原理
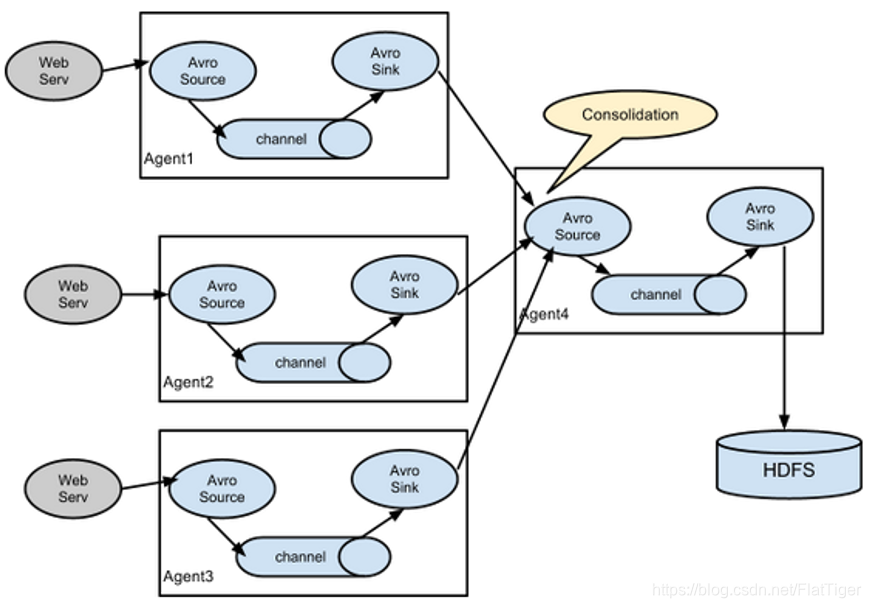
在每个服务器部署flume采集日志,由这些flume传输数据到统一收集日志的flume节点,最后由此flume将数据写入指定位置。
案例
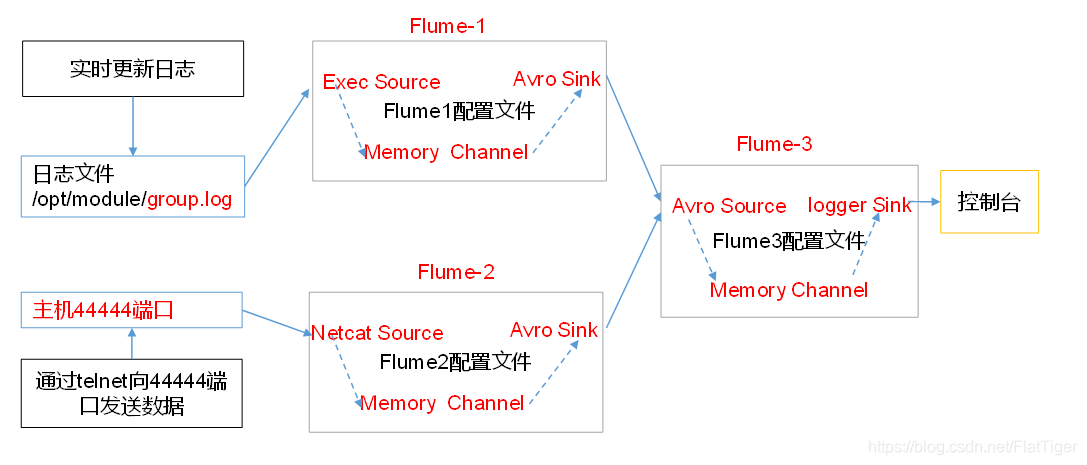
hadoop01上的Flume-1监控文件/opt/module/group.log,
hadoop02上的Flume-2监控某一个端口的数据流,
Flume-1与Flume-2将数据发送给hadoop03上的Flume-3,Flume-3将最终数据打印到控制台。
实现
# agent1
# 定义sources、channels、sinks
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# 配置source
a1.sources.r1.type = TAILDIR
# 日志索引记录
a1.sources.r1.positionFile = /opt/module/flume/inode/taildir_position.json
# 文件组
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /opt/module/group.log
# 配置channel
a1.channels.c1.type = memory
# 配置sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop03
a1.sinks.k1.port = 6666
# 配置source、channel、sink关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
# agent2
# 定义sources、channels、sinks
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# 配置source
a1.sources.r1.type = netcat
a1.sources.r1.bind = hadoop02
a1.sources.r1.port = 44444
# channel
a1.channels.c1.type = memory
# sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop03
a1.sinks.k1.port = 6666
# 配置关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
# agent3
# 定义sources、channels、sinks
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# 配置source
a1.sources.r1.type = avro
a1.sources.r1.bind = hadoop03
a1.sources.r1.port = 6666
# channel
a1.channels.c1.type = memory
# sink
a1.sinks.k1.type = logger
# 配置关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
先启动数据接收端,再启动数据发送端。