Recurrent Models of Visual Attention
2014 NIPS
背景
模拟人类看东西的方式,我们并非将目光放在整张图像上,尽管有时候会从总体上对目标进行把握,但是也是将目光按照某种次序(例如,从上倒下,从左到右等等)在图像上进行扫描,然后从一个区域转移到另一个区域。这么一个一个的区域,就是定义的part,或者说是 glimpse。然后将这些区域的信息结合起来用于整体的判断和感受。
站在某个底层的角度,物体的显著性已经将这个物体研究的足够透彻。本文就是从这些东西上获得了启发,提出了一种新的框架,即:应用神经网络,基于 attention 任务驱动的视觉处理系统。本文模型考虑到一个视觉场景基于attention的处理看做是一个控制问题(a control problem),并且可以应用到动态图像,视频,或者处理动态视觉环境,像机器人,或者能够打游戏的agents。
思路概述
这个模型是一个 recurrent neural network(RNN),按照时间顺序处理输入,一次在一张图像中处理不同的位置,逐渐的将这些部分的信息结合起来,来建立一个该场景或者环境的动态间隔表示。并非马上处理整张图像甚至(bounding box),在每一个步骤中,模型基于过去的信息和任务的需要选择下一个位置进行处理。这样就可以控制模型的参数和计算量,使之摆脱输入图像的大小的约束。这里和CNN有明显的不同。我们就是要描述这么一个端到端的优化序列,能够直接训练模型,最大化一个性能衡量,依赖于该模型在整个任务上所做的决策。利用反向传播来训练神经网络的成分和策略梯度来解决控制问题的不可微性( the non-differentiabilities due to the control problem)。
本文将 attention problem 看做是目标引导的序列决策过程,能够和视觉环境交互。在每一个时间点,agent 只能通过感知器来有带宽限制地观察全局,即: it never senses the environment in full,他只能在一个局部区域或者狭窄的频域范围进行信息的提取。
The agent 可以自主的控制如何布置感知器的资源,即:选择感知的位置区域。该agent也可以通过执行 actions 来影响环境的真实状态。由于该环境只是部分可观察,所以他需要额外的信息来辅助其进行决定如何行动和如何最有效的布置感知器。每一步,agent 都会收到奖励或者惩罚,agent 的目标就是将奖励最大化。
模型
总模型架构


领会传感器,扫视传感器(Glimpse Sensor):
提取图像输入,通过位置信息 l t − 1 l_{t-1} lt−1,以其为中心,长宽为 w w w的倍数提取出图像区域,并把提取的图像区域归一化到 w ∗ w w*w w∗w大小,拼接起来得到 ρ ( x t , l t − 1 ) \rho\left(x_{t}, l_{t-1}\right) ρ(xt,lt−1)。这样就把不同层次的信息组合了起来。过程如下图所示:
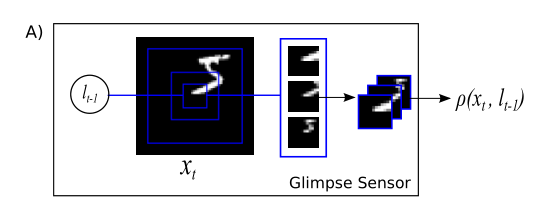
给定观察扫视在输入图像上的坐标,传感器提取以为中心的视网膜状(不同的观测感受大小)表示,该表示包含多个分辨率面片。

领会网络,扫视网络(Glimpse Network):
给定位置 l t − 1 l_{t-1} lt−1和输入图像 x t x_t xt,使用扫视传感器提取视网膜表示 ρ ( x t , l t − 1 ) \rho\left(x_{t}, l_{t-1}\right) ρ(xt,lt−1)。然后,使用分别由 θ g 0 \theta^0_g θg0和 θ g 1 \theta^1_g θg1参数化的独立线性层,将视网膜表示和扫视位置映射到隐藏空间中,所述独立线性层使用校正单元,随后是另一个线性层 θ g 2 \theta^2_g θg2,以组合来自两个组件的信息。扫视网络为注意力网络 f g ( . ; { θ q 0 , θ q 1 , θ g 2 } ) f_{g}\left(. ;\left\{\theta_{q}^{0}, \theta_{q}^{1}, \theta_{g}^{2}\right\}\right) fg(.;{ θq0,θq1,θg2})定义了一个可训练的有限带宽传感器,用于产生感知表示 g t g_t gt。
概括为:输入层次信息 ρ ( x t , l t − 1 ) \rho\left(x_{t}, l_{t-1}\right) ρ(xt,lt−1)通过网络得 f g ( θ g 0 ) f_{g}\left(\theta_{g}^0\right) fg(θg0)到潜在的层次信息,同时位置信息 l t − 1 l_{t-1} lt−1通过网络得 f g ( θ g 1 ) f_{g}\left(\theta_{g}^1\right) fg(θg1)到潜在的位置信息,把这两种信息 f g ( θ g 2 ) f_{g}\left(\theta_{g}^2\right) fg(θg2)通过网络得到最终RNN的输入glimpse feature vector向量 g t g_t gt。结构如下:
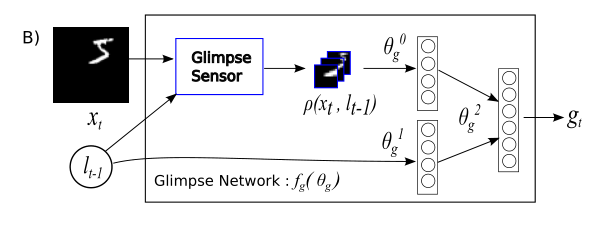
模型架构(Model Architecture):
( θ ∗ \theta_{*} θ∗,这里的下标定义代表作用于什么东西的参数,或者产生是吗东西的参数,也就是对应这个网络的参数,是可以被训练出来的,eg. θ h \theta_h θh代表通过输入映射出 h t h_t ht的参数)
总的来说,模型是一个RNN。模型的核心网络部分就是 f h ( . ; θ h ) f_{h}\left(. ; \theta_{h}\right) fh(.;θh),作为一个感知领会的表达。这个表达分为两个方面,第一方面是当前输入 g t g_t gt的表示,第二方面是上一个内部的转台传导 h t − 1 h_{t-1} ht−1,将这两部分相结合,产生模型 h t h_t ht作为新内部状态。位置网络 f l ( . ; θ l ) f_{l}\left(. ; \theta_{l}\right) fl(.;θl)和动作网络 f a ( . ; θ a ) f_{a}\left(. ; \theta_{a}\right) fa(.;θa)使用模型的内部状态 h t h_{t} ht来产生下一个位置,分别是 l t l_t lt和动作或者分类等的输出 a t a_t at。这个基本的RNN不断的迭代重复下去,长度可以人为设置。
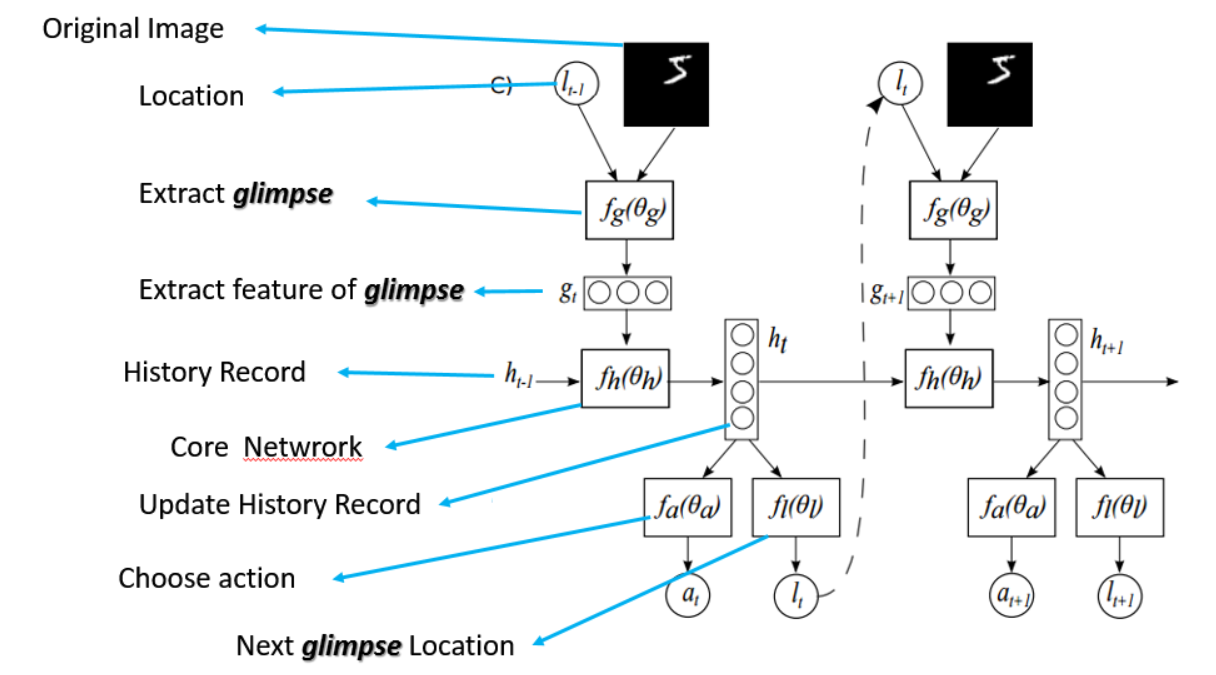
那么,可以看出,attention model 的输入是一个图像,那么根据任务的需要,可以输出一系列的图像 patch,即 attention region,仅仅对这些图像patch 进行处理,一方面可以减少非必要信息的干扰,降低噪声的影响,然后还可以减少计算量.
强化学习部分的结合
Sensor:
在每一个步骤 t t t,该agent 接收部分观察,没有处理全幅图像的权限,但是可以通过感知器来提取从 x t x_t xt得到的信息。假设从 L t − 1 L_{t-1} Lt−1 提取的类似视网膜表示 ρ ( x t , l t − 1 ) \rho\left(x_{t}, l_{t-1}\right) ρ(xt,lt−1) ,该表示比原始图像 x x x 维度较低,我们称之为 glimpse。然后通过 glimpse network 的网络结构(包含 glimpse sensor )来产生 glimpse feature vector g t g_t gt。
Internal state:
The agent 保持一个间隔状态,用来总结从过去观察得到的历史信息。The internal state 由RNN的隐单元 h t h_t ht 构成,随着时间利用 core network 进行更新,该网络的额外输入是: the glimpse feature vector g t g_t gt。
Actions:
每一步,agent 执行两个步骤:
通过感知控制 l t l_t lt来决定如何布置感知器;
得到一个可能会影响环境状态的环境动作 a t a_t at 。
Reward:
在执行一个动作之后,agent会收到一个环境中得到的新的视觉观察 x t + 1 x_{t+1} xt+1 和 一个奖励信号 r t + 1 r_{t+1} rt+1。在目标识别场景中,如果分类正确,就奖励1分,否则奖励就设置为0。以上就是Partially Observable Markov Decision Process (POMDP) 的一种特殊示例。
图形示例代码分析强化学习的Hard-Attention
网络构造
这篇源码中模型的写法遵循:由底到顶,先细节后整体。和CNN不同,Recurrent网络带有反馈,呈现较为复杂的多级嵌套结构。请着重关注每个模块的输入、输出和作用部分。
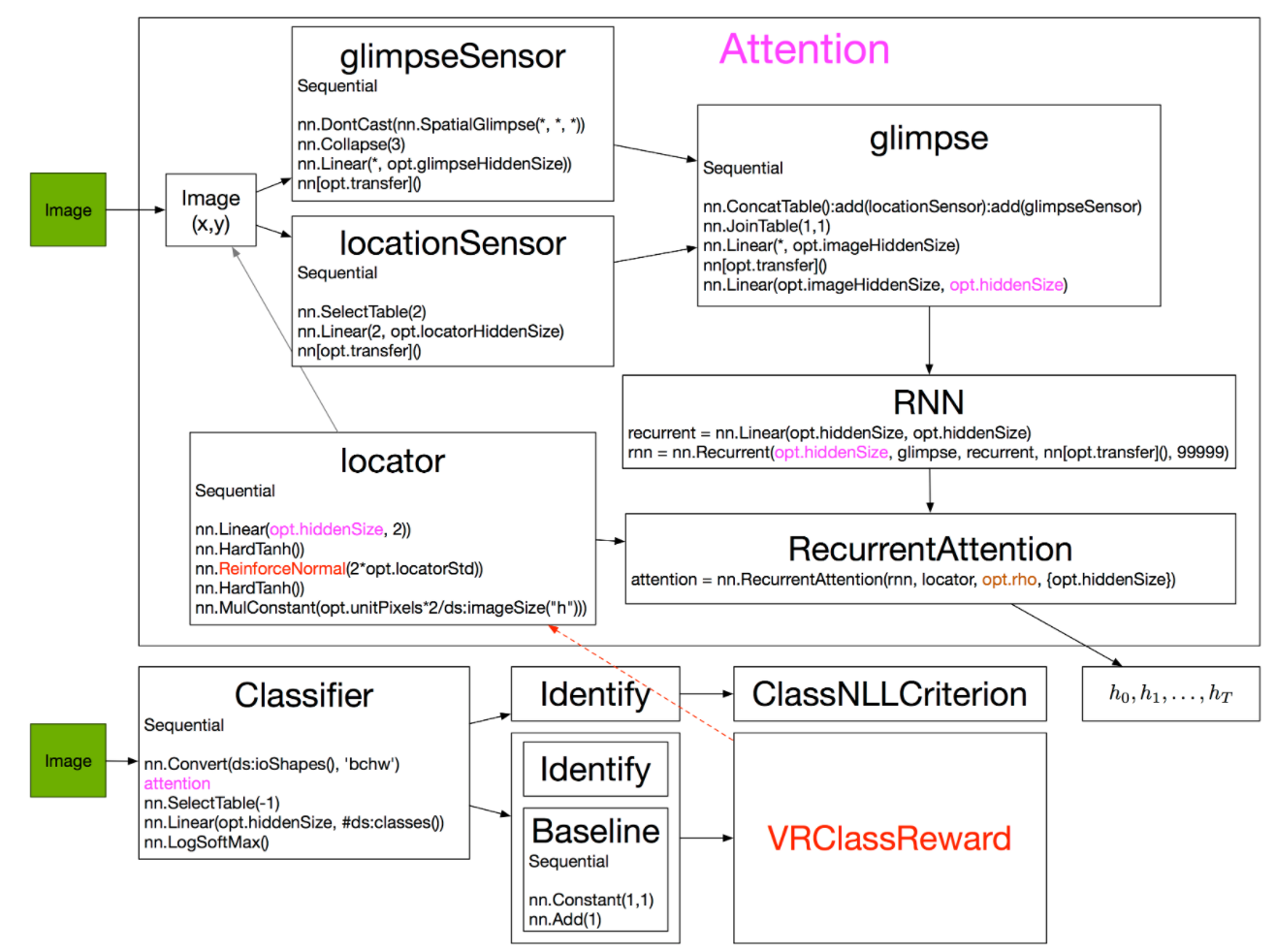
Glimpse网络
输入:图像 I I I和观察位置l
输出:观察结果 x x x
蓝色输入,橙色输出,菱形表示串接:
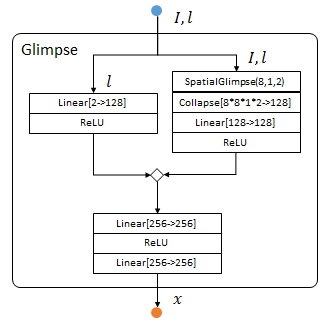
首先用locationSensor(左半)提取位置信息 l l l中的特征:
locationSensor:add(nn.SelectTable(2)) --选择两个输入中的第二个,位置l
locationSensor:add(nn.Linear(2, opt.locatorHiddenSize)) --Torch中的Linear指全连层
locationSensor:add(nn[opt.transfer]()) --opt.transfer定义一种非线性运算,本文中是ReLU
之后用glimpseSensor(右半)提取图像 I I I位置 l l l的特征。
其中SpacialGlimpse是dp中定义的层,提取尺寸为PatchSize的Depth层图像,相邻层比例为Scale。
glimpseSensor:add(nn.SpatialGlimpse(opt.glimpsePatchSize, opt.glimpseDepth, opt.glimpseScale):float()) --SpatialGlimpse提取小块金字塔
glimpseSensor:add(nn.Collapse(3)) --压缩第三维
glimpseSensor:add(nn.Linear(ds:imageSize('c')*(opt.glimpsePatchSize^2)*opt.glimpseDepth, opt.glimpseHiddenSize))
glimpseSensor:add(nn[opt.transfer]())
两者结果串接为glimpse,输出包含位置和纹理信息的 x x x,尺寸为hiddenSize:
glimpse:add(nn.ConcatTable():add(locationSensor):add(glimpseSensor))
glimpse:add(nn.JoinTable(1,1)) --把串接数据合并成一个Tensor
glimpse:add(nn.Linear(opt.glimpseHiddenSize+opt.locatorHiddenSize, opt.imageHiddenSize))
glimpse:add(nn[opt.transfer]())
glimpse:add(nn.Linear(opt.imageHiddenSize, opt.hiddenSize)) --从imageHiddenSize到hiddenSize的全连层
作用:通过小范围观测,提取纹理和位置信息。
说明
Torch的基础数据是Tensor,而lua中用Table实现类似数组的功能。nn库中专门有一系列Table层,用于处理涉及这两者的运算。例如:
ConcatTable- 把若干个输出Tensor放置在一个Table中。
SelectTable- 从输入的Table中选择一个Tensor。
JoinTable- 把输入Table中的所有Tensor合并成一个Tensor。
Recurrent网络
输入:和Glimpse网络相同,图像 I I I,观察位置 l l l。
输出:系统循环状态 r r r

使用Recurrent类创建一个包含Glimpse子网络的rnn框架。Recurrent类的第二个参数(glimpse)指出如何处理输入,第三个参数(recurrent)指出如何处理前一时刻的循环状态。
recurrent = nn.Linear(opt.hiddenSize, opt.hiddenSize)
rnn = nn.Recurrent(opt.hiddenSize, glimpse, recurrent, nn[opt.transfer](), 99999)
作用:通过小范围观测,更新网络循环状态。
nn.Recurrent最后一个参数表示“最多考虑的backward步数”,设定为一个很大的值(99999)。在后续模块中会设定真实的记忆步数rho。
Locator网络
输入:系统循环状态 r r r,也就是Recurrent网络的输出
输出:观测位置 l l l

这部分核心是dp库中的ReinforceNormal层:正态分布的强化学习层。dp库中还有其他分布的强化学习层。
locator:add(nn.Linear(opt.hiddenSize, 2))
locator:add(nn.HardTanh()) -- bounds mean between -1 and 1
locator:add(nn.ReinforceNormal(2*opt.locatorStd, opt.stochastic)) -- sample from normal, uses REINFORCE learning rule
locator:add(nn.HardTanh()) -- bounds sample between -1 and 1
locator:add(nn.MulConstant(opt.unitPixels*2/ds:imageSize("h"))) --对位置l做了归一化:相对图像中心的最大偏移为unitPixel。
ReinforceNormal层在训练状态下,会以前一层输入为均值,以第一个参数(2*opt.locatorStd)为方差,产生符合高斯分布采样结果;
在训练状态下,如果第二个参数(opt.stochastic)为真,则以相同方式采样,否则直接传递前一层结果。
简单来说,Reinforce层的作用是:在训练时,围绕当前策略(前层输出),探索一些新策略(高斯采样)。具体怎么训练在下篇再说。
作用:利用系统循环状态,决定观测位置。
Attention网络
(包含Glimpse网络Recurrent网络Locator网络)
输入:图像 I I I
输出:系统循环状态 r r r

直接使用rnn包中的RecurrentAttention层进行定义。
第一个参数(rnn)指明如何处理循环状态 r r r的记忆,第二个参数(locator)指明利用循环状态执行何种动作(action)。第三个参数(rho)指明循环步数,第四个参数指明隐变量维度。
attention = nn.RecurrentAttention(rnn, locator, opt.rho, {
opt.hiddenSize})
作用:输入图像,循环固定步数,每一步更新系统循环状态。
Agent网络
输入:图像 I I I
输出:字符属于各类的概率向量 p p p
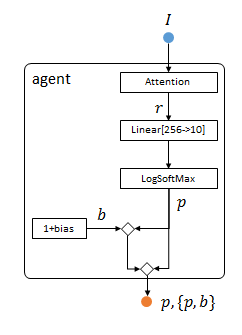
在前面attention网络的基础上,只对系统循环变量做简单非线性变换,即得到图像属于各类字符的概率 p p p。
agent:add(attention)
agent:add(nn.SelectTable(-1))
agent:add(nn.Linear(opt.hiddenSize, #ds:classes()))
agent:add(nn.LogSoftMax()) -- 这里输出分类结果
由于系统中存在强化学习层ReinforceNormal,所以需要一个baseline变量 b b b。这里利用ConcatTable把 b b b和分类结果合并到一个Table里输出。
seq:add(nn.Constant(1,1))
seq:add(nn.Add(1))
concat = nn.ConcatTable():add(nn.Identity()):add(seq)
concat2 = nn.ConcatTable():add(nn.Identity()):add(concat)
agent:add(concat2)
整个系有两组输出:分类结果 p p p,以及分类结果+baseline对${ p , b } $。
作用:把系统隐变量转化成估计结果,并且输出一个baseline,便于后续优化。
训练
总结下,可以看出整个pipeline 有三个小网络,即: the glimpse network, the core network, and the action network。我们的训练目标就是学习到一种策略使得总的奖励达到最大。
整个模型过程可以看做是一个局部马尔科夫决策过程。每个阶段的动作和位置只与上一阶段的动作和位置有关。即展开RNN结构,以时间为序,整个过程可表示为
s 1 : t = x 1 , l 1 , a 1 , … , x t − 1 , l t − 1 , a t − 1 , x t s_{1: t}=x_{1}, l_{1}, a_{1}, \ldots, x_{t-1}, l_{t-1}, a_{t-1}, x_{t} s1:t=x1,l1,a1,…,xt−1,lt−1,at−1,xt
根据上一阶段的动作 a t − 1 a_{t-1} at−1和位置 l t − 1 l_{t-1} lt−1 ,从输入图像提取出信息,通过模型网络,输出特征信息,利用POMDP决定出下一阶段的动作和 a t a_t at位置,设: l t l_{t} lt
π ( a t ∣ s 1 : t ; θ ) \pi\left(a_{t} \mid s_{1: t} ; \theta\right) π(at∣s1:t;θ) 为参数化为 θ \theta θ的随机策略。
p ( l 0 ) p\left(l_{0}\right) p(l0)为初始位置的概率
p ( s t + 1 ∣ s 1 : t ; a t ) p\left(s_{t+1} \mid s_{1: t} ; a_{t}\right) p(st+1∣s1:t;at)为执行动作 a t a_t at,位置由 l t l_t lt到 l t + 1 l_{t+1} lt+1的概率。
r ( s 1 : t , a t , s t + 1 ) r\left(s_{1: t},a_{t},s_{t+1}\right) r(s1:t,at,st+1)表示执行动作 a t a_t at,位置由 l t l_t lt到 l t + 1 l_{t+1} lt+1的即刻奖励。
γ t \gamma^{t} γt表示奖励的折扣
则整个过程的回报 R ( s ) = ∑ t = 1 T γ t r ( s 1 : t , a t , s t + 1 ) R(s)=\sum_{t=1}^{T} \gamma^{t} r\left(s_{1: t}, a_{t}, s_{t+1}\right) R(s)=∑t=1Tγtr(s1:t,at,st+1)
策略参数$\theta $的期望回报为:
当前所有可能转移情况下转移的奖励加权平均
J ( θ ) = E p ( s ∣ θ ) [ R ( s ) ] = ∫ p ( s ∣ θ ) R ( s ) d s J(\theta)=E_{p(s \mid \theta)}[R(s)]=\int p(s \mid \theta) R(s) \mathrm{d} s J(θ)=Ep(s∣θ)[R(s)]=∫p(s∣θ)R(s)ds
p ( s ∣ θ ) = p ( l 0 ) ∏ t = 1 T p ( s t + 1 ∣ s 1 : t , a t ) π ( a t ∣ s 1 : t , θ ) p(s \mid \theta)=p\left(l_{0}\right) \prod_{t=1}^{T} p\left(s_{t+1} \mid s_{1: t}, a_{t}\right) \pi\left(a_{t} \mid s_{1: t}, \theta\right) p(s∣θ)=p(l0)∏t=1Tp(st+1∣s1:t,at)π(at∣s1:t,θ)
对于梯度计算,有个log小技巧, ∇ p ( s ∣ θ ) = p ( s ∣ θ ) ∇ log p ( s ∣ θ ) \nabla p(s \mid \theta)=p(s \mid \theta) \nabla \log p(s \mid \theta) ∇p(s∣θ)=p(s∣θ)∇logp(s∣θ)故计算回报的梯度有:
技巧证明 ∇ l o g ( f ( x ) ) = 1 f ( x ) ∇ f ( x ) \nabla log({f(x)}) =\frac{1}{f(x)} \nabla f(x) ∇log(f(x))=f(x)1∇f(x)
所以 f ( x ) ∗ ∇ l o g ( f ( x ) ) = ∇ f ( x ) f(x)*\nabla log({f(x)}) =\nabla f(x) f(x)∗∇log(f(x))=∇f(x)
∇ θ J ( θ ) = ∫ ∇ θ p ( s ∣ θ ) R ( s ) d s = ∫ p ( s ∣ θ ) ∇ θ log p ( s ∣ θ ) R ( s ) d s = ∫ p ( s ∣ θ ) ∑ t = 1 T ∇ θ log π ( a t ∣ s 1 : t ; θ ) R ( s ) d s = E p ( s ∣ θ ) [ ∑ t = 1 T ∇ θ log π ( a t ∣ s 1 : t ; θ ) R ( h ) ] \begin{array}{l} \nabla_{\theta} J(\theta)&=\int \nabla_{\theta} p(s \mid \theta) R(s) \mathrm{d} s \\ &=\int p(s \mid \theta) \nabla_{\theta} \log p(s \mid \theta) R(s) \mathrm{d} s \\ &=\int p(s \mid \theta) \sum_{t=1}^{T} \nabla_{\theta} \log \pi\left(a_{t} \mid s_{1: t} ; \theta\right) R(s) \mathrm{d} s \\ &=E_{p(s \mid \theta)}\left[\sum_{t=1}^{T} \nabla_{\theta} \log \pi\left(a_{t} \mid s_{1: t} ; \theta\right) R(h)\right] \end{array} ∇θJ(θ)=∫∇θp(s∣θ)R(s)ds=∫p(s∣θ)∇θlogp(s∣θ)R(s)ds=∫p(s∣θ)∑t=1T∇θlogπ(at∣s1:t;θ)R(s)ds=Ep(s∣θ)[∑t=1T∇θlogπ(at∣s1:t;θ)R(h)]
由于 p ( s ∣ θ ) p\left(s\mid \theta \right) p(s∣θ)未知,故取经验平均求解,即:
∇ θ J ( θ ) ^ = 1 M ∑ i = 1 M ∑ t = 1 T ∇ θ log π ( a t i ∣ s 1 : t i ; θ ) R t i \nabla_{\theta} J \hat{(\theta)}=\frac{1}{M} \sum_{i=1}^{M} \sum_{t=1}^{T} \nabla_{\theta} \log \pi\left(a_{t}^{i} \mid s_{1: t}^{i} ; \theta\right) R_{t}^{i} ∇θJ(θ)^=M1i=1∑Mt=1∑T∇θlogπ(ati∣s1:ti;θ)Rti
可以通过减去一个 b t b_t bt降低方差,即:
1 M ∑ i = 1 M ∑ t = 1 T ∇ θ log π ( a t i ∣ s 1 : t i ; θ ) ( R t i − b t ) \frac{1}{M} \sum_{i=1}^{M} \sum_{t=1}^{T} \nabla_{\theta} \log \pi\left(a_{t}^{i} \mid s_{1: t}^{i} ; \theta\right)\left(R_{t}^{i}-b_{t}\right) M1i=1∑Mt=1∑T∇θlogπ(ati∣s1:ti;θ)(Rti−bt)
b t b_t bt可取 E π [ R t ] E_\pi[R_t] Eπ[Rt]。 该算法被称为REINFORCE
训练神经网络自然想到反向传播,通过REINFORCE得到 f a f_a fa 和 f l f_l fl的梯度信息。然后反向依次训练RNN,Glimpse Network。对于分类问题,由于 a T a_T aT是确定,最大化 log π ( a t i ∣ s 1 : t i ; θ ) \log \pi\left(a_{t}^{i} \mid s_{1: t}^{i} ; \theta\right) logπ(ati∣s1:ti;θ),通过优化的交叉熵 f a f_a fa得到梯度,反向训练模型。
总结
通过实际建模,神经网络可作为非常好的特征抽取器和函数拟合器,与其他算法结合,训练出更理想的模型。
参考文献
论文地址:Recurrent Models of Visual Attention
注意力机制之Recurrent Models of Visual Attention - 知乎
论文笔记之: Recurrent Models of Visual Attention - AHU-WangXiao - 博客园
【增强学习】Recurrent Visual Attention源码解读_shenxiaolu1984的专栏-CSDN博客
Useful Links:
Torch实现的解释: http://torch.ch/blog/2015/09/21/rmva.html#rmva.ref
RAM的TF实现1: https://github.com/zhongwen/RAM
RAM的TF实现2:https://github.com/hehefan/Recurrent-Attention-Model
RAM的TF实现3: https://github.com/jtkim-kaist/ram_modified
RAM的TF实现4: https://github.com/seann999/tensorflow_mnist_ram
RAM的TF实现5: https://github.com/qingzew/tensorflow-ram
RAM的博客: http://blog.csdn.net/baidu_17806763/article/details/59595848
RAM的解析: http://www.cnblogs.com/wangxiaocvpr/p/5537454.html
RAM中代码中了解算法: http://blog.csdn.net/shenxiaolu1984/article/details/51582185
Mastering the game of Go with deep neural networks and tree search: https://www.nature.com/articles/nature16961
ONNX: http://onnx.ai/getting-started
ONNX: https://github.com/onnx
Converter: https://github.com/ysh329/deep-learning-model-convertor
Torch Converter: https://github.com/Teaonly/trans-torch
ONNX Start: http://onnx.ai/getting-started
ONNX TF: https://github.com/onnx/onnx-tensorflow
MULTIPLE OBJECT RECOGNITION WITH VISUAL ATTENTION: https://arxiv.org/pdf/1412.7755.pdf