4.1 项目演示
学习目标
- 目标
- 了解项目的演示结果
- 应用
- 无
4.1.1 项目演示
项目已经部署上线
- Web端演示
- 百度机器人端识别演示
4.1.2 项目结构

4.1.3 项目知识点
- 神经网络
- 卷积网络
-
TensorFlowAPI操作
-
RCNN以及相关算法
- YOLO与SSD
-
算法接口介绍
-
数据集标记格式
-
数据集存储与读取
-
数据接口实现
- 模型接口实现
- 训练、设备部署逻辑实现
- 测试接口
- TensorFlow serving部署模型
- Web server+TensorFlow serving Client
================================================================
4.2 目标检测任务描述
学习目标
- 目标
- 了解目标检测算法分类
- 知道目标检测的常见指标IoU
- 了解目标定位的简单实现方式
-
应用
- 无
4.2.1 目标检测算法分类
-
两步走的目标检测:先进行区域推荐,而后进行目标分类
扫描二维码关注公众号,回复: 12682426 查看本文章
- 代表:R-CNN、SPP-net、Fast R-CNN、Faster R-CNN
-
端到端的目标检测:采用一个网络一步到位
- 代表:YOLO、SSD

4.2.2 目标检测的任务
4.2.2.1 分类原理回顾
先来回归下分类的原理,这是一个常见的CNN组成图,输入一张图片,经过其中卷积、激活、池化相关层,最后加入全连接层达到分类概率的效果

- 分类的损失与优化
在训练的时候需要计算每个样本的损失,那么CNN做分类的时候使用softmax函数计算结果,损失为交叉熵损失

- 常见CNN模型

对于目标检测来说不仅仅是分类这样简单的一个图片输出一个结果,而且还需要输出图片中目标的位置信息,所以从分类到检测,如下图标记了过程:
- 分类

- 目标检测
4.2.2.2 检测的任务
- 分类:
- N个类别
- 输入:图片
- 输出:类别标签
- 评估指标:Accuracy

定位:
- N个类别
- 输入:图片
- 输出:物体的位置坐标
- 主要评估指标:IOU

其中我们得出来的(x,y,w,h)有一个专业的名词,叫做bounding box(bbox).
- 物体位置:
- x, y, w,h:x,y物体的中心点位置,以及中心点距离物体两边的长宽
- xmin, ymin, xmax, ymax:物体位置的左上角、右下角坐标
4.2.3 目标定位的简单实现思路
在分类的时候我们直接输出各个类别的概率,如果再加上定位的话,我们可以考虑在网络的最后输出加上位置信息。
4.2.3.1 回归位置
增加一个全连接层,即为FC1、FC2
-
FC1:作为类别的输出
-
FC2:作为这个物体位置数值的输出

假设有10个类别,输出[p1,p2,p3,...,p10],然后输出这一个对象的四个位置信息[x,y,w,h]。同理知道要网络输出什么,如果衡量整个网络的损失
- 对于分类的概率,还是使用交叉熵损失
- 位置信息具体的数值,可使用MSE均方误差损失(L2损失)
如下图所示

4.2.4.1 两种Bounding box名称
在目标检测当中,对bbox主要由两种类别。
- Ground-truth bounding box:图片当中真实标记的框
- Predicted bounding box:预测的时候标记的框

一般在目标检测当中,我们预测的框有可能很多个,真实框GT也有很多个。
4.2.5 总结
- 掌握目标检测的算法分类
- 掌握分类,分类与定位,目标检测的区别
- 掌握分类与定位的简单方法、损失衡量
===================================================
4.3 R-CNN
学习目标
-
目标
- 了解Overfeat模型的移动窗口方法
- 说明R-CNN的完整结构过程
- 了解选择性搜索
- 了解Crop+Warp的作用
- 知道NMS的过程以及作用
- 了解候选区域修正过程
- 说明R-CNN的训练过程
- 说明R-CNN的缺点
-
应用
- 无
对于一张图片当中多个目标,多个类别的时候。前面的输出结果是不定的,有可能是以下有四个类别输出这种情况。或者N个结果,这样的话,网络模型输出结构不定

所以需要一些他的方法解决目标检测(多个目标)的问题,试图将一个检测问题简化成分类问题
4.3.1 目标检测-Overfeat模型
4.3.1.1 滑动窗口
- 目标检测的暴力方法是从左到右、从上到下滑动窗口,利用分类识别目标。
- 为了在不同观察距离处检测不同的目标类型,我们使用不同大小和宽高比的窗口。如下图所示:

注:这样就变成每张子图片输出类别以及位置,变成分类问题。
但是滑动窗口需要初始设定一个固定大小的窗口,这就遇到了一个问题,有些物体适应的框不一样
- 所以需要提前设定K个窗口,每个窗口滑动提取M个,总共K x M 个图片,通常会直接将图像变形转换成固定大小的图像,变形图像块被输入 CNN 分类器中,提取特征后,我们使用一些分类器识别类别和该边界框的另一个线性回归器。

4.3.1.2 Overfeat模型总结
这种方法类似一种暴力穷举的方式,会消耗大量的计算力量,并且由于窗口大小问题可能会造成效果不准确
。但是提供了一种解决目标检测问题的思路
4.3.2 目标检测-R-CNN模型
在CVPR 2014年中Ross Girshick提出R-CNN。
4.3.2.1 完整R-CNN结构
不使用暴力方法,而是用候选区域方法(region proposal method),创建目标检测的区域改变了图像领域实现物体检测的模型思路,R-CNN是以深度神经网络为基础的物体检测的模型 ,R-CNN在当时以优异的性能令世人瞩目,以R-CNN为基点,后续的SPPNet、Fast R-CNN、Faster R-CNN模型都是照着这个物体检测思路。
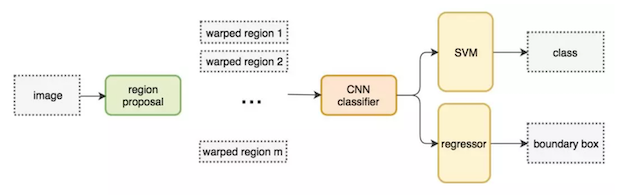
- 步骤(以AlexNet网络为基准)
- 1.找出图片中可能存在目标的侯选区域region proposal
- 2.将候选区域调整为了适应AlexNet网络的输入图像的大小227×227,通过CNN对候选区域提取特征向量,2000个建议框的CNN特征组合成网络AlexNet最终输出:2000×4096维矩阵
- 3.将2000×4096维特征经过SVM分类器(20种分类,SVM是二分类器,则有20个SVM),获得2000×20种类别矩阵
- 4.分别对2000×20维矩阵中进行非极大值抑制(NMS:non-maximum suppression)剔除重叠建议框,得到与目标物体最高的一些建议框
- 5.修正bbox,对bbox做回归微调
4.3.2.2 候选区域(Region of Interest)得出(了解)

选择性搜索(SelectiveSearch,SS)中,首先将每个像素作为一组。然后,计算每一组的纹理,并将两个最接近的组结合起来。但是为了避免单个区域吞噬其他区域,我们首先对较小的组进行分组。我们继续合并区域,直到所有区域都结合在一起。下图第一行展示了如何使区域增长,第二行中的蓝色矩形代表合并过程中所有可能的 ROI。

SelectiveSearch在一张图片上提取出来约2000个侯选区域,需要注意的是这些候选区域的长宽不固定。 而使用CNN提取候选区域的特征向量,需要接受固定长度的输入,所以需要对候选区域做一些尺寸上的修改。
4.3.2.3 CNN网络提取特征
在侯选区域的基础上提取出更高级、更抽象的特征,这些高级特征是作为下一步的分类器、回归的输入数据。

提取的这些特征将会保存在磁盘当中(这些提取的特征才是真正的要训练的数据)
4.3.2.4 特征向量训练分类器SVM
- 1、假设一张图片的2000个侯选区域,那么提取出来的就是2000 x 4096这样的特征向量(R-CNN当中默认CNN层输出4096特征向量)。
- 2、R-CNN选用SVM进行二分类。假设检测20个类别,那么会提供20个不同类别的SVM分类器,每个分类器都会对2000个候选区域的特征向量分别判断一次,这样得出[2000, 20]的得分矩阵,如下图所示

- 每个SVM分类器做的事情
- 判断2000个候选区域是某类别,还是背景
4.3.2.5 非最大抑制(NMS)
- 目的
- 筛选候选区域,目标是一个物体只保留一个最优的框,来抑制那些冗余的候选框
- 迭代过程
- 1、对于所有的2000个候选区域得分进行概率筛选,0.5
- 2、剩余的候选框
- 假设图片真实物体个数为2(N),筛选之后候选框为5(P),计算N中每个物体位置与所有P的交并比IoU计算,得到P中每个候选框对应IoU最高的N中一个
- 如下图,A、C候选框对应左边车辆,B、D、E对应右边车辆

假设现在滑动窗口有:A、B、C、D、E 5个候选框,
- 第一轮:对于右边车辆,假设B是得分最高的,与B的IoU>0.5删除。现在与B计算IoU,DE结果>0.5,剔除DE,B作为一个预测结果
- 第二轮:对于左边车辆,AC中,A的得分最高,与A计算IoU,C的结果>0.5,剔除C,A作为一个结果
最终结果为在这个5个中检测出了两个目标为A和B
SS算法得到的物体位置已经固定了,但是我们筛选出的位置不一定真的就特别准确,需要对A和B进行最后的修正
4.3.2.6 修正候选区域
那么通过非最大一直筛选出来的候选框不一定就非常准确怎么办?R-CNN提供了这样的方法,建立一个bbox regressor
- 回归用于修正筛选后的候选区域,使之回归于ground-truth,默认认为这两个框之间是线性关系,因为在最后筛选出来的候选区域和ground-truth很接近了
修正过程(线性回归)


4.3.3 检测的评价指标
4.3.3.1 IoU交并比
| 任务 | description | 输入 | 输出 | 评价标准 |
|---|---|---|---|---|
| Detection and Localization (检测和定位) | 在输入图片中找出存在的物体类别和位置(可能存在多种物体) | 图片(image ) | 类别标签(categories)和 位置(bbox(x,y,w,h)) | IoU (Intersection over Union) |
- IoU(交并比)
- 两个区域的重叠程度overlap:侯选区域和标定区域的IoU值

- 通常Correct: 类别正确 且 IoU > 0.5
4.3.3.1 平均精确率(mean average precision)map
训练样本的标记:候选框(如RCNN2000个)标记
- 1.每个ground-truth box有着最高的IoU的anchor标记为正样本
-
2.剩下的anchor/anchors与任何ground-truth box的IoU大于0.7记为正样本,IoU小于0.3,记为负样本
-
定义:多个分类任务的AP的平均值
- mAP = 所有类别的AP之和 / 类别的总个数
- 注:
PR曲线,而AP(average precision)就是这个曲线下的面积(ROC与AUC)
-
方法步骤:
- 1、对于其中一个类别C,首先将算法输出的所有C类别的预测框,按预测的分数confidence排序
- RCNN中就是SVM的输出分数
- 2、设定不同的k值,选择top k个预测框,计算FP和TP,计算Precision和AP
- 3、将得到的N个类别的AP取平均,即得到AP;AP是针对单一类别的,mAP是将所有类别的AP求和,再取平均:
- 1、对于其中一个类别C,首先将算法输出的所有C类别的预测框,按预测的分数confidence排序
-
首先回顾精确率与召回率
- 左边一整个矩形中的数表示ground truth之中为1的(即为正确的)数据
- 右边一整个矩形中的数表示ground truth之中为0的数据
- 精度precision的计算是用 检测正确的数据个数/总的检测个数
- 召回率recall的计算是用 检测正确的数据个数/ground truth之中所有正数据个数。


4.3.4 R-CNN总结
4.3.4.1 流程总结





- 表现
- 在VOC2007数据集上的平均精度map达到66%
4.3.4.2 缺点
-
1、训练阶段多:步骤繁琐: 微调网络+训练SVM+训练边框回归器。
-
2、训练耗时:占用磁盘空间大:5000张图像产生几百G的特征文件。(VOC数据集的检测结果,因为SVM的存在)
-
3、处理速度慢: 使用GPU, VGG16模型处理一张图像需要47s。
- 4、图片形状变化:候选区域要经过crop/warp进行固定大小,无法保证图片不变形
4.3.6 总结
- 掌握Overfeat模型思路
- 滑动窗口
- 掌握R-CNN的流程
- 了解R-CNN的缺点
- 训练耗时
- 训练阶段多
- 处理速度慢
- 图片变形问题
4.3.7 问题?
1、NMS的过程描述?以及作用?
2、请说明候选框的修正过程?
3、IoU以及map计算过程
4.3.8 改进-SPPNet
学习目标
- 目标
- 说明SPPNet的特点
- 说明SPP层的作用
- 应用
- 无
R-CNN的速度慢在哪?

每个候选区域都进行了卷积操作提取特征。
3.3.1 SPPNet
SPPNet主要存在两点改进地方,提出了SPP层
- 减少卷积计算

| R-CNN模型 | SPPNet模型 |
|---|---|
| 1、R-CNN是让每个候选区域经过crop/wrap等操作变换成固定大小的图像 2、固定大小的图像塞给CNN 传给后面的层做训练回归分类操作 | 1、SPPNet把全图塞给CNN得到全图的feature map 2、让SS得到候选区域直接映射特征向量中对应位置 3、映射过来的特征向量,经过SPP层(空间金字塔变换层),S输出固定大小的特征向量给FC层 |
3.3.1.1 映射
原始图片经过CNN变成了feature map,原始图片通过选择性搜索(SS)得到了候选区域(Region of Interest),现在需要将基于原始图片的候选区域映射到feature map中的特征向量。映射过程图参考如下:

整个映射过程有具体的公式,如下
假设(x′,y′)(x′,y′)表示特征图上的坐标点,坐标点(x,y)表示原输入图片上的点,那么它们之间有如下转换关系,这种映射关心与网络结构有关:(x,y)=(S∗x′,S∗y′),即
- 左上角的点:
- x′=[x/S]+1
- 右下角的点:
- x′=[x/S]−1
其中 S 就是CNN中所有的strides的乘积,包含了池化、卷积的stride。论文中使用S的计算出来为2x2x2x2=16
拓展:如果关注这个公式怎么计算出来,请参考:http://kaiminghe.com/iccv15tutorial/iccv2015_tutorial_convolutional_feature_maps_kaiminghe.pdf
3.3.1.2 spatial pyramid pooling
- 通过spatial pyramid pooling 将特征图转换成固定大小的特征向量
示例:假设原图输入是224x224,对于conv出来后的输出是13x13x256,其中某个映射的候选区域假设为:12x10x256
- spp layer会将每一个候选区域分成1x1,2x2,4x4三张子图,对每个子图的每个区域作max pooling,得出的特征再连接到一起就是(16+4+1)x256=21x256=5376结果,接着给全连接层做进一步处理,如下图:
- Spatial bins(空间盒个数):1+4+16=21

3.3.2 SPPNet总结
来看下SPPNet的完整结构

- 优点
- SPPNet在R-CNN的基础上提出了改进,通过候选区域和feature map的映射,配合SPP层的使用,从而达到了CNN层的共享计算,减少了运算时间, 后面的Fast R-CNN等也是受SPPNet的启发
- 缺点
- 训练依然过慢、效率低,特征需要写入磁盘(因为SVM的存在)
- 分阶段训练网络:选取候选区域、训练CNN、训练SVM、训练bbox回归器, SPPNet反向传播效率低
3.3.3 总结
- 掌握SPP的池化作用
- 掌握SPP的优缺点
3.3.4 问题?
1、SPPNet的映射过程描述?公式?
2、spatial pyramid pooling的过程?
3、SPPNet相对于R-CNN的改进地方?
===================================================
4.4 Fast R-CNN
学习目标
-
目标
- 了解Fast R-CNN的结构特点
- 说明RoI pooling的特点
- 了解多任务损失
-
应用
- 无
SPPNet的性能已经得到很大的改善,但是由于网络之间不统一训练,造成很大的麻烦,所以接下来的Fast R-CNN就是为了解决这样的问题
4.4.1 Fast R-CNN
改进的地方:
- 提出一个RoI pooling,然后整合整个模型,把CNN、RoIpooling、分类器、bbox回归几个模块整个一起训练

- 步骤
- 首先将整个图片输入到一个基础卷积网络,得到整张图的feature map
- 将选择性搜索算法的结果region proposal(RoI)映射到feature map中
- RoI pooling layer提取一个固定长度的特征向量,每个特征会输入到一系列全连接层,得到一个RoI特征向量(此步骤是对每一个候选区域都会进行同样的操作)
- 其中一个是传统softmax层进行分类,输出类别有K个类别加上”背景”类
- 另一个是bounding box regressor
4.4.1.1 RoI pooling
首先RoI pooling只是一个简单版本的SPP,目的是为了减少计算时间并且得出固定长度的向量。

- RoI池层使用最大池化将任何有效的RoI区域内的特征转换成具有H×W的固定空间范围的小feature map,其中H和W是超参数 它们独立于任何特定的RoI。
为什么要设计单个尺度呢?这要涉及到single scale与multi scale两者的优缺点
- single scale,直接将image定为某种scale,直接输入网络来训练即可。(Fast R-CNN)
- multi scal,也就是要生成一个金字塔
后者比前者更加准确些,没有突更多,但是第一种时间要省很多,所以实际采用的是第一个策略,因此Fast R-CNN要比SPPNet快很多也是因为这里的原因。
4.4.1.2 End-to-End model
从输入端到输出端直接用一个神经网络相连,整体优化目标函数。
接着我们来看为什么后面的整个网络能进行统一训练?
特征提取CNN的训练和SVM分类器的训练在时间上是先后顺序,两者的训练方式独立,因此SVMs的训练Loss无法更新SPP-Layer之前的卷积层参数,去掉了SVM分类这一过程,所有特征都存储在内存中,不占用硬盘空间,形成了End-to-End模型(proposal除外,end-to-end在Faster-RCNN中得以完善)
- 使用了softmax分类
4.4.2 多任务损失-Multi-task loss
两个loss,分别是:
- 对于分类loss,是一个N+1路的softmax输出,其中的N是类别个数,1是背景,使用交叉熵损失
- 对于回归loss,是一个4xN路输出的regressor,也就是说对于每个类别都会训练一个单独的regressor的意思,使用平均绝对误差(MAE)损失即L1损失

- fine-tuning训练:
- 在微调时,调整 CNN+RoI pooling+softmax
- 调整bbox regressor回归当中的参数
4.4.3 R-CNN、SPPNet、Fast R-CNN效果对比
| 参数 | R-CNN | SPPNet | Fast R-CNN |
|---|---|---|---|
| 训练时间(h) | 84 | 25 | 9.5 |
| 测试时间/图片 | 47.0s | 2.3s | 0.32s |
| mAP | 66.0 | 63.1 | 66.9 |
4.4.4 Fast R-CNN总结

- 缺点
- 使用Selective Search提取Region Proposals,没有实现真正意义上的端对端,操作也十分耗时
4.4.5 总结
- 掌握Fast R-CNN的改进
- 掌握RoI pooling的作用
- 掌握多任务损失结构
4.4.6 问题?
1、详细说明RoI pooling过程?
2、Fast R-CNN的损失是怎么样的?
=================================================================
4.5 Faster R-CNN
学习目标
-
目标
- 了解Faster R-CNN的特点
- 知道RPN的原理以及作用
-
应用
- 无
在Fast R-CNN还存在着瓶颈问题:Selective Search(选择性搜索)。要找出所有的候选框,那我们有没有一个更加高效的方法来求出这些候选框呢?
4.5.1 Faster R-CNN
在Faster R-CNN中加入一个提取边缘的神经网络,也就说找候选框的工作也交给神经网络来做了。这样,目标检测的四个基本步骤(候选区域生成,特征提取,分类,位置精修)终于被统一到一个深度网络框架之内。

Faster R-CNN可以简单地看成是区域生成网络+Fast R-CNN的模型,用区域生成网络(Region Proposal Network,简称RPN)来代替Fast R-CNN中的选择性搜索方法,结构如下:

- 1、首先向CNN网络(VGG-16)输入图片,Faster RCNN使用一组基础的conv+relu+pooling层提取feature map。该feature map被共享用于后续RPN层和全连接层。
- 2、Region Proposal Networks。RPN网络用于生成region proposals,faster rcnn中称之为anchors
- 通过softmax判断anchors属于foreground或者background
- 再利用bounding box regression修正anchors获得精确的proposals,输出其Top-N(默认为300)的区域给RoI pooling
- 生成anchors -> softmax分类器提取fg anchors -> bbox reg回归fg anchors -> Proposal Layer生成proposals
- 3、后续就是Fast RCNN操作

4.5.2 RPN原理
RPN网络的主要作用是得出比较准确的候选区域。整个过程分为两步
- 用n×n(默认3×3=9)的大小窗口去扫描特征图,每个滑窗位置映射到一个低维的向量(默认256维),并为每个滑窗位置考虑k种(在论文设计中k=9)可能的参考窗口(论文中称为anchors)
4.5.2.1 anchors

- 3*3卷积核的中心点对应原图上的位置,将该点作为anchor的中心点,在原图中框出多尺度、多种长宽比的anchors,三种尺度{ 128,256,512 }, 三种长宽比{1:1,1:2,2:1},每个特征图中的像素点有9中框
举个例子:

4.5.3 Faster RCNN训练
4.5.3.1 Faster R-CNN的训练
Faster R-CNN的训练分为两部分,即两个网络的训练。
- RPN训练:
- 目的:从众多的候选区域中提取出score较高的,并且经过regression调整的候选区域
- Fast RCNN部分的训练:
- Fast R-CNN classification (over classes) :所有类别分类 N+1,得到候选区域的每个类别概率
- Fast R-CNN regression (bbox regression):得到更好的位置

4.5.3.2 候选区域的训练
- 训练样本anchor标记
- 1.每个ground-truth box有着最高的IoU的anchor标记为正样本
- 2.剩下的anchor/anchors与任何ground-truth box的IoU大于0.7记为正样本,IoU小于0.3,记为负样本
- 3.剩下的样本全部忽略
- 正负样本比例为1:3

- 训练损失
- RPN classification (anchor good / bad) ,二分类,是否有物体,是、否
- RPN regression (anchor -> proposal) ,回归
- 注:这里使用的损失函数和Fast R-CNN内的损失函数原理类似,同时最小化两种代价
候选区域的训练是为了让得出来的 正确的候选区域, 并且候选区域经过了回归微调。在这基础之上做Fast RCNN训练是得到特征向量做分类预测和回归预测。
3.5.4 效果对比
| R-CNN | Fast R-CNN | Faster R-CNN | |
|---|---|---|---|
| Test time/image | 50.0s | 2.0s | 0.2s |
| mAP(VOC2007) | 66.0 | 66.9 | 66.9 |
3.5.5 Faster R-CNN总结
- 优点
- 提出RPN网络
- 端到端网络模型
- 缺点
- 训练参数过大
可以改进的需求:
- RPN(Region Proposal Networks) 改进对于小目标选择利用多尺度特征信息进行RPN
- 速度提升,如YOLO系列算法,删去了RPN,直接对proposal进行分类回归,极大的提升了网络的速度
3.5.6 总结
- Faster R-CNN的特点
- RPN的原理
3.5.7 问题?
1、Faster RCNN改进之处?
2、如何得到RPN的 anchors?
3.5.8 开源keras Faster RCNN 模型介绍
地址:https://github.com/jinfagang/keras_frcnn
3.5.8.1 环境需求
- 1、由于该源代码由keras单独库编写所以需要下载keras,必须是2.0.3版本
pip install keras==2.0.3
- 2、该源码读取图片以及处理图片标记图片工具使用opecv需要安装
pip install opencv-python
3.5.8.3 keras Faster RCNN代码结构
源码组成结构:

3.5.8.2 FaterRCNN源码解析
- detector:FasterRCNNDetector目标检测器代码
img_input = Input(shape=input_shape_img)
roi_input = Input(shape=(None, 4))
# define the base network (resnet here, can be VGG, Inception, etc)
shared_layers = nn.nn_base(img_input, trainable=True)
# define the RPN, built on the base layers
num_anchors = len(cfg.anchor_box_scales) * len(cfg.anchor_box_ratios)
rpn = nn.rpn(shared_layers, num_anchors)
classifier = nn.classifier(shared_layers, roi_input, cfg.num_rois, nb_classes=len(classes_count), trainable=True)
model_rpn = Model(img_input, rpn[:2])
model_classifier = Model([img_input, roi_input], classifier)
# this is a model that holds both the RPN and the classifier, used to load/save weights for the models
model_all = Model([img_input, roi_input], rpn[:2] + classifier)
try:
print('loading weights from {}'.format(cfg.base_net_weights))
model_rpn.load_weights(cfg.model_path, by_name=True)
model_classifier.load_weights(cfg.model_path, by_name=True)
except Exception as e:
print(e)
print('Could not load pretrained model weights. Weights can be found in the keras application folder '
'https://github.com/fchollet/keras/tree/master/keras/applications')
optimizer = Adam(lr=1e-5)
optimizer_classifier = Adam(lr=1e-5)
model_rpn.compile(optimizer=optimizer,
loss=[losses_fn.rpn_loss_cls(num_anchors), losses_fn.rpn_loss_regr(num_anchors)])
model_classifier.compile(optimizer=optimizer_classifier,
loss=[losses_fn.class_loss_cls, losses_fn.class_loss_regr(len(classes_count) - 1)],
metrics={'dense_class_{}'.format(len(classes_count)): 'accuracy'})
model_all.compile(optimizer='sgd', loss='mae')
1 RPN 与 classifier定义
- RPN结构
def rpn(base_layers, num_anchors):
x = Convolution2D(512, (3, 3), padding='same', activation='relu', kernel_initializer='normal', name='rpn_conv1')(
base_layers)
x_class = Convolution2D(num_anchors, (1, 1), activation='sigmoid', kernel_initializer='uniform',
name='rpn_out_class')(x)
x_regr = Convolution2D(num_anchors * 4, (1, 1), activation='linear', kernel_initializer='zero',
name='rpn_out_regress')(x)
return [x_class, x_regr, base_layers]
- classifier结构
def classifier(base_layers, input_rois, num_rois, nb_classes=21, trainable=False):
# compile times on theano tend to be very high, so we use smaller ROI pooling regions to workaround
if K.backend() == 'tensorflow':
pooling_regions = 14
input_shape = (num_rois, 14, 14, 1024)
elif K.backend() == 'theano':
pooling_regions = 7
input_shape = (num_rois, 1024, 7, 7)
# ROI pooling计算定义
out_roi_pool = RoiPoolingConv(pooling_regions, num_rois)([base_layers, input_rois])
out = classifier_layers(out_roi_pool, input_shape=input_shape, trainable=True)
out = TimeDistributed(Flatten())(out)
# 分类
out_class = TimeDistributed(Dense(nb_classes, activation='softmax', kernel_initializer='zero'),
name='dense_class_{}'.format(nb_classes))(out)
# note: no regression target for bg class
# 回归
out_regr = TimeDistributed(Dense(4 * (nb_classes - 1), activation='linear', kernel_initializer='zero'),
name='dense_regress_{}'.format(nb_classes))(out)
return [out_class, out_regr]
2 data_generators.py:传递图像参数,增广配置参数,是否进行图像增广
- IoU计算:
from __future__ import absolute_import
import numpy as np
import cv2
import random
import copy
from . import data_augment
import threading
import itertools
#并集
def union(au, bu, area_intersection):
area_a = (au[2] - au[0]) * (au[3] - au[1])
area_b = (bu[2] - bu[0]) * (bu[3] - bu[1])
area_union = area_a + area_b - area_intersection
return area_union
#交集
def intersection(ai, bi):
x = max(ai[0], bi[0])
y = max(ai[1], bi[1])
w = min(ai[2], bi[2]) - x
h = min(ai[3], bi[3]) - y
if w < 0 or h < 0:
return 0
return w*h
#交并比
def iou(a, b):
# a and b should be (x1,y1,x2,y2)
if a[0] >= a[2] or a[1] >= a[3] or b[0] >= b[2] or b[1] >= b[3]:
return 0.0
area_i = intersection(a, b)
area_u = union(a, b, area_i)
return float(area_i) / float(area_u + 1e-6)
3 损失计算 losses.py
- rpn的损失回归和分类
def rpn_loss_regr(num_anchors):
def rpn_loss_regr_fixed_num(y_true, y_pred):
if K.image_dim_ordering() == 'th':
x = y_true[:, 4 * num_anchors:, :, :] - y_pred
x_abs = K.abs(x)
x_bool = K.less_equal(x_abs, 1.0)
return lambda_rpn_regr * K.sum(
y_true[:, :4 * num_anchors, :, :] * (x_bool * (0.5 * x * x) + (1 - x_bool) * (x_abs - 0.5))) / K.sum(epsilon + y_true[:, :4 * num_anchors, :, :])
else:
x = y_true[:, :, :, 4 * num_anchors:] - y_pred
x_abs = K.abs(x)
x_bool = K.cast(K.less_equal(x_abs, 1.0), tf.float32)
return lambda_rpn_regr * K.sum(
y_true[:, :, :, :4 * num_anchors] * (x_bool * (0.5 * x * x) + (1 - x_bool) * (x_abs - 0.5))) / K.sum(epsilon + y_true[:, :, :, :4 * num_anchors])
return rpn_loss_regr_fixed_num
def rpn_loss_cls(num_anchors):
def rpn_loss_cls_fixed_num(y_true, y_pred):
if K.image_dim_ordering() == 'tf':
return lambda_rpn_class * K.sum(y_true[:, :, :, :num_anchors] * K.binary_crossentropy(y_pred[:, :, :, :], y_true[:, :, :, num_anchors:])) / K.sum(epsilon + y_true[:, :, :, :num_anchors])
else:
return lambda_rpn_class * K.sum(y_true[:, :num_anchors, :, :] * K.binary_crossentropy(y_pred[:, :, :, :], y_true[:, num_anchors:, :, :])) / K.sum(epsilon + y_true[:, :num_anchors, :, :])
return rpn_loss_cls_fixed_num
- fastrcnn的分类和回归
def class_loss_regr(num_classes):
def class_loss_regr_fixed_num(y_true, y_pred):
x = y_true[:, :, 4*num_classes:] - y_pred
x_abs = K.abs(x)
x_bool = K.cast(K.less_equal(x_abs, 1.0), 'float32')
return lambda_cls_regr * K.sum(y_true[:, :, :4*num_classes] * (x_bool * (0.5 * x * x) + (1 - x_bool) * (x_abs - 0.5))) / K.sum(epsilon + y_true[:, :, :4*num_classes])
return class_loss_regr_fixed_num
def class_loss_cls(y_true, y_pred):
return lambda_cls_class * K.mean(categorical_crossentropy(y_true[0, :, :], y_pred[0, :, :]))
========================================