1 SparkSQL概述
Spark SQL是Spark用于结构化数据(structured data)处理的Spark模块
1.1 Spark的由来
Hive是早期唯一运行在Hadoop上的SQL-on-Hadoop工具 => 之后又出现:Drill、Impala、Shark
Spark的前身是Shark,Shark使得SQL-on-Hadoop的性能比Hive提高了10-100倍。
SparkSQL抛弃了Shark的代码,汲取了Shark的一些优点,性能得到极大提升:
- 数据兼容方面:Spark不仅兼容Hive,还可以从RDD、parquet文件、JSON文件获取数据。
- 性能优化方面:除了采用In-Memory Columnar Storage、byte-code generation等优化技术外、还将引进Cost Model对查询进行动态评估、获取最佳物理计划等。
- 组件拓展方面:SQL语法解析器、分析器还有优化器都可以重新定义、扩展。
Spark为了简化RDD的开发,提高编程开发效率,提供了两个编程抽象,类似于SparkCore种的RDD
- DataFrame
- DataSet
1.2 SparkSQL特点
-
易整合:整合了SQL查询和Spark编程
-
统一的数据访问:使用相同的方式连接不同的数据源
-
兼容Hive:在已有的仓库上直接运行SQL或HiveQL
-
标准数据连接:通过JDBC或者ODBC连接
1.3 DataFrame
DataFrame是一种以RDD为基础的分布式数据集,类似于传统数库中的二维表格。
扫描二维码关注公众号,回复: 12687134 查看本文章
Dataframe与RDD的区别在于:前者带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。
- DataFrame底层其实就是一种DataSet[Row]的DataSet

1.4 DataSet
DataSet是分布式数据集合,是DataFrame的扩展,是一个强类型集合。
就相当于一个封装的对象,对象的属性就是DataSet的结构。
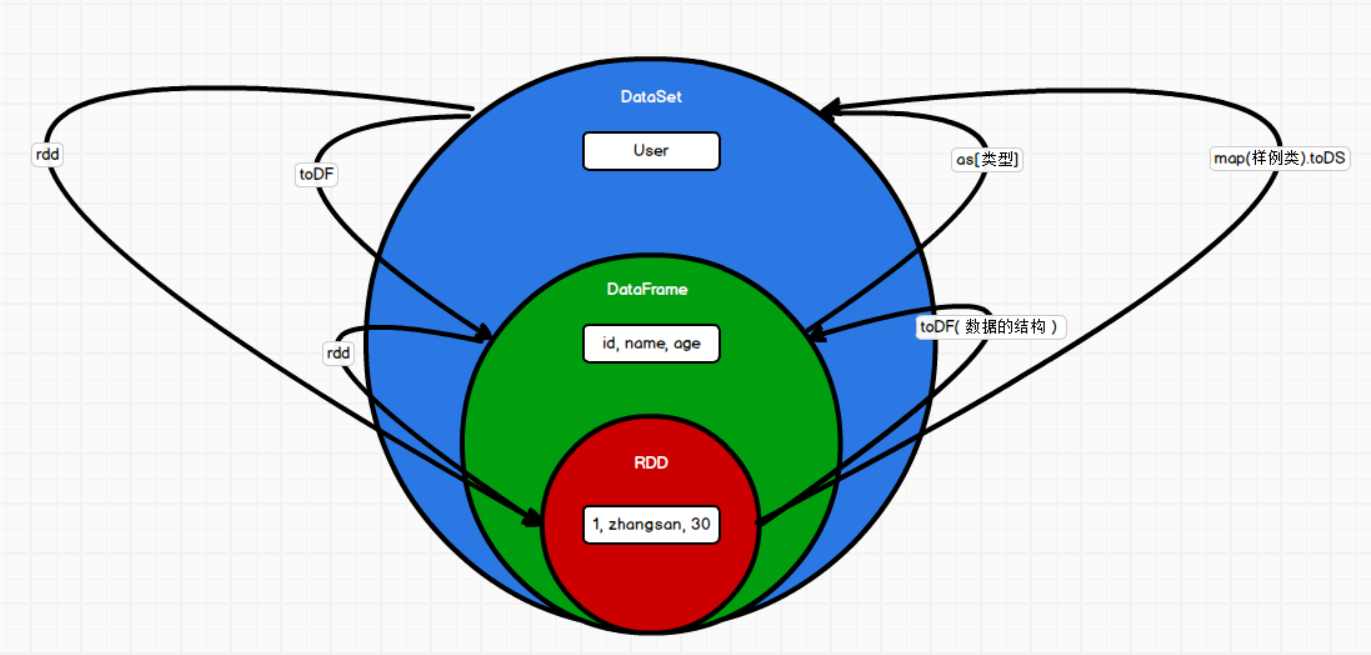
1.5 RDD & DataFrame & DataSet三者关系
1 三者出现的时间顺序:
Spark1.0 => RDD
Spark1.3 => DataFrame
Spark1.6 => DataSet
三者的共性
- RDD、DataFrame、DataSet全是spark平台下的分布式弹性数据集
- 三者都有惰性机制,在创建、转换不会立即执行,只有遇到action算子才会执行
- 三者有许多共同的函数:如filter、排序等
- 对DataFrame和DataSet操作都需要import spark.implicits._,在创建好的SparkSession对象后导入
- 三者都有partition的概念
- 三者都会根据spark的内存情况自动缓存运算,这样即使数据量很大,也不用担心内存溢出
- DataFrame和DataSet均可以使用模式匹配获取各个字段的值和类型
a、DataFrame是在RDD上进行扩展,将数据增加了结构信息
b、DataSet是在DataFrame的基础上进行扩展,增加数据的类型。
c、DataFrame是DataSet的一个特例,即为数据类型ROW的DataSet
三者相互转换:
2 SparkSQL核心编程
在SparkCore中如果执行应用程序需要先构建上下文环境对象SparkContext;
SparkSQL可以理解为对SparkCore的封装,不仅仅在RDD模型上进行了封装,上下文环境也进行了封装。
2.1 SparkSession
SparkSession内部封装了SparkContext,所以实际的计算是由SparkContext完成的。当我们使用spark-shell的时候,spark框架内部会创建一个名叫spark的SparkSession对象;就像前面的sc的SparkContext对象一样
2.2 DataFrame
①创建DataFrame
方式1:通过Spark数据源创建
步骤1:打开spark-shell.cmd,查看Spark支持创建文件的数据源格式

步骤2:在spark的bin/data目录中创建user.json文件
{"id":1, "name":"Tom", "age":24 }
{"id":2, "name":"Jerry", "age":34 }
{"id":3, "name":"Mike", "age":54 }
步骤3:读取json文件创建DataFrame
scala> spark.read.json("data/user.json")
res0: org.apache.spark.sql.DataFrame = [age: bigint, id: bigint ... 1 more field]
步骤4:展示结果:
scala> spark.read.json("data/user.json").show
+---+---+-----+
|age| id| name|
+---+---+-----+
| 24| 1| Tom|
| 34| 2|Jerry|
| 54| 3| Mike|
+---+---+-----+
方式2:从一个存在的RDD进行转换
方式3:从Hive Table查询返回
②SQL语法
SQL语法风格指查询数据的时候使用SQL语句查询,必须要有临时视图或者全局视图来辅助。
步骤1:读取JSON文件创建DataFrame
scala> val df = spark.read.json("data/user.json")
步骤2:对DataFrame创建一个临时表
scala> df.createOrReplaceTempView("people")
步骤3:通过SQL语句实现查询全表
scala> spark.sql("select * from people").show
+---+---+-----+
|age| id| name|
+---+---+-----+
| 24| 1| Tom|
| 34| 2|Jerry|
| 54| 3| Mike|
+---+---+-----+
//也可以将查询结果赋值给一个变量
scala> val sqlDF = spark.sql("select * from people")
sqlDF: org.apache.spark.sql.DataFrame = [age: bigint, id: bigint ... 1 more field]
scala> sqlDF.show
+---+---+-----+
|age| id| name|
+---+---+-----+
| 24| 1| Tom|
| 34| 2|Jerry|
| 54| 3| Mike|
+---+---+-----+
注意:普通临时表是Session范围内的,如果想应用范围内有效,可以使用全局临时表。
注意:使用全局临时表需要全路径访问,如:global_temp.people
步骤4:对DataFrame创建一个全局表
scala> df.createOrReplaceGlobalTempView("people1")
步骤5:通过SQL语句实现查询全表
scala> spark.sql("select * from global_temp.people1").show
+---+---+-----+
|age| id| name|
+---+---+-----+
| 24| 1| Tom|
| 34| 2|Jerry|
| 54| 3| Mike|
+---+---+-----+
步骤6:创建一个新的SparkSession查找表
scala> spark.newSession().sql("select * from global_temp.people1").show
+---+---+-----+
|age| id| name|
+---+---+-----+
| 24| 1| Tom|
| 34| 2|Jerry|
| 54| 3| Mike|
+---+---+-----+
③DSL语法
DataFrame提供了一个特定领域语言(domain-specific language, DSL)管理结构化的数据,可以在Scala,Java等中使用DSL,使用DSL就不用创建临时视图了。
步骤1:创建一个DataFrame
scala> val df = spark.read.json("data/user.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, id: bigint ... 1 more field]
步骤2:查看DataFrame的Schema信息
scala> df.printSchema
root
|-- age: long (nullable = true)
|-- id: long (nullable = true)
|-- name: string (nullable = true)
步骤3:只查看“name”列的信息
scala> df.select("name").show()
+-----+
| name|
+-----+
| Tom|
|Jerry|
| Mike|
+-----+
步骤4:查看“username”列数据以及“age+1”数据
涉及到运算的时候,每列都必须使用$,或者采用引号表达式:单引号+字段名
scala> df.select($"age"+1).show
scala> df.select('age+1).show
+---------+
|(age + 1)|
+---------+
| 25|
| 35|
| 55|
+---------+
步骤5:给列取别名
注意:使用$或者单引号+字段名,表示列中的每条数据,就不能和其他使用双引号的字段一起使用。
scala> df.select('name,'age+1 as "newage").show
+-----+------+
| name|newage|
+-----+------+
| Tom| 25|
|Jerry| 35|
| Mike| 55|
+-----+------+
步骤6:查看age大于30的数据
scala> df.filter('age>30).show
+---+---+-----+
|age| id| name|
+---+---+-----+
| 34| 2|Jerry|
| 54| 3| Mike|
+---+---+-----+
步骤7:按照age分组,查看数据条数
scala> df.groupBy("age").count.show
+---+-----+
|age|count|
+---+-----+
| 54| 1|
| 34| 1|
| 24| 1|
+---+-----+
④RDD转化为DataFrame
RDD.toDF()
在IDEA中开发程序时,如果需要RDD与DF和DS之间互相操作,那么需要引入import spark.implicits._
这里的spark不是Scala中的包名,而是创建sparkSession对象的变量名称,所以必须要创建SparkSession对象再导入。
spark对象不能使用var声明,因为Scala只支持val修饰的对象的导入。
scala> val idRDD = sc.makeRDD(List(1, 2, 3, 4))
idRDD: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[66] at makeRDD at <console>:24
scala> idRDD.toDF("id").show
+---+
| id|
+---+
| 1|
| 2|
| 3|
| 4|
+---+
实际开发中,一般通过样例类将RDD转换为DataFrame
scala> case class User(name:String,age:Int)
defined class User
scala> sc.makeRDD(List(("zhangsan", 30), ("lisi", 40))).map(t=>User(t._1,t._2)).toDF.show
+--------+---+
| name|age|
+--------+---+
|zhangsan| 30|
| lisi| 40|
+--------+---+
方式2:
scala> val df = sc.makeRDD(List(("zhangsan", 23), ("lisi", 45))).toDF("name", "age")
df: org.apache.spark.sql.DataFrame = [name: string, age: int]
scala> df.show
+--------+---+
| name|age|
+--------+---+
|zhangsan| 23|
| lisi| 45|
+--------+---+
⑤DataFrame转换为RDD
scala> val df = sc.makeRDD(List(("zhangsan",30), ("lisi",40))).map(t=>User(t._1, t._2)).toDF
df: org.apache.spark.sql.DataFrame = [name: string, age: int]
scala> val rdd = df.rdd
rdd: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[93] at rdd at <console>:25
scala> val array = rdd.collect
array: Array[org.apache.spark.sql.Row] = Array([zhangsan,30], [lisi,40])
注意:此时得到的RDD存储类型为Row
scala> array
res26: Array[org.apache.spark.sql.Row] = Array([zhangsan,30], [lisi,40])
scala> array(0)
res27: org.apache.spark.sql.Row = [zhangsan,30]
scala> array(0)(0)
res28: Any = zhangsan
2.3 DataSet
DataSet是强数据类型的数据集合,需要提供对应的类型信息
①创建DataSet
使用样例类序列创建DataSet
scala> case class Person(name:String, age:Long)
defined class Person
scala> val caseClassDS = Seq(Person("zhangsan", 22)).toDS()
caseClassDS: org.apache.spark.sql.Dataset[Person] = [name: string, age: bigint]
scala> caseClassDS.show
+--------+---+
| name|age|
+--------+---+
|zhangsan| 22|
+--------+---+
使用基本类型的序列创建DataSet
实际的使用中很少把序列转化成DataSet,更多的是通过RDD得到DataSet
scala> val ds = Seq(1, 2, 3, 4, 5).toDS
ds: org.apache.spark.sql.Dataset[Int] = [value: int]
scala> ds.show
+-----+
|value|
+-----+
| 1|
| 2|
| 3|
| 4|
| 5|
+-----+
②RDD转换为DataSet
SparkSQL能够自动将包含有case类的RDD转换成DataSet,case类定义了table结构,case类属性通过反射变成了表的列名。
scala> val ds = sc.makeRDD(List(("zhangsan", 30), ("lisi", 49))).map(t=>User(t._1, t._2)).toDS
ds: org.apache.spark.sql.Dataset[User] = [name: string, age: int]
scala> ds.show
+--------+---+
| name|age|
+--------+---+
|zhangsan| 30|
| lisi| 49|
+--------+---+
③DataSet转换为RDD
scala> val ds = sc.makeRDD(List(("zhangsan", 30), ("lisi", 49))).map(t=>User(t._1, t._2)).toDS
scala> val rdd = ds.rdd
rdd: org.apache.spark.rdd.RDD[User] = MapPartitionsRDD[103] at rdd at <console>:25
scala> rdd.collect
res34: Array[User] = Array(User(zhangsan,30), User(lisi,49))
④DataFrame和DataSet转换
DataFrame转换成DataSet
scala> val df = sc.makeRDD(List(("zhangsan", 23), ("lisi", 45))).toDF("name", "age")
df: org.apache.spark.sql.DataFrame = [name: string, age: int]
scala> val ds = df.as[User]
ds: org.apache.spark.sql.Dataset[User] = [name: string, age: int]
DataSet转换成DataFrame
scala> val df = ds.toDF
df: org.apache.spark.sql.DataFrame = [name: string, age: int]
2.4 三者的转换
-
转换成RDD:
DF.rdd
DS.rdd
-
转换成DataFrame
RDD.toDF(数据的结构) RDD.map(t=>样例类属性).toDF
DS.toDF()
-
转换成DataSet
RDD.map(t=>样例类属性).toDS
DF.as[类型]
2.5 IDEA开发SparkSQL
①添加依赖
spark-core和spark-sql
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>
②创建SparkSQL环境
SparkSession的对象不是new出来的,是通过SparkSession的伴生对象.builder()的getOrCreate()构建环境对象。
另外是哪一个环境,还需要SparkConf()环境和appname
方式1:
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("sparkSQL").getOrCreate()
方式2:
val conf = new SparkConf().setMaster("local").setAppName("spark-sql")
val spark = SparkSession.builder().config(conf).getOrCreate()
创建Spark环境后,一般情况要导入spark的implicits._
主要目的是为了使用DSL语法的时候可以使用sparkSQL的隐式转换;提供RDD转DataFrame等的方法
//创建spark环境
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("sparkSQL").getOrCreate()
//这里的spark不是包名,而是SparkSession的对象名
//一般情况下,需要在创建SparkSession对象后,增加导入
import spark.implicits._
spark提供了一个sparkContext变量,可以获取SparkContext对象
可以通过这个sc对象创建RDD
val sc = spark.sparkContext
③读取文件创建DataFrame
//TODO DataFrame
//创建的JSON文件中的整个文件的数据应该符合JSON的语法规则
//RDD读取文件的时候是一行一行读取的,所以SparkSQL读取JSON文件时,要求一行数据符合JSON格式即可
val df = spark.read.json("input/users.json")
df.show()
④SQL语法 & DSL语法
//SQL
df.createOrReplaceTempView("user")
spark.sql("select * from user").show()
spark.sql("select avg(age) as newAge from user").show()
//DSL
//DSL语法需要在当前环境中引入SparkSQL的隐式转换规则
df.select("id", "name").show()
df.select('name, 'age + 1).show()
df.select($"age" + 1).show()
//使用DSL查询表中全部数据
df.select('*).show()
⑤创建DataSet
//TODO DataSet
val seq = Seq(1, 2, 3, 4)
val ds: Dataset[Int] = seq.toDS()
val list = List("1", "2", "3")
val ds1 = list.toDS()
ds.show()
ds1.show()
val list1 = List((1, "zhangsan", 23), (2, "lisi", 33))
val rdd = spark.sparkContext.makeRDD(list1)
rdd.map{
case (id, name, age) => User(id, name, age)
}.toDS().show()
⑥RDD & DataFrame & DataSet
RDD
//TODO RDD转DataFrame
val rdd: RDD[(Int, String, Int)] = spark.sparkContext.makeRDD(List((1, "zhangsan", 23), (2, "lisi", 45)))
val df = rdd.toDF("id", "name", "age")
df.show()
//TODO RDD转DataSet
val ds = rdd.toDS() //这样直接转,没有字段名
ds.show()
rdd.map{
case (id, name, age) => User(id, name, age)
}.toDS().show() //通过map+模式匹配可以添加字段名
DataFrame
//TODO DataFrame转RDD
val df = spark.read.json("input/users.json")
val rdd = df.rdd
rdd.foreach(println)
//TODO DataFrame转DataSet
val ds: Dataset[User] = df.as[User]
ds.show() //注意这里的类型!需要将int改成bigInt才对!
DataSet
//TODO DataSet转RDD
val rdd: RDD[(Int, String, Int)] = spark.sparkContext.makeRDD(List((1, "zhangsan", 23), (2, "lisi", 43)))
val ds: Dataset[User] = rdd.map {
case (id, name, age) => User(id, name, age)
}.toDS()
val rdd1 = ds.rdd
rdd1.foreach(println)
//TODO DataSet转DataFrame
ds.toDF().show()
ds.toDF("id1", "name1", "age1").show()
2.6 用户自定义函数
①UDF
来一行处理一行
object SparkSql05_udf {
def main(args: Array[String]): Unit = {
//1 创建spark环境
val conf = new SparkConf().setMaster("local").setAppName("spark-sql")
val spark = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._
//2 读取json文件,创建DataFrame
val df: DataFrame = spark.read.json("input/users.json")
//3 创建临时视图
df.createOrReplaceTempView("user")
//4 TODO 注册udf自定义函数
spark.udf.register("prefixName", (name:String) => {
"Name : " + name})
//5 TODO 使用udf自定义函数
spark.sql("select prefixName(name) from user").show()
//6 关闭环境
spark.stop()
}
②UDAF-弱类型
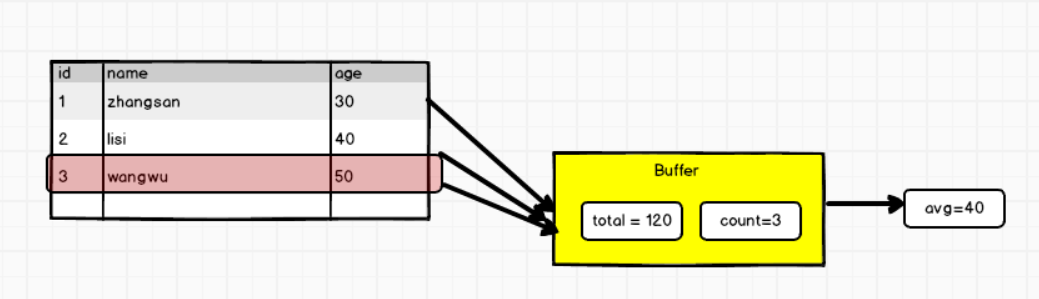
计算平均工资
弱类型的UserDefinedAggregateFunction已经过时了,Spark3.0以后就使用强类型的Aggregator替代了。
@deprecated("Aggregator[IN, BUF, OUT] should now be registered as a UDF" + " via the functions.udaf(agg) method.", "3.0.0")
spark3.0之前的弱类型的UDAF,需要实现UserDefinedAggregateFunction,不需要定义泛型,只需要重写8个方法就可以了
object SparkSql06_udaf {
def main(args: Array[String]): Unit = {
//1 创建spark环境
val conf = new SparkConf().setMaster("local").setAppName("spark-sql")
val spark = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._
//2 读取json文件,创建DataFrame
val df: DataFrame = spark.read.json("input/users.json")
//3 创建临时视图
df.createOrReplaceTempView("user")
//5 创建聚合函数
val udaf = new MyAvg
//6 TODO 注册UDAF函数
spark.udf.register("myAvg", udaf)
//UDF函数称之为用户自定义函数,但是这个函数不能聚合,只能对每一条进行处理
// zhangsan => "Name : zhangsan"
//4 如果想使用sql完成聚合功能,那么必须采用特殊的函数:用户自定义聚合函数UDAF
spark.sql("select myAvg(age) from user").show()
//关闭环境
spark.stop()
}
// 自定义年龄平均值的聚合函数
// 继承UserDefinedAggregateFunction类
// 重写方法
class MyAvg extends UserDefinedAggregateFunction{
//输入数据的结构(年龄)
override def inputSchema: StructType = {
StructType(Array(StructField("age", LongType)))
}
// 缓冲区数据的结构(年龄总和,用户的数量)
override def bufferSchema: StructType = {
StructType(Array(
StructField("total", LongType),
StructField("count", LongType)
))
}
// 聚合函数的输出结构类型
override def dataType: DataType = LongType
//稳定性
override def deterministic: Boolean = true
//缓冲区初始化操作
override def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer.update(0, 0L)
buffer.update(1, 0L)
}
//用户输入的值更新缓冲区的值
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
buffer.update(0, buffer.getLong(0) + input.getLong(0))
buffer.update(1, buffer.getLong(1) + 1)
}
//合并缓冲区的数据;这是因为分布式计算
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1.update(0, buffer1.getLong(0) + buffer2.getLong(0))
buffer1.update(1, buffer1.getLong(1) + buffer2.getLong(1))
}
//计算聚合函数的结果
override def evaluate(buffer: Row): Any = {
buffer.getLong(0) / buffer.getLong(1)
}
}
}
③UDAF-强类型
object SparkSql08_udaf {
def main(args: Array[String]): Unit = {
//创建spark环境
val spark = SparkSession.builder().master("local[*]").appName("spark-sql").getOrCreate()
import spark.implicits._
//读取文件创建df
val df = spark.read.json("input/users.json")
//创建临时表
df.createOrReplaceTempView("user")
//TODO 创建自定义聚合函数
val myAvg = new myAvg()
//TODO 向spark注册函数
spark.udf.register("myAvg", functions.udaf(myAvg))
//TODO SQL本身就是弱类型操作,支持弱类型的聚合函数,不能直接支持强类型的聚合函数
// 需要使用functions.udaf()
//使用SQL语法,查询平均年龄
spark.sql("select myAvg(age) from user").show()
//关闭环境
spark.stop()
}
case class AvgBuffer(var total: Long, var count: Long)
//TODO 自定义年龄平均值的聚合函数(强类型)
// 1. 继承org.apache.spark.sql.expressions.Aggregator
// 2. 定义泛型
// IN:年龄-Long
// BUF:AvgBuffer
// OUT:平均年龄-Long
class myAvg extends Aggregator[Long, AvgBuffer, Long]{
//缓冲区的初始化操作
override def zero: AvgBuffer = {
AvgBuffer(0L, 0L)
}
//将年龄数据和缓冲区的数据进行聚合
override def reduce(b: AvgBuffer, a: Long): AvgBuffer = {
b.total += a
b.count += 1
b
}
//分布式下的多个缓冲区合并
override def merge(b1: AvgBuffer, b2: AvgBuffer): AvgBuffer = {
b1.total += b2.total
b1.count += b2.count
b1
}
//计算结果
override def finish(reduction: AvgBuffer): Long = {
reduction.total / reduction.count
}
//这两个是固定值
override def bufferEncoder: Encoder[AvgBuffer] = Encoders.product
override def outputEncoder: Encoder[Long] = Encoders.scalaLong
}
}
④UDAF-强类型(早期版本)
Spark3.0版本之前,虽然也能使用Aggregator(),但是无法将强类型的聚合函数使用在SQL语法中。
那么哪个时候怎么自定义聚合函数呢?
- 方式1:使用弱类型的UserDefinedAggregateFunction
- 方式2:将数据的一行当成对象传递给聚合函数,然后使用DSL语法,将聚合函数转换成查询列。
object SparkSql09_udaf_1 {
def main(args: Array[String]): Unit = {
//创建spark环境
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("sparkSQL-udaf").getOrCreate()
import spark.implicits._
//读取文件创建df
val df = spark.read.json("input/users.json")
//创建临时视图
df.createOrReplaceTempView("user")
//需求:计算平均工资
//TODO 创建自定义聚合函数
val myAvg = new MyAvg
//TODO 使用DSL语法将聚合函数转换成查询列
val ds: Dataset[User] = df.as[User]
ds.select(myAvg.toColumn).show()
//spark.sql("select myAvg(age) from user").show()
//TODO Spark3.0版本之前,无法将强类型聚合函数使用在SQL文中
// 那么哪个时候怎么做的呢?方式1:使用弱类型的UserDefinedAggregateFunction
// 方式2:将数据的一行当成对象传递给聚合函数,使用DSL语法查询
//关闭环境
spark.stop()
}
case class User(id: Long, name: String, age: Long)
case class AvgBuffer(var total: Long, var count: Long)
//TODO 自定义年龄平均值的聚合函数(3.0版本以前的强类型)
// 1. 继承Aggregator :org.apache.spark.sql.expressions.Aggregator
// 2. 定义泛型
// IN:User(将一行数据作为输入)
// BUF:AvgBuffer
// OUT:Long
// 3. 重写方法
class MyAvg extends Aggregator[User, AvgBuffer, Long]{
//缓冲区初始化
override def zero: AvgBuffer = {
AvgBuffer(0L, 0L)
}
//输入的年龄和缓冲区聚合
override def reduce(b: AvgBuffer, user: User): AvgBuffer = {
b.total += user.age
b.count +=1
b
}
//分布式多个缓冲区的合并
override def merge(b1: AvgBuffer, b2: AvgBuffer): AvgBuffer = {
b1.total += b2.total
b1.count += b2.count
b1
}
//返回计算的结果
override def finish(reduction: AvgBuffer): Long = {
reduction.total / reduction.count
}
//默认的两个值
override def bufferEncoder: Encoder[AvgBuffer] = Encoders.product
override def outputEncoder: Encoder[Long] = Encoders.scalaLong
}
}
2.7 数据的加载和保存
SparkSQL提供了通用API的保存数据和加载数据的方式。
spark提供的文件
①加载数据
spark.read.load是加载数据的通用方法
spark.read.load默认加载的数据格式为:parquet
如果文件格式读取错误,会报下面的错误。
scala> spark.read.load("examples/src/main/resources/users.parquet").show
+------+--------------+----------------+
| name|favorite_color|favorite_numbers|
+------+--------------+----------------+
|Alyssa| null| [3, 9, 15, 20]|
| Ben| red| []|
+------+--------------+----------------+
Caused by: java.lang.RuntimeException: file:/opt/module/spark-local/data/user.json is not a Parquet file. expected magic number at tail [80, 65, 82, 49] but found [51, 48, 125, 10]
按照文件的格式读取数据:
- format("…"):指定加载的数据类型,包括"csv"、“jdbc”、“json”、“orc”、“parquet"和"textFile”
- load("…"):在"csv"、“jdbc”、“json”、“orc”、"parquet"和"textFile"格式下需要传入加载数据的路径
scala> spark.read.format("json").load("data/user.json").show
+---+---+--------+
|age| id|username|
+---+---+--------+
| 20| 1|zhangsan|
| 24| 2| lisi|
| 40| 3| wangwu|
| 30| 4| zhaoliu|
+---+---+--------+
直接在文件上进行查询:文件格式. `文件路径
scala> spark.sql("select * from json.`/opt/module/spark-local/data/user.json`").show
+---+---+--------+
|age| id|username|
+---+---+--------+
| 20| 1|zhangsan|
| 24| 2| lisi|
| 40| 3| wangwu|
| 30| 4| zhaoliu|
+---+---+--------+
②保存数据
scala> var df = spark.read.format("json").load("data/user.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, id: bigint ... 1 more field]
scala> df.write.
bucketBy csv format insertInto jdbc json mode option options orc parquet partitionBy save saveAsTable sortBy text
spark的保存数据的通用:df.write.save(“输出路径”)
- save ("…"):在"csv"、“orc”、"parquet"和"textFile"格式下需要传入保存数据的路径
scala> df.write.save("data/output")
[atguigu@hadoop102 output]$ ll
总用量 4
-rw-r--r--. 1 atguigu atguigu 969 12月 1 21:01 part-00000-b97909ab-e827-41bc-9a90-1b2784529339-c000.snappy.parquet
-rw-r--r--. 1 atguigu atguigu 0 12月 1 21:01 _SUCCESS
spark保存为指定的文件类型
format("…"):指定保存的数据类型,包括"csv"、“jdbc”、“json”、“orc”、“parquet"和"textFile”
scala> df.write.format("json").save("data/output1")
atguigu@hadoop102 output1]$ ll
总用量 4
-rw-r--r--. 1 atguigu atguigu 153 12月 1 21:04 part-00000-1f990b58-3a9e-4d0a-be95-71ce27deb5a0-c000.json
-rw-r--r--. 1 atguigu atguigu 0 12月 1 21:04 _SUCCESS
保存路径的文件保存模式
因为默认情况下,save保存的路径文件如果存在了,会报错;可以加上.mode(“模式“);当存在相同文件可以追加,覆盖,忽略等。
SaveMode是一个枚举类,其中的常量包括:
| Scala/Java | Any Language | Meaning |
|---|---|---|
| SaveMode.ErrorIfExists(default) | “error”(default) | 如果文件已经存在则抛出异常 |
| SaveMode.Append | “append” | 如果文件已经存在则追加 |
| SaveMode.Overwrite | “overwrite” | 如果文件已经存在则覆盖 |
| SaveMode.Ignore | “ignore” | 如果文件已经存在则忽略 |
scala> df.write.format("csv").mode("append").save("data/output1")
[atguigu@hadoop102 output1]$ ll
总用量 8
-rw-r--r--. 1 atguigu atguigu 153 12月 1 21:04 part-00000-1f990b58-3a9e-4d0a-be95-71ce27deb5a0-c000.json
-rw-r--r--. 1 atguigu atguigu 49 12月 1 21:11 part-00000-b83d3429-0531-42db-b347-d582d6bcd82d-c000.csv
-rw-r--r--. 1 atguigu atguigu 0 12月 1 21:11 _SUCCESS
③Parquet
Spark SQL默认数据源为Parquet格式,Parquet是一种能够有效存储嵌套数据的列式存储格式。
- 数据源为Parquet文件时,SparkSQL可以方便的执行所有的操作,不需要使用format。
- 修改配置项spark.sql.sources.default可以修改默认的数据源格式
加载数据
scala> spark.read.load("/opt/module/spark-local/examples/src/main/resources/users.parquet").show
+------+--------------+----------------+
| name|favorite_color|favorite_numbers|
+------+--------------+----------------+
|Alyssa| null| [3, 9, 15, 20]|
| Ben| red| []|
+------+--------------+----------------+
保存数据
scala> var df = spark.read.json("/opt/module/data/input/people.json")
//保存为parquet格式
scala> df.write.mode("append").save("/opt/module/data/output")
④JSON
Spark SQL 能够自动推测JSON数据集的结构,并将它加载为一个Dataset[Row]. 可以通过SparkSession.read.json()去加载JSON 文件
- Spark读取的JSON文件不是传统的JSON文件,每一行都应该是一个JSON串。
步骤1:导入隐式转换
import spark.implicits._
步骤2:加载JSON文件
val path = "/opt/module/spark-local/people.json"
val peopleDF = spark.read.json(path)
步骤3:创建临时表
peopleDF.createOrReplaceTempView("people")
步骤4:数据查询
val teenagerNamesDF = spark.sql("SELECT name FROM people WHERE age BETWEEN 13 AND 19")
teenagerNamesDF.show()
+------+
| name|
+------+
|Justin|
+------+
⑤CSV
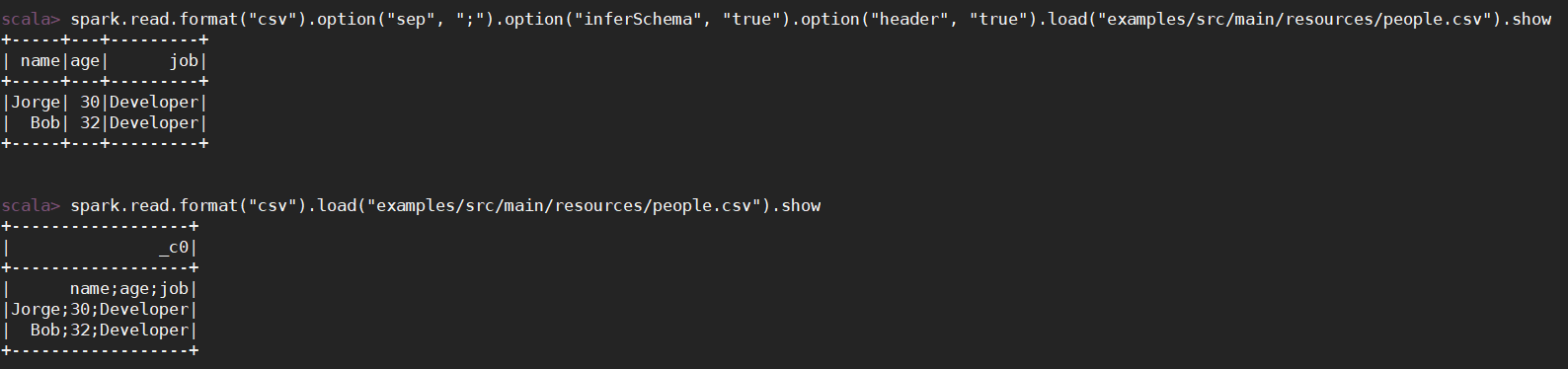
csv是通过,分割的;单纯的读取csv格式的文件,会把标题字段也当作是一行数据读取。
如果要正常的读取数据,需要通过option选项设定分隔符seq;inferSchema;header设为true表示有头信息,也就是标题。
scala> spark.read.format("csv").load("examples/src/main/resources/people.csv").show
+------------------+
| _c0|
+------------------+
| name;age;job|
|Jorge;30;Developer|
| Bob;32;Developer|
+------------------+
scala> spark.read.format("csv").option("sep", ";").option("inferSchema", "true").option("header", "true").load("examples/src/main/resources/people.csv").show
+-----+---+---------+
| name|age| job|
+-----+---+---------+
|Jorge| 30|Developer|
| Bob| 32|Developer|
+-----+---+---------+
⑥MySQL
SparkSQL可以通过JDBC从关系型数据库中读取数据的方式创建DataFrame。需要在启动spark-shell的之前,把mysql-connector-java-5.1.27-bin.jar的jar包放到/opt/module/spark-local/jars下。
步骤1:提前在hadoop102的mysql中创建表
CREATE DATABASE `spark-sql`;
CREATE TABLE USER(id INT, NAME VARCHAR(20), age INT);
INSERT INTO USER VALUES(1, "zhangsan", 23);
INSERT INTO `user` VALUES(2, "lisi", 45);
步骤2:通过option去设置连接MySQL的url,driver驱动类,登录的用户名,密码,表名等。
scala> spark.read.format("jdbc").option("url", "jdbc:mysql://hadoop102:3306/spark-sql").option("driver", "com.mysql.jdbc.Driver").option("user", "root").option("password", "123456").option("dbtable", "user").load().show
+---+--------+---+
| id| name|age|
+---+--------+---+
| 1|zhangsan| 23|
| 2| lisi| 45|
+---+--------+---+
步骤3:向MySQL中写入数据
然后在mysql中就能查看到新增的数据
scala> val df = sc.makeRDD(List((3, "Tom", 88))).toDF("id", "name", "age")
df: org.apache.spark.sql.DataFrame = [id: int, name: string ... 1 more field]
scala> df.write.format("jdbc").option("url", "jdbc:mysql://hadoop102:3306/spark-sql").option("user", "root").option("password", "123456").option("dbtable", "user").mode("append").save
⑦Hive
内嵌的Hive
Hive 的元数据存储在 derby 中, 默认仓库地址:$SPARK_HOME/spark-warehouse
初次使用spark-sql,用到hive的时候,会自动在SPARK_HOME创建saprk的warehouse,和metastore_db
在实际使用中, 几乎没有任何人会使用内置的 Hive
scala> spark.sql("show tables").show
。。。
+--------+---------+-----------+
|database|tableName|isTemporary|
+--------+---------+-----------+
+--------+---------+-----------+
scala> spark.sql("create table aa(id int)")
。。。
scala> spark.sql("show tables").show
+--------+---------+-----------+
|database|tableName|isTemporary|
+--------+---------+-----------+
| default| aa| false|
+--------+---------+-----------+
向表加载本地数据
scala> spark.sql("load data local inpath 'input/ids.txt' into table aa")
。。。
scala> spark.sql("select * from aa").show
+---+
| id|
+---+
| 1|
| 2|
| 3|
| 4|
+---+
外部的Hive
- 步骤1:Spark接管Hive需要将hive-site.xml拷贝到spark-local的conf/文件下
- 步骤2:把MySQL的驱动拷贝到jars/目录下
- 步骤3:如果访问不到hdfs,则需要把core-site.xml和hdfs.site.xml拷贝到conf/目录下
- 步骤4:重启spark-shell
在IDEA中使用外部的Hive创建库,创建表,导入数据
步骤1:导入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.27</version>
</dependency>
步骤2:将hive-site.xml文件拷贝到项目的resources目录中。
步骤3:代码实现
- 在代码的最前面指定代理用户: System.setProperty(“HADOOP_USER_NAME”, “atguigu”)
- 修改数据仓库地址:.config(“spark.sql.warehouse.dir”,“hdfs://hadoop102:8020/user/hive/warehouse”)
- **添加Hive支持!**enableHiveSupport()
object SparkSql10_hive {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "atguigu")
//创建spark环境
val conf = new SparkConf().setMaster("local[*]").setAppName("spark-sql")
val spark = SparkSession.builder().enableHiveSupport().config(conf).config("spark.sql.warehouse.dir",
"hdfs://hadoop102:8020/user/hive/warehouse").getOrCreate()
spark.sql("use hive_db")
spark.sql(
"""
|CREATE TABLE `user_visit_action`(
| `date` string,
| `user_id` bigint,
| `session_id` string,
| `page_id` bigint,
| `action_time` string,
| `search_keyword` string,
| `click_category_id` bigint,
| `click_product_id` bigint,
| `order_category_ids` string,
| `order_product_ids` string,
| `pay_category_ids` string,
| `pay_product_ids` string,
| `city_id` bigint)
|row format delimited fields terminated by '\t'
|""".stripMargin)
spark.sql(
"""
|load data local inpath 'input/user_visit_action.txt' into table hive_db.user_visit_action
|""".stripMargin)
spark.sql(
"""
|CREATE TABLE `product_info`(
| `product_id` bigint,
| `product_name` string,
| `extend_info` string)
|row format delimited fields terminated by '\t'
|""".stripMargin)
spark.sql(
"""
|load data local inpath 'input/product_info.txt' into table hive_db.product_info
|""".stripMargin)
spark.sql(
"""
|CREATE TABLE `city_info`(
| `city_id` bigint,
| `city_name` string,
| `area` string)
|row format delimited fields terminated by '\t'
|""".stripMargin)
spark.sql(
"""
|load data local inpath 'input/city_info.txt' into table hive_db.city_info
|""".stripMargin)
//关闭环境
spark.stop()
}
}
运行SparkSQL CLI
[atguigu@hadoop102 jars]$ cd /opt/module/spark-local/
[atguigu@hadoop102 spark-local]$ bin/spark-sql
spark-sql (default)>