1.1 DataX下载地址
http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
1.2 安装DataX
步骤1:使用wget命令,采用阿里云地址下载
[root@hadoop201 software]# wget http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
下载后当前路径下会有tar包
-rw-r--r-- 1 root root 829372407 Oct 12 2019 datax.tar.gz
步骤2:解压安装包到/opt/module下
[root@hadoop201 software]# tar -zxvf datax.tar.gz -C /opt/module/
步骤3:查看datax的bin目录
通过datax.py去执行命令,上传json文件
1.3 DataX执行的json文件解析
{
job: //最外侧,任务
setting:{
//设置
speed:{
//速度
channel:3 //指定用几个子线程去跑这个任务,线程越多,速度越快
content:{
//内容
reader:{
//读数据部分
name:"hdfsreader" //指明什么类型的reader,hdfsreader读HDFS
parameter:{
//参数
path:"/user/xxx/dt=${dt}/dn=${dn}/*" //要读取的HDFS上的数据库的路径
defaultFS:"" //HDFS地址,HA是hdfs://mycluster
hadoopConfig:{
//Hadoop的一些配置
"dfs.nameservices":"mycluster" //HDFS集群名
"dfs.ha.namenode.mycluster":"nn1,nn2,nn3" //HA的多个namenode
"dfs.namenode.rpc-address.mycluster.nn1":hadoop201:8020 //HDFSnamenode1的地址
"dfs.namenode.xxx.nn2" //第二个namenode的地址
"dfs.namenode.xxx.nn3" //第三个namenode的地址
"dfs.client.failover.proxy.provider.nameservice1": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider" //HDFS的namenode的失败重试机制
column:[{
index:0, type:String}, {
value:${
dn}, type:string}] //每个列封装成一个json对象,读列通过下标索引读取数据块中的列;type是数据库中列对应的数据类型;外部传入的参数使用固定值value接收。
fileType:"text" //数据块文件类型,行式存储
encoding:"UTF-8" //数据块文件编码格式
fieldDelimiter:"\t" //数据块中字段的分隔符,和Hive建表的时候的分隔符一致
writer:{
//写数据部分
name:"mysqlwriter" //指明什么类型的writer,mysqlwriter写到MySQL
parameter:{
writerMode:"insert" //写入数据库的方式,insert、replace(主键冲突会替换)
username:"root" //mysql的用户名
password:"123456" //mysql的密码
column:[xxx,xxx] //对应Hive表中的字段,顺序个数一致
perSql:["delete from xxx where dt=${dt}"] //当写入mysql50%失败了,下一次重新导入的时候,会执行这个sql,一般都是delete删除。
connection:[{
jdbcUrl:mysql的url, table:[表名]}]
}
真实例子:
{
"job": {
"setting": {
"speed": {
"channel": 3
}
},
"content": [{
"reader": {
"name": "hdfsreader",
"parameter": {
"path": "/user/hive/warehouse/ads.db/ads_low3_userdetail/dt=${dt}/dn=${dn}/*",
"defaultFS": "hdfs://mycluster",
"hadoopConfig":{
"dfs.nameservices": "mycluster",
"dfs.ha.namenodes.mycluster": "nn1,nn2,nn3",
"dfs.namenode.rpc-address.mycluster.nn1": "hadoop201:8020",
"dfs.namenode.rpc-address.mycluster.nn2": "hadoop202:8020",
"dfs.namenode.rpc-address.mycluster.nn3": "hadoop203:8020",
"dfs.client.failover.proxy.provider.mycluster": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
},
"column": [{
"index": 0,
"type": "string"
},
{
"index": 1,
"type": "string"
},
{
"index": 2,
"type": "string"
},
{
"index": 3,
"type": "string"
},
{
"value": "${dt}",
"type": "string"
},
{
"value": "${dn}",
"type": "string"
}
],
"fileType": "text",
"encoding": "UTF-8",
"fieldDelimiter": "\t"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "root",
"password": "000000",
"column": [
"paperviewid",
"paperviewname",
"score_segment",
"userids",
"dt",
"dn"
],
"preSql": [
"delete from paper_scoresegment_user where dt=${dt}"
],
"connection": [{
"jdbcUrl": "jdbc:mysql://hadoop201:3306/qz_paper?useUnicode=true&characterEncoding=utf8&serverTimezone=Asia/Shanghai&useSSL=false",
"table": [
"paper_scoresegment_user"
]
}]
}
}
}]
}
}
1.4 支持的Data Channel
| 类型 | 数据源 | Reader(读) | Writer(写) | 文档 |
|---|---|---|---|---|
| RDBMS 关系型数据库 | MySQL | √ | √ | 读 、写 |
| Oracle | √ | √ | 读 、写 | |
| SQLServer | √ | √ | 读 、写 | |
| PostgreSQL | √ | √ | 读 、写 | |
| DRDS | √ | √ | 读 、写 | |
| 通用RDBMS(支持所有关系型数据库) | √ | √ | 读 、写 | |
| 阿里云数仓数据存储 | ODPS | √ | √ | 读 、写 |
| ADS | √ | 写 | ||
| OSS | √ | √ | 读 、写 | |
| OCS | √ | √ | 读 、写 | |
| NoSQL数据存储 | OTS | √ | √ | 读 、写 |
| Hbase0.94 | √ | √ | 读 、写 | |
| Hbase1.1 | √ | √ | 读 、写 | |
| Phoenix4.x | √ | √ | 读 、写 | |
| Phoenix5.x | √ | √ | 读 、写 | |
| MongoDB | √ | √ | 读 、写 | |
| Hive | √ | √ | 读 、写 | |
| Cassandra | √ | √ | 读 、写 | |
| 无结构化数据存储 | TxtFile | √ | √ | 读 、写 |
| FTP | √ | √ | 读 、写 | |
| HDFS | √ | √ | 读 、写 | |
| Elasticsearch | √ | 写 | ||
| 时间序列数据库 | OpenTSDB | √ | 读 | |
| TSDB | √ | √ | 读 、写 |
Hive读详解地址:
https://github.com/alibaba/DataX/blob/master/hdfsreader/doc/hdfsreader.md
MySQL写详解地址:
https://github.com/alibaba/DataX/blob/master/mysqlwriter/doc/mysqlwriter.md
MySQL读详解地址:
https://github.com/alibaba/DataX/blob/master/mysqlreader/doc/mysqlreader.md
Hive写详解地址:
https://github.com/alibaba/DataX/blob/master/hdfswriter/doc/hdfswriter.md
1.5 DataX执行命令
https://github.com/alibaba/DataX/blob/master/userGuid.md
DataX执行命令通过python /opt/module/datax/bin/datax.py xxx.json -p “-D参数名1=参数值1 -D参数名2=参数值2”
python /opt/module/datax/bin/datax.py user_questiondetail.json -p "-Ddt=20190722 -Ddn=webA"
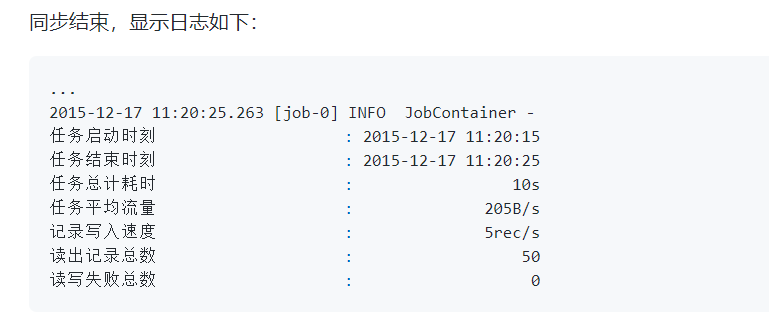
可以将执行命令封装到一个脚本中,同时执行多条传时命令
python /opt/module/datax/bin/datax.py avgtimeandscore.json -p "-Ddt=20190722 -Ddn=webA"
python /opt/module/datax/bin/datax.py low3_userdetail.json -p "-Ddt=20190722 -Ddn=webA"
python /opt/module/datax/bin/datax.py paper_maxdetail.json -p "-Ddt=20190722 -Ddn=webA"
python /opt/module/datax/bin/datax.py paper_scoresegment.json -p "-Ddt=20190722 -Ddn=webA"
python /opt/module/datax/bin/datax.py top3_userdetail.json -p "-Ddt=20190722 -Ddn=webA"
python /opt/module/datax/bin/datax.py user_paperdetail.json -p "-Ddt=20190722 -Ddn=webA"
python /opt/module/datax/bin/datax.py user_questiondetail.json -p "-Ddt=20190722 -Ddn=webA"