寒假OS学习第四天
hurlex学习——添加全局段描述符表
接下来将进入x86保护模式编程的一些细节。
从80386处理器开始,CPU有了四种运行模式
- 实模式
- 保护模式
- 虚拟8086模式
- SMM模式工作模式是指CPU的寻址方式、寄存器大小等。
几种模式
CPU的实模式
在8086时代,CPU以实模式运行
CPU刚刚上电后,也以实模式启动
参考资料:
https://zhuanlan.zhihu.com/p/42309472
https://baike.baidu.com/item/%E5%AE%9E%E6%A8%A1%E5%BC%8F/7354531?fr=aladdin
https://www.jianshu.com/p/d39cf99b5ed7
(最开始的时候,CPU一共只有20位地址线、8个16位的段寄存器)
实模式下,内存寻址方式由16位寄存器的内容乘以10H当作段基地址(由段寄存器提供),加上16位偏移地址形成20位物理地址(段基址:段偏移量)。最大寻址空间1MB,最大分段64KB,可以使用32位指令。
段寄存器一共有6种:
CS、DS、SS、ES、FS、GS
段寄存器
段寄存器是因为对内存的分段管理而设置的。计算机需要对内存分段,以分配给不同的程序使用。
在进行内存分段时,需要以下信息:
- 段的大小
- 段的起始地址
- 段的属性
需要使用8个字节即64位存储这些信息
段寄存器只有16位,因此,段寄存器只能存储segment selector,由其映射到存在内存中的全局段号记录表(GDT)来读取段的信息。
CS是代码段。指向存放程序的内存。IP是存放下条待执行指令的偏移量,合在一起就是下条指令位置。
偏移量由通用寄存器提供,也是16位。
物理地址=段地址<<4+段内偏移
DS是数据段。缺省。
SS是堆栈段。指向堆栈的内存段基地址,SP指向该堆栈的栈顶,合在一起可以访问栈顶单元。加上BP可以访问整个堆栈。
ES是附加段。串操作指令中目的串所在的段。
将内存分段后,每个段都有一个段基址,段寄存器保存这个段基址的高16位,16位段基址左移4位后可以构成20位的段基址。
FS和GS没有定义,由操作系统赋予它们目的。
实模式之所以称之为实模式,是因为它的物理地址是真实的。
任意程序可以修改任意地址的变量
保护模式
随着CPU的发展,实模式下的内存地址计算方式不再适用。
保护模式能提供更大的空间、更灵活、更安全的内存访问。
内存寻址方式需要兼容老办法,即(段基址、段偏移量)。
这个时候CPU内的通用寄存器全部换为32位,但是段寄存器还是16位的。
偏移值和实模式下一样,仍然由通用寄存器提供,只是大小变成了32位。
将关于内存段的限制信息放在GDT即全局描述符表中,里面的每一个项称之为段描述符。
段寄存器在保护模式下存放的东西类似于数组索引。
使用专用寄存器GDTR指向全局描述符表。
GDTR的结构:0-15存放GDT的长度,16-47存放基址。
一个段描述符只能用来定义一个内存段。
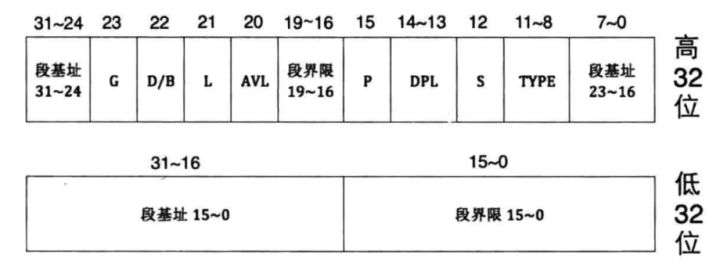
段界限:段边界扩张法最值,即最大扩展多少、最小扩展多少。它的单位由G决定,G=1时单位为4KB,G=0时单位为字节。
实际段界限边界值 = (段界限+1) * 单位大小 - 1
若偏移地址超过段界限,则会报错
此时的段寄存器内存储的是一个“选择子”
选择子的0-2位是RPL,描述特权级别
3位是TI,TI=0表示在GDT中索引,TI=1表示在LDT中索引
3-15位是描述符索引值
保护模式下,程序不能随心所欲地修改任意地址的变量
虚拟8086模式
用于在保护模式下运行16位代码
SMM模式
不对程序员开放,不关心
如何进入保护模式
CPU内部有5个32位的控制寄存器:CR0-CR3,CR8
CR0:含有控制CPU操作模式和状态的标识
CR1:保留不用
CR2:存储导致页错误的线性地址
CR3:含有页目录表的物理内存基址
CR0中的保护控制位:PE
PE设置->开启了保护模式
PG设置->开启分页机制(PE、PG都要设置)
CPU一进入保护模式立刻按照保护模式寻址,这要求我们要在CPU进入保护模式前放好GDT
我们的内核刚刚启动时,机器的状态是这样的:
eax 0x2badb002 732803074
ecx 0x1c300 115456
edx 0x2be00 179712
ebx 0x2bd20 179488
esp 0x7ffc 0x7ffc
ebp 0x0 0x0
esi 0x2be78 179832
edi 0x80 128
eip 0x10051f 0x10051f <kern_entry>
eflags 0x6 [ PF ]
cs 0x8 8
ss 0x10 16
ds 0x10 16
es 0x10 16
fs 0x10 16
gs 0x10 16
在实模式下,CPU只有1MB的寻址空间,所以相当于GDT被限制在这里了
GRUB在载入内核后,CS指向基地址为0x0、长度为4G-1的代码描述符,DS指向了基地址为0x0、长度为1的数据段描述符
也就是,GRUB载入后,已经进入了平坦模式。
分段策略
分段是intel的CPU一致保持的一种机制,分页只是保护模式下的一种机制
如何绕过分段直接使用分页?
使用平坦模式,即将整个内存作为一个分段。
当整个虚拟空间为一个起始地址为0、限长为4G的段时,给出的偏移地址就在数值上等于段机制处理后的地址了。
因此,此时计算机可以兼容实模式
在GRUB引导后,我们的计算机已经进入了保护模式了
@ring: 0
cs = 0x8
ss = 0x10
ds = 0x10
es = 0x10
但是我们仍然需要再来一次,一个是学习,另一个是后期还要用到
实践
首先需要构建数据类型
根据我们上面的介绍,构建如下的数据结构
// 定义GDT结构
typedef struct
{
/* 低32位 */
uint16_t limit_low;
uint16_t base_low;
/* 高32位 */
uint8_t base_mid;
uint8_t access; // 具体的值需要看Intel手册
uint8_t
limit_high:4,
granularity:4;
uint8_t base_high;
}gdt_t;
typedef struct
{
uint16_t limit;
uint32_t base;
}__attribute__((packed))gdtr_t;
注意第二个结构体的__attribute__属性!特别重要
没有加上这个属性,结构体大小为64,加上这个属性,结构体大小为48,差了特别多!
其次,让我们构建初始化GDT的函数
#define GDT_LEN 5
static gdt_t gdt[GDT_LEN];
static gdtr_t gdtr;
static void gdt_set(int num, uint32_t base,
uint32_t limit, uint8_t access, uint8_t gran);
void
init_gdt()
{
gdtr.limit = sizeof(gdt) * GDT_LEN - 1;
gdtr.base = (uint32_t)gdt;
gdt_set(0, 0, 0, 0, 0); // 规定——第一个符号表为0
gdt_set(1, 0, 0xFFFFFFFF, 0x9A, 0xC); // 指令段
gdt_set(2, 0, 0xFFFFFFFF, 0x92, 0xC); // 数据段
gdt_set(3, 0, 0xFFFFFFFF, 0xFA, 0xC); // 用户模式,指令段
gdt_set(4, 0, 0xFFFFFFFF, 0xF2, 0xC); // 用户模式,数据段
for (int i = 0; i < 5; i ++)
printk("%d, %x, %x\n", i, gdt[i].limit_high, gdt[i].granularity);
gdt_flush((uint32_t)&gdtr);
}
static void
gdt_set(int num, uint32_t base,
uint32_t limit, uint8_t access, uint8_t gran)
{
gdt[num].base_low = base & 0xFFFF;
gdt[num].base_mid = (base >> 16) & 0xFF;
gdt[num].base_high = (base >> 24) & 0xFF;
gdt[num].limit_low = limit & 0xFFFF;
gdt[num].limit_high = (limit >> 16) & 0x0F;
// gdt[num].granularity = (limit >> 16) & 0x0F;
gdt[num].granularity = gran;
gdt[num].access = access;
}
这里的gdt_flush负责更新GDRT
这个操作只能使用汇编完成
[GLOBAL gdt_flush]
gdt_flush:
mov eax, [esp + 4]
lgdt [eax]
mov ax, 0x10
mov ss, ax
mov ds, ax
mov gs, ax
mov es, ax
mov fs, ax
jmp 0x08:.flush
.flush:
ret
注意这个jmp语句:
此处的jmp有两个作用
- 刷新CS寄存器
- 刷新高速缓存与流水线
这是NASM里面的远跳转的写法