目录
扫描二维码关注公众号,回复:
12686739 查看本文章

一、前期准备
基本配置
如果按照我的配置,务必使用我使用的文件
链接:https://pan.baidu.com/s/1jpHnqGa4yXb_g25aJuHjRQ
提取码:8dvb
复制这段内容后打开百度网盘手机App,操作更方便哦
开始之初,创建虚拟机时,内存最好分配2G左右,不然图形化界面会很卡的
提醒读者,一定要注意是在什么用户下敲的命令,我在里面都有详细解释,务必认真阅读,弄错一步都有可能不成功
打开终端
桌面右击点击open in terminal或者ctrl+shift+t打开终端

查看自己版本号
cat /proc/version
修改提示主机名
hostname hadooproot配置
修改root密码(如果开始没有创建的话)
sudo passwd root
切换为root用户方便后面操作,最后一个符号由$变为#则代表切换为了root用户(新手建议使用普通用户用sudo提权)
su
网络配置
查看自己的网络是否能用
ip ad正常情况下输出是这样的

第一个lo为回环地址网卡,不用管,主要是第二个ens33为你的上网地址网卡,看有没有IP地址等等,没有的话提供以下思路
1.重启网卡
/etc/init.d/network-manager restart2.可能是你的外面的路由器的问题,可以换成NAT模式
3.修改配置文件(由于Ubuntu的配置文件太乱了,建议直接图形化里面改,如下,都改成自动


然后再回到命令行输入dhclient重新获取一下地址即可
dhclient软件源配置
网络配置通后先更换一下软件仓库源为阿里的镜像源
首先将如下写入一个文件,复制如下文件
deb http://mirrors.aliyun.com/ubuntu/ trusty main multiverse restricted universe
deb http://mirrors.aliyun.com/ubuntu/ trusty-backports main multiverse restricted universe
deb http://mirrors.aliyun.com/ubuntu/ trusty-proposed main multiverse restricted universe
deb http://mirrors.aliyun.com/ubuntu/ trusty-security main multiverse restricted universe
deb http://mirrors.aliyun.com/ubuntu/ trusty-updates main multiverse restricted universe
deb-src http://mirrors.aliyun.com/ubuntu/ trusty main multiverse restricted universe
deb-src http://mirrors.aliyun.com/ubuntu/ trusty-backports main multiverse restricted universe
deb-src http://mirrors.aliyun.com/ubuntu/ trusty-proposed main multiverse restricted universe
deb-src http://mirrors.aliyun.com/ubuntu/ trusty-security main multiverse restricted universe
deb-src http://mirrors.aliyun.com/ubuntu/ trusty-updates main multiverse restricted universevim 1.txt 如果没有vim可以先使用vi,命令一样进入后按i进入编辑模式后右键paste黏贴进入,再shift加两下z(两下大写z)保存退出
之后一个命令导入配置文件
cat 1.txt >>/etc/apt/source.list最后使用update命令更新源文件
apt-get update -y
之后就可以下载安装常用编辑器,我本人喜欢用vim当然,新手推荐用nano有提示帮助
apt-get install vim -y安装ssh
apt-get install openssh-server -y二、创建hadoop用户和文件
用户创建
2.创建用户并自动创建文件,指定bash为shell
useradd -m hadoop -s /bin/bash
由于创建过一次忘了删,所以会报文件存在的错误,但还是成功
3.创建密码
passwd hadoop
4.添加Hadoop 到hadoop组(需要注意的是usermod命令修改用户组,如下为例,第一个Hadoop为用户组名,第二个为用户名
usermod -a -G hadoop hadoop![]()
因为以后可能会用到hadoop用户执行root才有的权限,所以将hadoop添加到sudo文件里
首先打开文件
vim /etc/sudoers进入后按i进入编辑模式,找到root这里在下面添加一行
hadoop ALL=(ALL:ALL) ALL然后按一下ESC键,再按住shift不放按两下Z(大写的两个Z)保存并推出vim编辑器,Hadoop用户将会拥有sudo提权的权限
保存的时候可能会报这个错

这是因为文件设置成了只读,想要强制保存退出的话先猛按ESC再输入:会在左下角有个:还有个待输入的光标闪烁,这时候输入wq!再回车就行了

按照教科书上的所有的下载的以及从主机上发过来的文件全部都放到/home/hadoop/downloads下
创建文件
mkdir /home/hadoop/downloads小插曲
想删除用户hadoop
报错:
userdel: user hadoop is currently used by process 19689![]()
导致原因,频繁切换su
解决办法:
使用w查看哪些用户登录

使用who查看哪些用户使用
使用crtl+d退出用户(多使用几次退出完)
再次删除,失败
查看哪些进程在占用
ps -aux |grep 19689
直接杀死进程
kill -9 19689再次查看进程

再次删除,成功!
三、配置java环境及安装eclipse
安装eclipse
我这里使用的是VMware虚拟机可以直接拖拽到里面,如果使用的是 VirtualBox开源虚拟机,则需要搭建一个ftp来传送,Ubuntu搭建ftp比较简单,教材上也详细,就不再赘述,这里讲一下使用VMware拖拽导致找不到文件的方法
首先拖拽eclipse

本来想直接能够复制进我打开的文件,结果并不是,这里提供一个命令直接找到文件 find
find使用方法
find path 【option】file
find /* -name eclipse*然后再使用mv命令移动到上面创建的hadoop下载文件夹中
mv /home/zxl/.cache/vmware/drag_and_drop/rrwsez/eclipse-4.7.0-linux.gtk.x86_64.tar.gz /home/hadoop/downloads/
之后把文件解压到/use/local下
tar -zxvf eclipse-4.7.0-linux.gtk.x86_64.tar.gz -C /usr/local/
之后进入解压文件夹并且运行eclipse即可

cd /usr/local/eclipse/
./eclipse
安装java环境
java环境包依旧放到download下,解压到创建的/usr/lib/jvm下
mkdir /usr/lib/jvm
find /* -name jdk-8u1*
mv /home/zxl/.cache/vmware/drag_and_drop/rrwsez/jdk-8u11-linux-x64.tar.gz /home/hadoop/downloads/
cd /home/hadoop/downloads/
tar -zxvf /home/hadoop/downloads/jdk-8u11-linux-x64.tar.gz -C /usr/lib/jvm/
配置java四个环境变量,这里说明一下,如果时按照我的做的一定要和我创建的文件夹
一模一样,不然不会成功
使用vim打开linux的环境变量文件
这里需要强调一下,用的那个用户编辑的下面的文件,就是那个用户的变量,我这个用的root用户的,所以就只有在root用户下才可以使用java命令
vim ~/.bashrc需要切换到Hadoop用户下面的可以如下教程
su hadoop
sudo vim ~/.bashrc
后面的教程相同
在开头输入如下,记得进去后先按下i进入编辑模式才可以黏贴
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_11
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH这里一定要和我输入的一模一样,而且使用我提供的软件包才可以,也可以使用自己的,只不过需要改一下版本号等等
输入后按两次大写的z保存退出

更新重置下环境变量文件,并检查java环境配置是否成功,出现和我一样的提示则配置成功
source ~/.bashrc
java -version 
Java环境配置篇结束
四、安装hadoop
拖拽移动hadoop
find /* -name hadoop*
mv /home/zxl/.cache/vmware/drag_and_drop/rrwsez/hadoop-3.1.3.tar.gz /home/hadoop/downloads/
cd /home/hadoop/downloads/
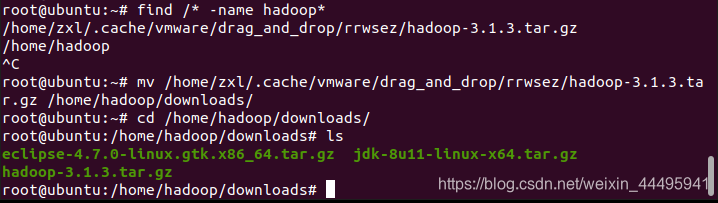
同样需要解压到/usr/local/文件夹下
tar -zxvf hadoop-3.1.3.tar.gz -C /usr/local/
进入
/usr/local/
更改文件名
hadoop-3.1.3
为
hadoop
并更改文件权限为Hadoop所有

进入解压文件,验证软件是否可用
cd /usr/local/hadoop
./bin/hadoop version
有如下提示则代表成功

五、伪分布式配置
伪分布就是把自己的Ubuntu既当成名称节点也当成数据节点(既当爹又当妈),读取HDFS中的文件
其实就是需要更改一下配置文件,格式化一下名称节点就行了
修改配置文件
修改配置文件core-site.xml的<configuration>标签
vim /usr/local/hadoop/etc/hadoop/core-site.xml
添加如下内容(如果是按照我的教程配置的就可以直接黏贴,不然请自行斟酌文件名
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://127.0.0.1:9000</value>
</property>
同上面的方式保存退出
修改配置文件hdfs-site.xml的<configuration>标签
vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml添加如下内容:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>
dfs.namenode.name.dir</name>
<value>file:/opt/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop/tmp/dfs/data</value>
</property>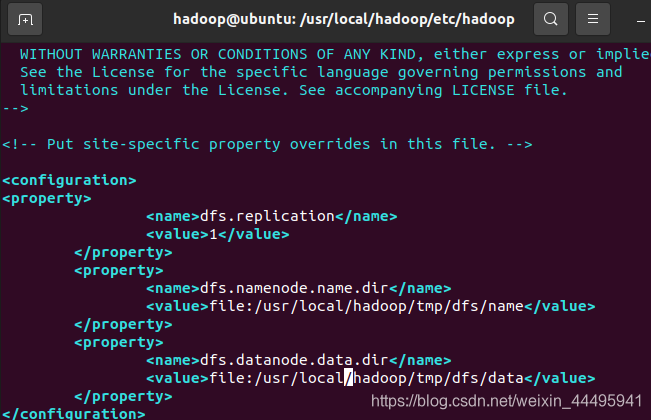
执行名称节点格式化
修改完配置文件只需要执行一下名称节点的格式化即可
cd /usr/loca/hadoop
./bin/hdfs namenode -format
看到如下输出的最后的提示则说明成功

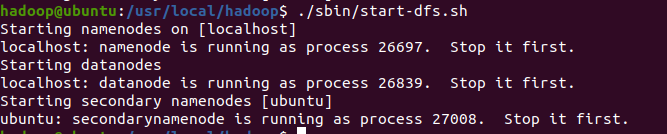
启动测试
输入命令测式
cd /usr/local/hadoop
./sbin/start-dfs.sh![]()
报错:

初步判断式因为ssh没有配置免密登录
ssh免密登录设置
1. 生成公钥私钥,将在~/.ssh文件夹下生成文件id_rsa:私钥,id_rsa.pub:公钥
cd ~/.ssh/
ssh-keygen -t rsa //前面没有空格一直回车即可

2. 导入公钥到认证文件,更改权限:
(1)导入本机:
理论上需要将本机的公匙复制到服务器的authorized_keys下,但是这里只在本机登录,所以进行到这一步就可以了,
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys这之后的就不用配置了
(2)导入服务器:(我只是在本机配置的,所以这一步我没做)
首先将公钥复制到服务器:
scp ~/.ssh/id_rsa.pub xxx@host:/home/xxx/id_rsa.pub
然后,将公钥导入到认证文件,这一步的操作在服务器上进行:
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
最后在服务器上更改权限:
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
3)测试:ssh localhost 第一次需要输入yes和密码,之后就不需要了。
再次测试
成功!