kmp算法解决的是两个字符串的匹配问题
及str1里面包含str2子串,返回str1重复的第一个数的下标
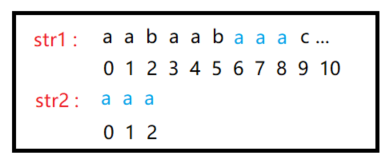
以此为例子
先考虑暴力方法
枚举str1的每个字符来做开头 ,在str[i]==str[j]的情况下, k( i ) 和 j 向后移动,受str2遍历结束的时候 , 输出 i结束 ,如果不同 则 i 向下移动一个位置 重新遍历 str2
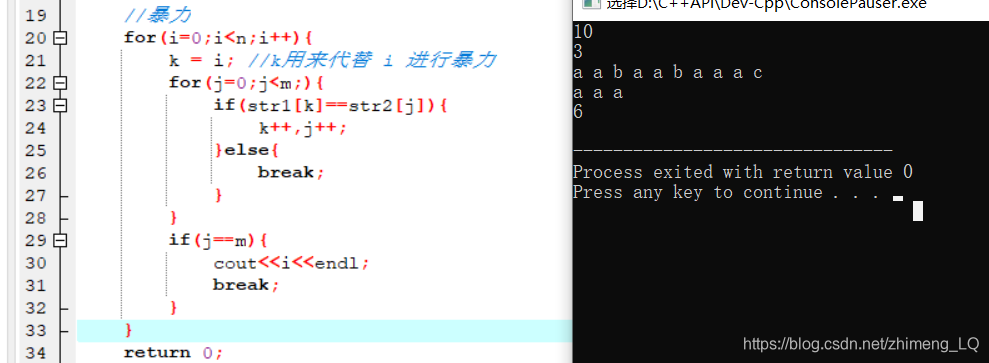
这样做的时间复杂度很明显是o(n2)的,当n的量级达到105时,就会超时。
所以我们要学习一种新的算法 KMP(看毛片算法)
KMP算法
该算法的思想就是省去不必要位置i的循环。
具体实现方法就是需要一个额外的数组next[str2的长度] , next[i]来记录0 ~ i-1最长相等前缀-后缀长度,且不包含str本身 。
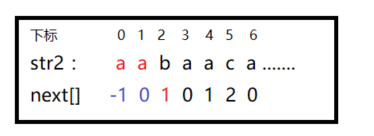
- 当下标为0时,由于
next[i]的含义是不包含i的…长度,所以前面没有数字,标记为1。 - 当下标为1时,由于
next[i]的含义是不包含i的…长度, 前面只有一个数字,因为不可以包含str本身,所以长度为1。 以后可以默认next[0]=-1,next[1]=0; - 当下标为2时, 从
0-1寻找最长相等前后缀长度,因为str[0]==str[1],所以长度为1。 为什么不为2?,因为要求的最后一句还有不包含str本身 这里是str不是说整个字符串,而是0~i-1的范围 - 当下标为3时, 从
0~2查找最长…长度。str[0]!=str[2],所以长度为0. - 后面以此类推,所以我们每次只需要从2开始计算就行。
正片开始
#include <iostream>
using namespace std;
//求str1中str2的子串第一位
string str1,str2;
void getnextarr(int nexts[],int len){
nexts[0] = -1; //默认0和1的值
nexts[1] = 0;
int i=2; //从2开始
int cn=0; //当前哪个位置的字符在和i比较
while(i<len){
if(str2[i-1]==str2[cn]){
nexts[i++] = ++cn; //相同的话 nexts得到值是上一项+1 cn和i往后移一位
}else if(cn > 0){
cn = nexts[cn]; // 不相等,且cn不是开头 就需要cn往前移
}else{
nexts[i++] = 0; // 都不匹配
}
}
}
int kmp(){
int len1 = str1.length();
int len2 = str2.length();
if(len1==0||len2==0||len2<1||len1<len2){
return -1;
}
//aabaabaaac
//aaa
int x=0,y=0;
int nexts[len2]; //新建nexts数组
getnextarr(nexts,len2);
while(x<len1&&y<len2){
if(str1[x] == str2[y]){
//相等 俩字符串一起向前移
x++,y++;
}else if(nexts[y] == -1){
// 不等 并且str2跳转到第一位
x++;
}else{
// kmp优化部分
y = nexts[y];
}
}
return y==len2 ? x-y : -1; //三目运算符
}
int main(){
cin>>str1>>str2;
cout<<kmp()<<endl;
return 0;
}
kmp时间复杂度低在哪?
由于nexts数组的存在,在遇到不匹配的情况时,我们可以舍弃str1的前面一段,从str2的另一个开头开始。看下例子
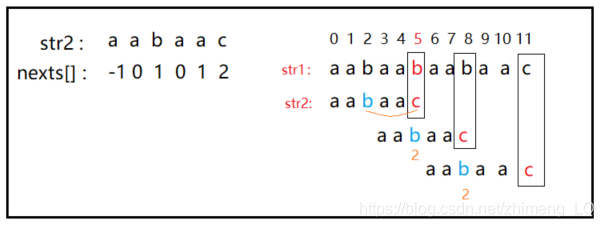
当str1匹配到下标为5时,与str2的最后一位不同,进入kmp精髓,因为nexts[5] = 2 , 所以j跳转到 2 位置上,i位置不变,让str2[j]与str1[i]比较。
此时默认省略str1的前三个
kmp优化在哪个地方
- str1某个位置失败之后 可以跳过多个位置
- str2的前后缀相同 只从可能不一样的地方开始(后缀某处不同 从前缀某处开始)