进入容器
docker exec -it mongo /bin/sh
导出csv
mongoexport -u root -p root -d iot -c sensorData --type=csv -f deviceId,id,name,data,unitname,ctime -q ‘{“id”:8022}’ -o /home/iot.csv
导出csv带过滤条件
mongoexport -u root -p root -d iot -c sensorData --type=csv -f deviceId,id,name,data,unitname,ctime -q ‘{“id”:8022}’ -o /home/iot.csv
从容器复制出来
docker cp f857853678a0:/home/iot.csv /root/
mongoexport 参数:
-h:指明数据库宿主机的IP
-u:指明数据库的用户名
-p:指明数据库的密码
–port:指明端口号
-d:指明数据库的名字
-c:指明collection的名字
–type:指明要导入的文件格式
-f:指明要导出那些列
-q:指明导出数据的过滤条件
-o:指明要导出的文件名
–authenticationDatabase:指明保存用户凭证的数据库
–authenticationMechanism:指明身份验证机制
excel时间加上8小时 公式:=B1+TIME(8,0,0) 设置单元格格式:yyyy/m/d h:mm:ss
CSV中文乱码:UE打开UTF-8,另存为GBK编码,再用excel打开就正常了。
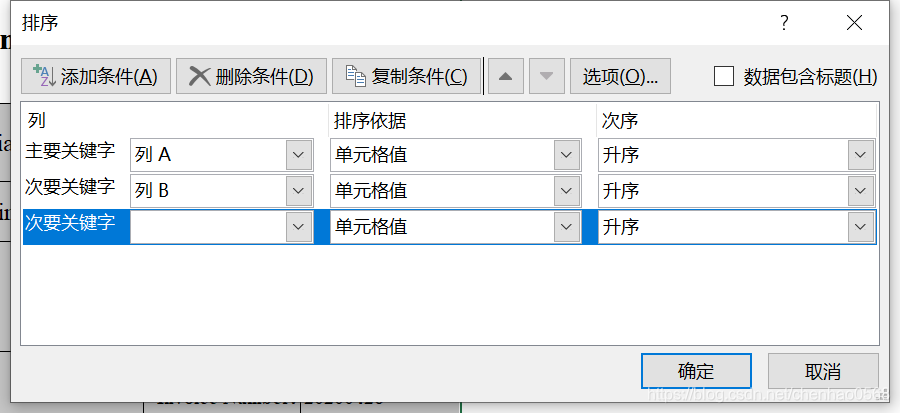
excel多条件排序:选自定义排序,如下
不如直接用NoSQLBooster for MongoDB客户端方便,一下就出来了。但试用过期就要钱了。
import * as path from "path";
import * as fs from "fs";
const promisify = require("bluebird").promisify;
const appendFileAsync = promisify(fs.appendFile);
const BATCH_SIZE = 2000;
const connection = "123.123.123.123";//
const db = "iot";
let targetPath = "C:\\Users\\wuqimei\\Desktop\\chenhao";
if (!fs.existsSync(targetPath))
require("mkdirp").sync(targetPath);
let exportCollections = [
{
collection: "sensorData", query: {}, projection: {}, sort: {}, skip: 0, limit: 0, filename: "iot.sensorData.csv", delimiter: ",", fields: [
"id",
"name",
"pid",
"deviceId",
"data",
"unitname",
"ctime"
]
}
];
let totalDocs = 0;
let collectionResult = {};//collectionResult:{[name:string]:number}
function exportCollection(collectionParams) {
let { collection, filename, query, projection, sort, skip, limit, fields, delimiter } = collectionParams;
let filepath = path.resolve(targetPath, mb.sanitizeFile(filename || (db + "." + collection + ".csv")));
console.log(`export docs from ${connection}:${db}:${collection} to ${filepath} start...`);
if (fs.existsSync(filepath))
fs.unlinkSync(filepath);
if (!_.isEmpty(fields)) {
projection = {};
fields.forEach(field => {
projection[field] = 1;
})
} else {
fields = mb.tryGetFields({ connection, db, collection });
}
collectionResult[collection] = 0;
let cursor = mb.getCursorFromCollection({ connection, db, collection, sort, skip, limit, query, projection });
let isFirstRead = true;
const totalCount = cursor.size ? cursor.size() : cursor.count();
const appendFilePromises = [];
await(mb.batchReadFromCursor(cursor, BATCH_SIZE, (docs) => {
return async(() => {
let readLength = docs.length;
if (!readLength) {
return;
}
let csvContent = mb.docsToCSV({ docs, fields, delimiter, withColumnTitle: isFirstRead });
isFirstRead = false;
appendFilePromises.push(appendFileAsync(filepath, csvContent));
collectionResult[collection] += readLength;
const percent = (collectionResult[collection] / totalCount * 100).toFixed(1);
console.log(`${percent}% ${collectionResult[collection]}/${totalCount} docs exported to "${path.basename(filepath)}".`);
totalDocs += docs.length;
})();
}));
await(Promise.all(appendFilePromises));
sleep(100);
console.log(`export ${collectionResult[collection]} docs from ${connection}:${db}:${collection} to ${filepath} finished.`);
}
exportCollections.forEach(it => exportCollection(it));
_.delay(() => mb.openFolder(targetPath), 1000);
if (exportCollections.length > 1)
console.log(`Total ${totalDocs} document(s) of ${exportCollections.length} collections successfully exported.`, collectionResult);