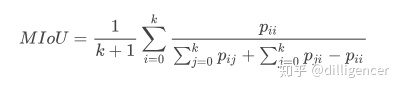前言
最近在面试,每天会被考到很多知识点,这些知识点有些我已经看了十几遍,还是会反应慢或者记不住。回想我在学习过程中,也是学了忘忘了学,没有重复个几十遍根本难以形成永久记忆。这次我复习和整理面试知识点的时候决定把CNN里面的关键创新点、容易疏忽的点都记录下来,方便快速查找回顾,于是就有了这篇像词典一样的永久更新的文章。
一、轻量化网络
| 网络名称 | 记忆点 | 备注 |
| MobileNetV1 | 深度可分离卷积替换传统卷积 | 计算量和参数量下降为原来的1/Dk^2(Dk为卷积核kernel size,一般为3,所以计算量约为1/9) |
| 深度卷积的激活函数是Relu6 | 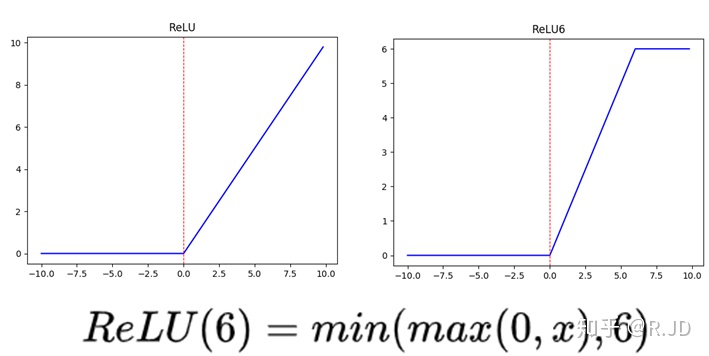 |
|
| 下采样是通过3x3的深度卷积 | stride=2 | |
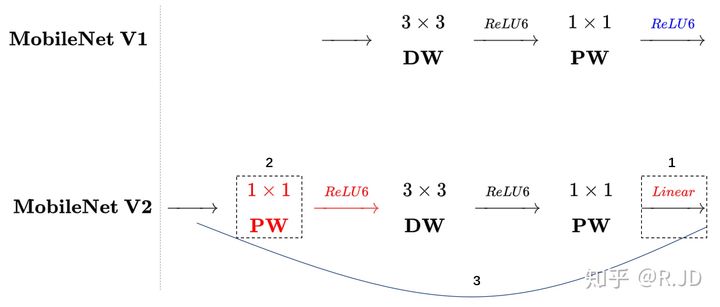
| MobileNetV2 | Linear Bottelneck | 最后的Relu6换成了Linear
|
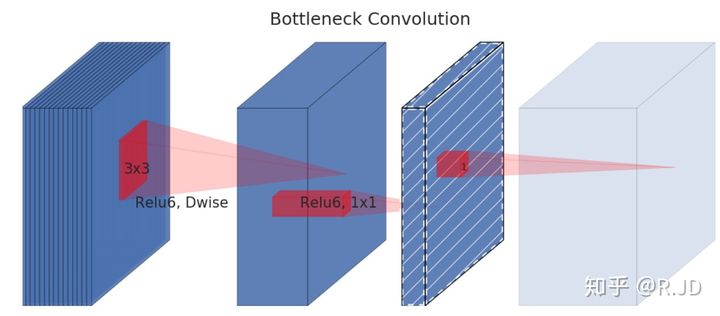
| Inverted Residuals | 1.点卷积扩充通道,再做深度卷积,再通过点卷积压缩通道。这样的好处是3x3卷积在更深的通道上可以提取到更丰富的特征。 2.对于stride=1的Block加入Residual结构,stride=2的resoution变了,因此不添加。
|
|
| MobileNetV3 | NAS | 网络的架构基于NAS实现的MnasNet platform-aware NAS + NetAdapt |
| SE | squeeze and excitation 注意力机制 | |
| 模型的后半段使用h-swish | swish(x) :f(x) = x * sigmoid(βx) h-swish是因为sigmoid函数在端上计算耗时而提出的改进方案。
|
|
| 末端调整 | Avg提前,好处是计算量减小。 |
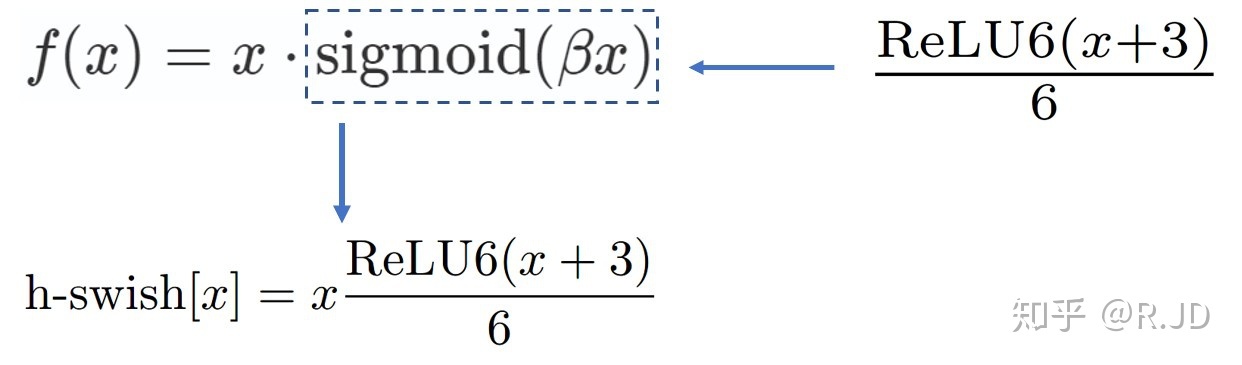
二.基础知识
2.1 BatchNorm/LayerNorm/InstanceNorm/GroupNorm
| 基础知识点 | 记忆点 | 备注 |
| Batch Norm | 达到的效果 | BatchNorm就是在深度神经网络训练过程中使得每一层神经网络的输入保持相同分布。 |
| 出发点 | 解决covariate shift:如果ML系统实例集合<X,Y>中的输入值X的分布老是变,这不符合IID假设,网络模型很难稳定的学规律。 问题:分布变化=>非线性输出向两端移动=>梯度消失=>网络收敛慢 解决:BN=>将隐藏层的输入拉回到(0,1)正态分布=>使激活值落在非线性区域=>使得梯度变大=>加快网络收敛 |
|
| 保障非线性 | BN为了保证非线性的获得,对变换后的满足均值为0方差为1的x又进行了scale加上shift操作(y=scale*x+shift) 核心思想应该是想找到一个线性和非线性的较好平衡点,既能享受非线性的较强表达能力的好处,又避免太靠非线性区两头使得网络收敛速度太慢。 |
|
| 推理时的参数 | 推理的参数scale和shift是在训练的时候记住每个batch内的参数,然后求出平均值和方差的期望,这样在全局上估计的这组参数更加准确。 | |
| 正则化作用 | 在BN层中,每个batch计算得到的均值和标准差是对于全局均值和标准差的近似估计,这为我们最优解的搜索引入了随机性,从而起到了正则化的作用。 | |
| BN的缺陷 | 带有BN层的网络错误率会随着batch_size的减小而迅速增大,当我们硬件条件受限不得不使用较小的batch_size时,网络的效果会大打折扣。 | |
| BN/LN/IN/GN | 示意图 | 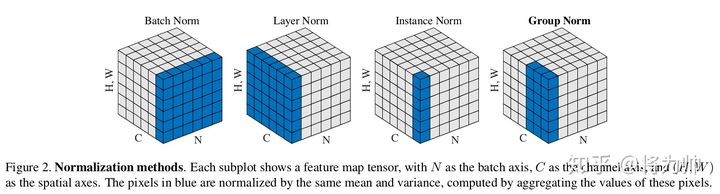 |
| 均值方差的作用位置 |
|
|
| 相比BN为什么好? | LN/IN和GN都没有对batch作平均,所以当batch变化时,网络的错误率不会有明显变化 | |
| 经验表现 | LN和IN 在时间序列模型(RNN/LSTM)和生成模型(GAN)上有很好的效果,而GN在视觉模型上表现更好。 |
2.2 关于dropout
| 基础知识点 | 记忆点 | 备注 |
| dropout | 概念 | 在每个训练批次中,神经元的激活值以一定的概率p停止工作 |
| 目的 | 起到正则化作用,可以使模型泛化性更强,因为模型不会太依赖某些局部的特征。 | |
| 示意图 |
面试问到是冻结权重还是冻结神经元? 答冻结神经元。 |
|
| 为什么缓解过拟合? 为什么有人说dropout类似model ensemble的效果? |
|

三.常见loss函数
| loss函数 | 记忆点 | 备注 |
| CE | 交叉熵的推理 | 1.信息量的表示
2.熵是信息量的期望
3.相对熵(KL散度)表示两个分布的差异
4.交叉熵是相对熵的数学变形
前面是p(x)的熵,是一个常量。后面就是交叉熵。
|
| loss的形式 |  |
|
| 分类loss为什么prefer交叉熵than MSE? | MSE不能保证误差越大,梯度越大,学习越快。而交叉熵可以,因此收敛更好更快。 | |
| Focal | 解决的问题 | 1.解决类别不平衡 2.难易样本分布不平衡 |
| loss的形式 | 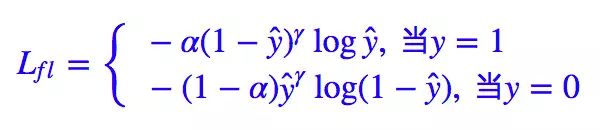 |
|
| loss的参数 | 基于交叉熵演变而来。 γ用来调节样本难易程度,一般取2。γ提升了预测与GT差距大的样本对loss的贡献比(困难样本)。 α用来调节样本类别的比例,默认α=0.25,将前景的loss放大而背景的loss缩小。 |
|
| Dice | 解决的问题 | 语义分割中正负样本不平衡 |
| loss的形式 | Dice系数:
Dice loss:
Laplace Smoothing:
|
|
| Dice的优势劣势 |
|
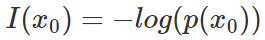
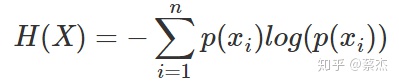
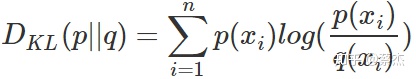
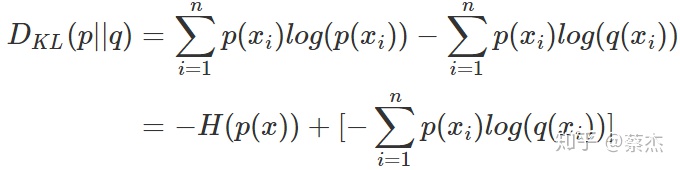

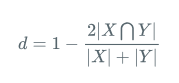
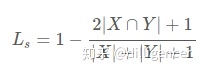
四.常见衡量指标
| 指标名称 | 记忆点 | 备注 |
| MAP(目标检测) | TP、TN、FP、FN | 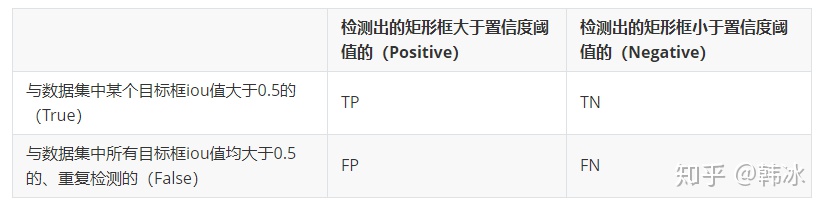 |
| Precision & Recall | Precision = TP / (TP + FP) Recall = TP / (TP + FN) | |
| AP | 按照模型给出的置信度,对每个类的所有预测框进行排序: 逐个计算Precision 和 Recall,绘制PR曲线,AP就是PR曲线上的Precision值求均值。 实际应用中就会对PR曲线最做平滑:
|
|
| MAP | MAP就是对所有类的AP做平均值。 | |
| MIOU(语义分割) | IOU | IOU的定义:计算真实值和预测值两个集合的交集和并集之比 IOU=TP/(FP+FN+TP) |
| MIOU | 对于不同类别的IOU求平均值 | |
| MIOU的数学表达 |
pij表示真实值为i,被预测为j的数量, K+1是类别个数(包含空类)。pii是真正的数量。pij、pji则分别表示假正和假负。 |