kafka:消息引擎系统
Kafka 的标准定位是分布式流式处理平台(Kafka 0.10.0.0 版本正式推 出了 Kafka Streams ,即流式处理组件 。自 此Kafka 正式成为了 个流式处理框架,而不仅仅是 消息引擎了。 )
消息引擎系统的两个重要因素:消息设计 + 传输协议设计
消息设计:即结构化消息,如soap的xml格式,webservcie的json,kafka采用二进制;
传输协议设计:主流的有AMQP,webservice,RPC中有阿里的dubbo,kafka自己设计了一套二进制消息传输协议;
消息引擎范型:消息队列模型(queue\sender\receiver\p2p)、发布/订阅模型(pub/sub/topic)
kafka的设计理念:
吞吐量/延时(高并发性);
消息持久化(高可靠性);
负载均衡和故障转移(高可用性);
伸缩性;
一、kafka的高吞吐量、低延时
采用了追加写入消息的方式,即只能在日志文件末尾追加写入的新消息,且不允许修改已写入的消息,因此它属于典型的磁盘顺序访问型操作,在实际操作中可以很轻松的做到每秒写入几万甚至几十万条消息。

如果我
们监控
一个经过良好调优的
Kafka 生产集群便
可以发现,即使是那些有负载的
Kafka 服务器,其磁盘的读操作也很少,这是因为大部分的消 息读取操作会直接命中页缓存。
二、持久化:
普通的系统在实现持久化时可能会先尽量 使用内存,当内存资源耗尽时,再
次性地把数据“刷盘”;而
Kafka
则反其道而行之,
有数据都会立即被写入文件系统的持久化日志中,之后
Kafka 服务器才会返回结果给客户端通 知它们消息已被成功写入。这样做既实时保存了数据,又减少了
Kafka 程序对于内存的消耗, 从而将节省出的内存留给页缓存使用,更进一步地提升了整体性能
三、
负载均衡和故障转移
Kafka
实现负载均衡实际上是通过智能化的分区领导者选举(
partition
leader
election
)
选举算法,可以在集群的所有机器上以均
会分散各个
partition
leader
,从而整体上实现了负载均衡;
Kafka
服务器支持故障转移的方式就是使用会话机制
。每
Kafka 服务器启动后会以会话的形式把自己注册到
Zoo
Keeper
服务器上
。一旦该
服务器运转出现问题,与 ZooKeeper
的会话便不能维持从而超时失效,此时
Kafka 集群
会选举出另一台服务器来完全代替这台服务器继续提供服务。
四、伸缩性
伸缩性表示向分布式系统中增加额外的计算资源(比如
CPU 、内存、存储或带宽)时吞吐量提升的能力,阻碍线性扩容的
个很常见的因素就是状态的保存。
每台
Kafka
务器上的状态统一交由
Zoo
Keeper 保管
扩展
Kafka
集群也只需要
一步
:启动新的
Kafka
服务器即可
。当
然这里需要言明的是,在 Kafka 服务器上并不是所有状态都不保存,它只保存了很轻量级的内部状态,因此在整个集群 间维护状态
致性的代价是很低的。
四个基本概念:消息、topic、partition、replica
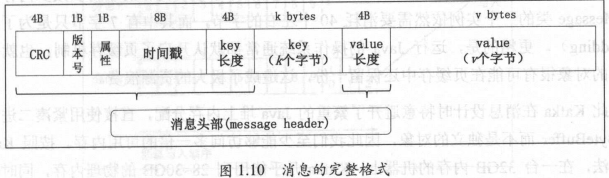
1、消息(Kafka 使用紧凑的二进制字节数组来保存上面这些字段, 也就是说没有任何多余的比特位浪费)
2、topic(主题,代表一类消息)
topic-partition-message
三级结构来分散负载
3、partition(分区)
partition 实际上并没有太多的业务含义,它的引入就是单纯地为 了提升系统的吞吐量,因此在创建
Kafka
topic 的时候可以根据集群实际配置设置具体的 partition
数,
实现整
体性能的
最大。

Kafka
中的 条消息其实就是一个 <topic,partition,offset>
三元组(阳
ple
),通过该元组值我们可以在
Kafka
集群中找到唯
对应的
那条消息。
4、replica(副本)
它们存在的唯一目的就是防止数据丢失
副本分为两类:领导者副本(leader replica) 追随者副本(follower replica)
follower replica是不能提供服务给客户端的,也就是说不负责响应客户端发过来的消息写入与消息消费请求,它只是被动的向领导者副本获取数据,如果leader replica所在的broker宕机,kafka会从剩下的replica中选举新的leader继续提供服务

ISR:in-sync-replica ,就是一组与leader replica保持同步的replica集合。

因为各种原因,一小部分replica开始落后于leader replica的进度,当滞后到一定程度时,kafka会将其踢出ISR,相反地,当这些replica重新追上leader replica的进度时,那么leader replica又会将其加入到ISR中。这一切都是自动维护的
客户端:producer 、consumer
服务端:broker