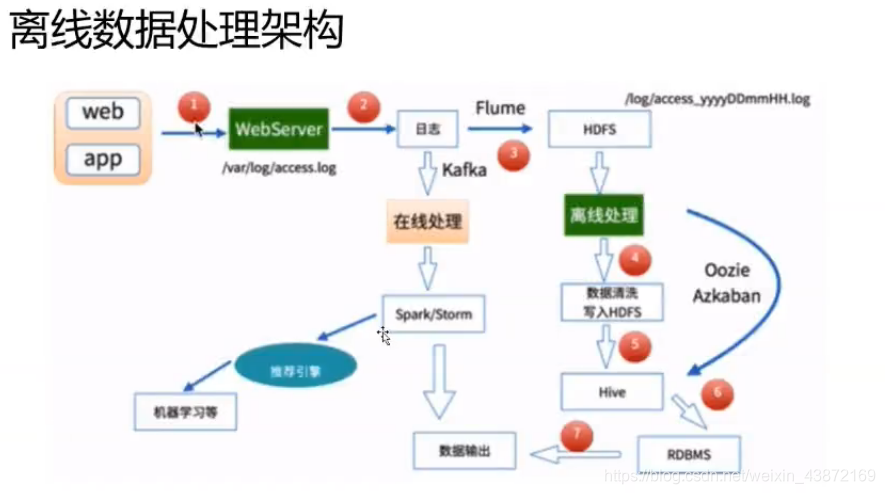
离线处理的流程:
1.数据的采集 Flume:web日志写入到HDFS上
2.数据清洗 脏数据(无效的数据)MapReduce,spark,hive等分布式计算框架 清洗完之后的数据(可用的数据)存入到HDFS系统中(hive/sparkSQL)
3.数据处理 按照需求进行相应的业务分析和统计 ,MapReduce,spark,hive等分布式计算框架
4.处理结果入库 结果存放到RDBMS(关系型数据库 mysql) NoSQL. HBase(大数据数据库)
5 数据可视化展示 通过图形化展示出来,饼状图,Echarts,HUZ等等
10.100.0.1 - - [10/Nov/2016:00:01:02 +0800] "HEAD / HTTP/1.1" 301 0 "117.121.101.40" "-" -
"curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.16.2.3 Basic ECC zlib/1.2.3 libidn/1.18 libssh2/1.4.2" "-" - - - 0.000
120.52.94.105 - - [10/Nov/2016:00:01:02 +0800] "POST /api3/getmediainfo_ver2 HTTP/1.1" 200
633 "www.imooc.com" "-" cid=608&secrect=e25994750eb2bbc7ade1a36708b999a5×tamp=1478707261945&token=9bbdba949aec02735e59e0868b538e19&uid=4203162 "mukewang/5.0.2 (iPhone; iOS 10.0.1; Scale/3.00)" "-" 10.100.136.65:80 200 0.049 0.049
117.35.88.11 - - [10/Nov/2016:00:01:02 +0800] "GET /article/ajaxcourserecommends?id=124 HT
TP/1.1" 200 2345 "www.imooc.com" "http://www.imooc.com/code/1852" - "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.71 Safari/537.36" "-" 10.100.136.65:80 200 0.616 0.616
因为空格位置不同,所以split()函数不能用
分析:针对不同的浏览器进行统计操作(UserAgent)
1.用GitHub上的UserAgent的写好的功能
User Agent Parser包进行解析UserAgent信息
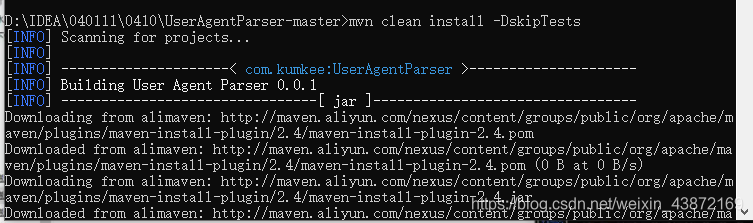
2.打成jar包 mvn clean package -DskipTests
(打包生成的jar包是没有办法再IDEA中使用的,因为还没有变成依赖包)
添加依赖命令 mvn clean install -DskipTests
IDEA中添加依赖
<dependency>
<groupId>com.kumkee</groupId>
<artifactId>UserAgentParser</artifactId>
<version>0.0.1</version>
</dependency>

开发(开发之前先测试,测试通过了直接复制到程序上):针对不同的浏览器进行数量统计操作(UserAgent)
依赖导入进去之后进行测试UserAgentParser
- 创建一个测试类
开发一个测试方法
package org.example;
import com.kumkee.userAgent.UserAgent;
import com.kumkee.userAgent.UserAgentParser;
import org.junit.Test;
public class UserAgentTest {
@Test
public void testUserAgentParser(){
//source就是useragent日志
String source = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.71 Safari/537.36";
UserAgentParser userAgentParser = new UserAgentParser();
UserAgent agent = userAgentParser.parse(source);
String browser = agent.getBrowser(); //获取source中的浏览器名称
String engine = agent.getEngine(); //获取浏览器的内核
String engineVersion = agent.getEngineVersion(); //内核版本
String os = agent.getOs(); //操作系统
String platform = agent.getPlatform(); //平台
Boolean ismobile = agent.isMobile(); //是否为移动端
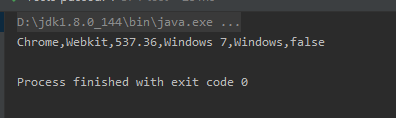
System.out.println(browser+","+ engine+ ","+ engineVersion +","+os+","+platform+","+ismobile);
}
}
2.怎么在一条访问记录中提取我们的UserAgent信息
117.35.88.11 - - [10/Nov/2016:00:01:02 +0800] "GET /article/ajaxcourserecommends?id=124 HT
TP/1.1" 200 2345 "www.imooc.com" "http://www.imooc.com/code/1852" - "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.71 Safari/537.36" "-" 10.100.136.65:80 200 0.616 0.616
我们可以看出是从第七个“开始到第八个”之间的
3.怎么从log文件中读取到一条日志消息
工作流程:
1.把文件读取到程序中
2.读取每一行的记录
3.提取每行记录中的UserAgent字段
4.提取UserAgent字段中的浏览器字段
5.统计
总结:我们是wordcount案例演变出来的logapp
但是我们服务器端是没有UserAgentParser包,那么把打包的时候,把这个功能包一并打包。需要加一些配置
hadoop依赖服务器上有但是UserAgentParser是没有的
用来改变maven的打包方式,打包的时候就可以加上依赖一起打包了
加上如上两个地方
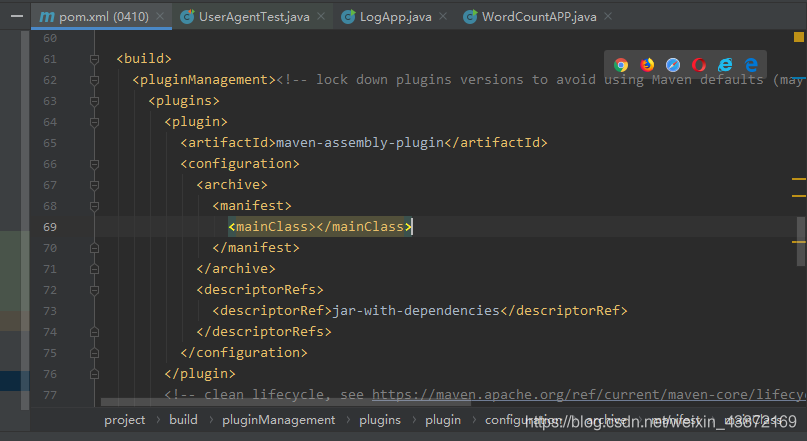
表示hadoop依赖还是用自己的
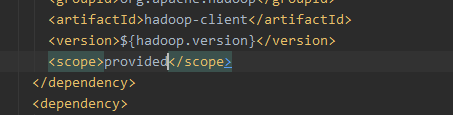
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<archive>
<manifest>
<mainClass></mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
打包命令也改了
mvn assembly:assembly
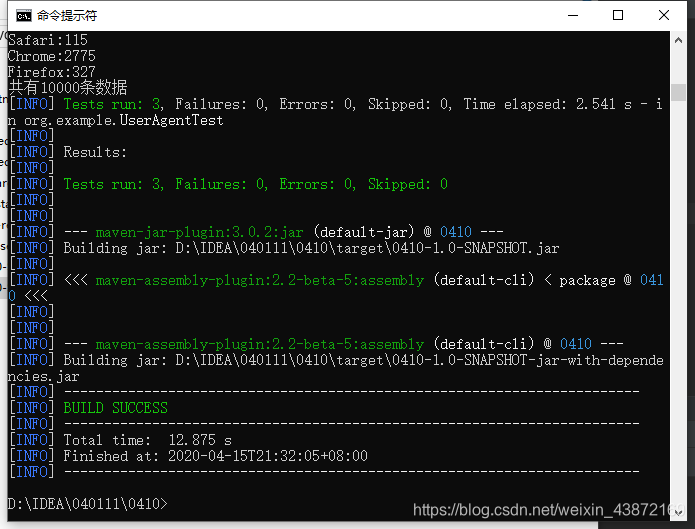
jar包和数据都上传到服务器运行就可以了。
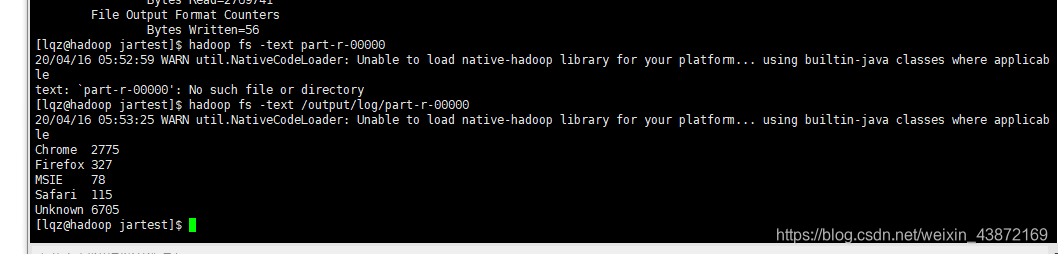
hadoop jar /home/lqz/data/jartest/0410-1.0-SNAPSHOT-jar-with-dependencies.jar org.example.LogApp hdfs://192.168.1.65:8020/a
ccess_10000.log hdfs://192.168.1.65:8020/output/log

详细代码如下所示:
package org.example;
import com.kumkee.userAgent.UserAgent;
import com.kumkee.userAgent.UserAgentParser;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author lqz
* @version 1.0
* @date 2020/4/12 20:43
*/
public class LogApp {
public static class MyMapper extends Mapper<LongWritable, Text,Text,LongWritable> {
LongWritable one = new LongWritable(1);//第一次是1
UserAgentParser userAgentParser; //声明
@Override
protected void setup(Context context) throws IOException, InterruptedException {
userAgentParser = new UserAgentParser(); //初始化
}
@Override //相当于输入一行的数据
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
LongWritable one = new LongWritable(1);//第一次是1
//接受一行的数据,转换成字符串 (每一行的日志信息)
String lines = value.toString();
//找到其索引位置提取浏览器的名称
String source=lines.substring(getCharacterPosition(lines,"\"",7));//提取useragent
UserAgent agent = userAgentParser.parse(source);
String browser = agent.getBrowser(); //获取source中的浏览器名称
//放在contest进行输出
//把<浏览器的名称,1>写到context中
context.write(new Text(browser),one); //封装成 cat 1 pig 1
}
@Override //把资源释放掉
protected void cleanup(Context context) throws IOException, InterruptedException {
userAgentParser=null;
}
}
//得到字符索引的方法
private static int getCharacterPosition(String value,String operator,int index){
Matcher matcher = Pattern.compile(operator).matcher(value);//正则的模式匹配
int midx=0; //从0开始
while (matcher.find()){
midx++;
if (midx==index){
//midx等于第七个”
break;
}
}
return matcher.start();//返回的是开始的位置,找到的第七个双引号的开始的位置
}
/**
* reduce处理,归并操作 <浏览器的名称,1>
* */
public static class MyReduce extends Reducer<Text,LongWritable,Text,LongWritable> {
@Override //下面是迭代的lingwritable集合
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long sum=0;
for (LongWritable value:
values){
//求key出现次数的总和
sum+=value.get();//得到value的值 <cat,1>==>1
}
//把结果输出
context.write(key,new LongWritable(sum));
}
}
/**
* 主方法
* Drive,封装了MapReduce作业的所有信息
* */
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//创建一个连接configuration
Configuration configuration = new Configuration();
//准备工作,清理已经存在的文件
Path outputpath=new Path(args[1]);
FileSystem fileSystem=FileSystem.get(configuration);
if (fileSystem.exists(outputpath)){
fileSystem.delete(outputpath,true);
System.out.println("输出目录存在,但是已经被删除了");
}
//创建一个job
Job job=Job.getInstance(configuration,"LogApp");
//设置处理那个类 告诉job要处理哪个类
job.setJarByClass(LogApp.class);
//作业要处理数据的路径
FileInputFormat.setInputPaths(job, new Path(args[0]));//路径是放到平台的,所以是通过传入参数形式
//map处理的相关参数
job.setMapperClass(MyMapper.class); //找到自己处理的类
job.setMapOutputKeyClass(Text.class);//设置输出的key类型
job.setMapOutputValueClass(LongWritable.class); //设置输出的value
//设置reduce相关参数
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//作业处理完后,数据输出的路径,
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//程序结束后,释放资源
System.exit(job.waitForCompletion(true)?0:1); //wait有两个异长,classnotfound和interrupt
}
}