CSAPP期末快速复习(更新ing)
本人有关CSAPP的博客链接:
私人博客
CSDN
内容基本上差不多
主要内容
概论
- 上下文:上下文是一个状态,包含运行进程所需的所有状态信息,进程切换通过切换上下文完成
- 编译过程(链接中会再次提到):源程序 预处理-> 文本 编译->汇编程序 汇编->可重定位目标文件 链接->可执行文件
- 指令集架构:每条机器代码的效果。微体系结构:处理器的具体实现
- 存储器层次结构:从上至下,访问速度越来越慢,容量越来越大。课本P10图。
- 操作系统:是应用程序和硬件之间的一层软件
- 操作系统的两个基本功能:防止硬件被失控的应用程序滥用;向应用程序提供简单的、一致的、有效的接口来控制硬件设备
- Amdahl定律:P16,了解即可
- 三个层次的并发:线程级别,指令级别(超标量处理器:在一个时钟单位内执行多个指令),单指令、多数据并行
- 三个层次的抽象:文件,虚拟内存,进程
练习:看一下P16练习1.1,不重要,了解即可
信息的表示
- 为什么使用二进制:便于表示、存储、传输
- 将学习的三种数据类型:有符号整数,无符号整数,浮点数
- 进制转换:略(数电里面学过了)
- 32位程序与64位程序的不同:32位程序
long类型为4字节,指针类型为4字节;64位程序long类型为8字节,指针类型为8字节;寻址空间大小不同:32位程序最多寻址 2 32 2^{32} 232即4G内存,64位能寻址 2 64 2^{64} 264内存;64位机器向下兼容32位机器 - 大端法、小端法:大端法高位在内存低处,小端法低位在内存高处。直观表示为,小端法和平常的数字表示顺序是反过来的。
- 布尔环:
a ^ a = 0,见课本第38页练习2.10。 - 逻辑运算与位运算的不同:逻辑计算只要得出了结果,就不会继续计算。例如
a && b,只要a为假,则b不会执行。 - 移位运算:特殊的只有右移。逻辑位移补符号位,算术位移补0。
- 移位运算切记:移位的大小
K绝对不能大于等于数据类型的字节数M,因为实际的移位大小为K mod M,例如int << 32,结果是32 mod 32 = 0,即不产生操作,应当更正为(int << 31) << 1 - 整数表示只需要记住:有符号整数与无符号整数仅仅只有解读方式不同,它们的位级表示是一样的,运算过程基本上也是一致的(乘法在底层使用的机器指令不一样,但是最终的位级表示是一样的)。
- 有符号整数的表示范围是不对称的:
-2^(k-1) ~ 2^(k-1)-1,例如int类型,范围为-2^31~2^31-1。 - 有符号整数的负数形式采用补码表示。原因:其他的负数表达方式都有存在+0与-0的问题。
- 有符号整数的最小的负数表达形式的补码表示是自身。例如
-INT_MIN=INT_MIN。至于为什么,写一下它的补码形式就知道了。所以它特别特殊。 - 无符号数与有符号数的快速转化:
k位的整数,无符号数=有符号数+2^k,例如,[1001]有符号数表示为-2^3+2^0=-7,无符号数表示为2^3+2^0=9,相差2^4=16 - 截断与扩展:截断就和取模差不多,扩展要注意是不是有符号数,因为有符号数的扩展要算上符号位。
- 乘法:P71
- 除法公式背:P74
- 加法溢出检测:如果加数均为正数,得出负数或者0,则说明溢出。不可使用
c = a + b; c - b == a的方法进行判断:课本第65页练习题2.31 - 乘除法溢出检测:课本第68页2.35
- 浮点数的表示:P79
- 当将浮点数当成整数进行表示时,大小顺序不变:课本P81
- 浮点数所能准确表示的最大正整数:课本P83练习题
- 必须理解:P82最后一段话
- 向偶数舍入:若是中间值,向偶数舍入,否则向更近的那一边舍入。课本P84练习。
- 浮点运算:加法:可交换、单调性、不可结合(由于舍入,将丢失信息);乘法:可交换,单调性(整数乘法不具有单调性(溢出,正数相乘可能得到负数)),不可结合,不具有加法分配性( 1 e 20 ∗ 1 e 20 − l e 20 ∗ 1 e 20 = N a N 1e20*1e20-le20*1e20=NaN 1e20∗1e20−le20∗1e20=NaN(溢出) 1 e 20 ∗ ( 1 e 20 − 1 e 20 ) = 0.0 1e20*(1e20-1e20)=0.0 1e20∗(1e20−1e20)=0.0)
机器级表示
A&T汇编
-
寄存器
寄存器分为三类(至少):被调用者保存寄存器,调用者保存寄存器,栈指针
被调用者保存寄存器,即被调用的函数有义务使得这些寄存器的值在过程结束的时候保持和过程开始时候的值一样,即有义务保存这些寄存器的值。调用者保存寄存器,即调用者有义务自己保存这些寄存器的值。栈指针,即rsp指针,指向栈顶。具体看课本P120图 -
寻址方式
看课本P121表格并完成其后的练习 -
MOV族
有MOV、MOVZ、MOVS三种类
MOVZ:小->大。多出来的空间用0补足
MOVS:小->大。多出来的空间用符号位补足
注意:
- MOV的源和目的不能都是内存地址,至少有一个寄存器。
movabsq是一个很特殊的指令,特殊在于会将寄存器的高位用0补足- MOVS有
movslq,而MOVZ没有movzlq,因为movabsq已经完成了该功能 - 特殊的指令:
cltq,将eax扩展为rax,MOVS的指令
-
POP、PUSH
POP和PUSH可以由其他指令复合完成。使用POP和PUSH指令的唯一目的是减少机器指令字节数。
看P127页表
注意,栈顶在低位地址。看课本P13图,注意观察箭头方向
因此,分配空间要将rsp指针减去相应的大小。 -
算术操作、逻辑操作
看课本P129表
注意,左移的两个表达式效果是一样的。
注意下面一段话,leaq的灵活使用。 -
跳转
比较特殊的是jmp,有两种跳转方式,直接跳转和间接跳转。(在实践的时候发现,我好像只能对寄存器进行间接跳转。)看课本P139表
结构
过程
数据
链接
- 链接是将各种代码和数据片段收集并组合成为一个单一文件的过程
- 链接可以执行于编译时,也可以执行于加载时,甚至运行于运行时。详见课本介绍
- 一个程序的编译包括:预处理,编译,汇编,链接。使用
cpp进行预处理,使用cc1进行编译,使用as进行汇编,使用ld进行链接
- cc1,第三个字符是阿拉伯字母1,而不是英文字母l
- shell会调用操作系统中一个叫做加载器的函数,将可执行文件的代码和数据复制到内存,然后将内核的控制权转交给该程序。
- 使用
gcc -E进行预处理,使用gcc -S进行编译,使用gcc -c进行汇编,使用gcc -o进行可执行文件的生成 - 为了构造可执行文件,链接器必须完成两个主要任务:符号解析:将每个符号引用和符号定义关联起来;重定位:将每一个符号定义与内存位置关联起来,从而重定位section
- 链接器对整个程序一无所知,大部分工作都由产生目标文件的编译器与汇编器完成
- 目标文件分为:可重定位目标文件(.o),可执行目标文件,共享目标文件(.so)(关于.so文件,在gcc手册中有详细介绍)
- 目标文件的格式为ELF。参考资料1 参考资料2
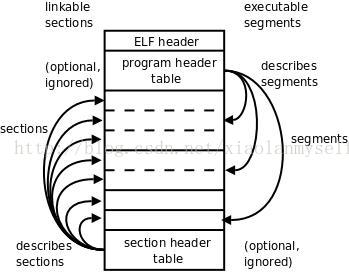
- ELF
- .text,正文,已经编译的机器代码
- .rodata,read only data
- .data,已经初始化的全局和静态变量(不包含局部变量)
- .bss,未初始化的全局和静态变量。该节不占据实际空间,仅仅是一个占位符。目标文件中未初始化的变量不需要占据空间,运行时在内存中将其赋值为0,也不占据可执行文件的空间。
- .symtable,符号表,存放函数、全局变量的信息。每个可重定位的目标文件都有一张符号表,除非使用STRIP命令去除。注意,其不包含局部变量
- .rel.text:一个.texg section中的位置列表。链接器会修改这些位置。任何外部函数或全局变量的位置都需要修改,任何本地函数的指令不需要修改。可执行目标文件中不需要重定位信息
- .rel.data:所有的全局变量与外部定义函数的重定位信息。
- .debug:调试符号表,只有使用
-g参数才会出现。条目中包含局部变量、全局变量、原始C文件。 - .line:原始C文件与机器指令的行号的映射
- .strtab,字符串表
以上重要的有:1,2,3,4,5
可以使用readelf指令读取ELF文件
- 符号
链接器的上下文中有三种符号:
- 全局符号:能被其他模块引用的符号。对应于非静态的C函数与全局变量。在EFL文件中放在.data、.bss中
- 外部符号:由其他模块定义的全局符号
- 局部符号:不能被其他模块引用的局部符号,包括static属性的C函数与全局变量。在该模块的任何位置可见!与局部变量区分!
链接器的符号和变量不是一个概念。.symtab中不包含任何局部变量(非静态)。这些局部变量(非静态)在栈中被管理。
定义为static的局部变量不是在栈中管理的,编译器在.data中为其分配空间,并创建一个有唯一名字的符号。
例如在两个函数中都定义了static变量x,那么编译器会创建两个符号:x.1、x.2
-
符号表
有三个伪section,没有对应的条目:
ABS:不应该被重定位的符号
UNDEF:未定义符号
COMMON:未分配位置的未初始化的数据(未初始化的全局变量)(.bss:未初始化的静态变量以及初始化为0的全局或静态变量)
(未进行初始化的全局变量在COMMON中,未初始化的静态变量在.bss中)
(完成课本P470练习) -
符号解析
链接器解析符号引用的方法是将每个引用与它输入的可重定位目标文件的符号表中的一个确定的符号定义关联起来。
编译器值允许每个模块中每个局部符号有一个定义,还要确保静态局部变量有唯一的名字。
当编译器遇到一个不在当前模块中定义的符号时,会假设该符号时在其他某个模块中定义的,然后生成一个链接器符号表条目,将其交与链接器处理。
多个目标文件可能会定义相同名字的全局符号。链接器要么标志为错误,要么以某种方式选出一个定义并抛弃其他定义。(C++中的重载) -
解析全局符号
只有全局符号才有强弱的概念
函数和已初始化的全局变量是强符号,未初始化的全局变量是弱符号
使用以下规则处理多重定义的符号:
- 不允许同名的强符号
- 强符号和弱符号同名,选择强符号
- 多个弱符号,随机选择
规则2和规则3的连续应用会造成一些运行时错误
使用gcc -fno-common调用链接器,告诉链接器,在遇到多个全局符号的时候,触发一个错误
- 与静态库链接
标准C函数放在了一个单独的、可重定位的目标模块中,优点是可以将编译器的实现与标准函数的实现分离,缺点是每个可执行文件都包含着一个标准函数集合的完全副本(极大浪费了磁盘空间),并且每个程序都将自己的函数的副本放在内存中(极大地浪费了内存空间)。
静态库的概念用于解决上述缺点
相关函数被编译为单独的模块,然后封装为单独的静态库文件。链接时,链接器只复制被程序引用的目标模块。
使用AR工具创建一个静态库:
ar rcs lib.a a.o b.o
- 静态库解析引用的流程
在符号解析阶段,链接器从左到右扫描命令行上的可重定位目标文件与archive文件
它维护着一个可重定位目标文件的集合E,一个未解析符号集合U,以及已定义符号集合D
解析流程:
解析文件f
->目标文件
-> add f to E, edit U and D
-> next file
->archive file
-> 如果成员文件m定义了U中的一个引用
-> add m to E, edit U and D
-> next file
上述流程的缺点:能否成功解析与出现在命令行上的顺序密切相关。
原则:将库文件放在后面。
(在An introducuction to GCC一书中有详细描述)