LTP 是哈工大社会计算与信息检索研究中心历时十年开发的一整套中文语言处理系统。LTP 制定了基于 XML 的语言处理结果表示,并在此基础上提供了一整套自底向上的丰富而且高效的中文语言处理模块 (包括词法、句法、语义等6项中文处理核心技术),以及基于动态链接库(Dynamic Link Library, DLL)的应用程序接口,可视化工具,并且能够以网络服务(Web Service)的形式进行使用。
LTP 系统框架图如下所示:

LTP提供了一系列中文自然语言处理工具,用户可以使用这些工具对于中文文本进行分词、词性标注、句法分析等等工作。从应用角度来看,LTP为用户提供了下列组件:
- 针对单一自然语言处理任务,生成统计机器学习模型的工具
- 针对单一自然语言处理任务,调用模型进行分析的编程接口
- 系统可调用的,用于中文语言处理的模型文件
- 针对单一自然语言处理任务,基于云端的编程接口
1 pyltp安装
pyltp 是 LTP 的 Python 封装,提供了分词,词性标注,命名实体识别,依存句法分析,语义角色标注的功能。
pip install pyltp
接下来,需要下载 LTP 模型文件。下载地址为:下载地址
选择模型版本为ltp_data_v3.4.0.zip
请确保下载的模型版本与当前版本的 pyltp 对应,否则会导致程序无法正确加载模型。
将压缩包解压,里面提供了多个模型文件,主要包括:
cws.model 分句模型
pos.model 词性标注模型
ner.model 命名实体识别模型
parser.model 依存句法分析模型
pisrl.model 语义角色标注模型
2 pyltp 使用
分句
from pyltp import SentenceSplitter #分句,对句子进行切分
sentence = SentenceSplitter.split("他叫汤姆拿外衣。汤姆生病了。他去了医院。")
print("\n".join(sentence))
segmentor.release() # 释放模型
他叫汤姆拿外衣。
汤姆生病了。
他去了医院。
分词
from pyltp import Segmentor#导入Segmentor库
math_path = "/home/lxn/goal/ltp/ltp_data_v3.4.0/cws.model"#LTP分词模型库
segmentor = Segmentor()#实例化分词模块
segmentor.load(math_path)#加载分词库
words = segmentor.segment("他叫汤姆拿外衣。")
print(' '.join(words).split())#分割分词后的结果
segmentor.release() # 释放模型
['他', '叫', '汤姆', '拿', '外衣', '。']
type(words)
pyltp.VectorOfString
这里words = segmentor.segment(“他叫汤姆去拿外衣。”) 的返回值类型是native的VectorOfString类型,可以使用list转换成Python的列表类型
外接词典
pyltp 分词支持用户使用自定义词典。分词外部词典本身是一个文本文件(lexicon text),每行指定一个词,编码同样须为 UTF-8,样例如下所示
词典内容lexicon.txt:
光明66kv变电站
1号主变压器
主变压器
分接开关
有载开关
呼吸器
硅胶变色
from pyltp import Segmentor#导入Segmentor库
math_path = "/home/lxn/goal/ltp/ltp_data_v3.4.0/cws.model"#LTP分词模型库
segmentor = Segmentor()#实例化分词模块
segmentor.load_with_lexicon(math_path, '/home/lxn/goal/ltp/lexicon/lexicon.txt') # 加载模型,第二个参数是您的外部词典文件路径
words = segmentor.segment("光明66kv变电站1号主变压器分接开关呼吸器硅胶变色")
print(' '.join(words).split())#分割分词后的结果
segmentor.release() # 释放模型
['光明', '66kv', '变电站', '1号', '主变压器', '分接开关', '呼吸器', '硅胶变色']
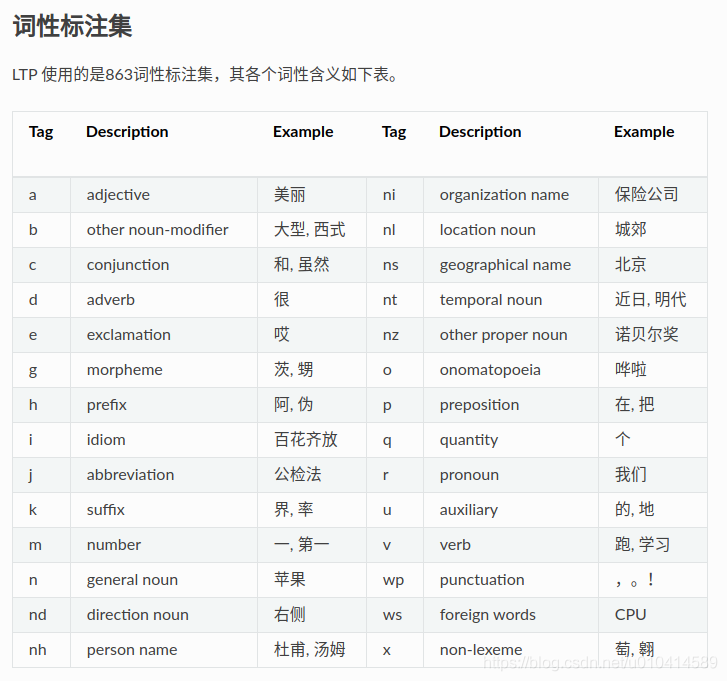
词性标注
from pyltp import Postagger#导入Postagger库
math_path = "/home/lxn/goal/ltp/ltp_data_v3.4.0/pos.model"#LTP词性标注模型库
postagger = Postagger() #实例化词性模块
postagger.load(math_path)#加载词性库
words = ['他', '叫', '汤姆', '拿', '外衣', '。'] # 分词结果
postags = postagger.postag(words)# 词性标注
print(words)
print(' '.join(postags).split())#分割标注后的结果
postagger.release() # 释放模型
['他', '叫', '汤姆', '拿', '外衣', '。']
['r', 'v', 'nh', 'v', 'n', 'wp']

命名实体识别
from pyltp import NamedEntityRecognizer#导入库NamedEntityRecognizer
math_path = "/home/lxn/goal/ltp/ltp_data_v3.4.0/ner.model"#LTP命名实体识别模型库
recognizer = NamedEntityRecognizer() # 初始化实例
recognizer.load(math_path)#加载实体识别库
words = ['他', '叫', '汤姆', '拿', '外衣', '。'] #分词结果
postags = ['r', 'v', 'nh', 'v', 'n', 'wp'] #词性标注结果
netags = recognizer.recognize(words, postags) # 命名实体识别
print(' '.join(netags).split())#分割识别后的结果
recognizer.release() # 释放模型
['O', 'O', 'S-Nh', 'O', 'O', 'O']
LTP 采用 BIESO 标注体系。B 表示实体开始词,I表示实体中间词,E表示实体结束词,S表示单独成实体,O表示不构成命名实体。
LTP 提供的命名实体类型为:人名(Nh)、地名(Ns)、机构名(Ni)。
B、I、E、S位置标签和实体类型标签之间用一个横线 - 相连;O标签后没有类型标签。

依存句法分析
from pyltp import Parser#导入库Parser
math_path = "/home/lxn/goal/ltp/ltp_data_v3.4.0/parser.model"#LTP依存分析模型库
parser = Parser() # 初始化实例
parser.load(math_path)#加载依存分析库
words = ['他', '叫', '汤姆', '拿', '外衣', '。'] #分词结果
postags = ['r', 'v', 'nh', 'v', 'n', 'wp'] #词性标注结果
arcs = parser.parse(words, postags) # 句法分析,这里的words是分词的结果,postags是词性标注的结果
print ("\t".join("%d:%s" % (arc.head, arc.relation) for arc in arcs) ) # 依存分析
parser.release() # 释放模型
2:SBV 0:HED 2:DBL 2:VOB 4:VOB 2:WP
arc.head 表示依存弧的父节点词的索引。ROOT节点的索引是0,第一个词开始的索引依次为1、2、3…
arc.relation 表示依存弧的关系。
arc.head 表示依存弧的父节点词的索引,arc.relation 表示依存弧的关系。`
https://ltp.readthedocs.io/zh_CN/latest/appendix.html#id3https://ltp.readthedocs.io/zh_CN/latest/appendix.html#id3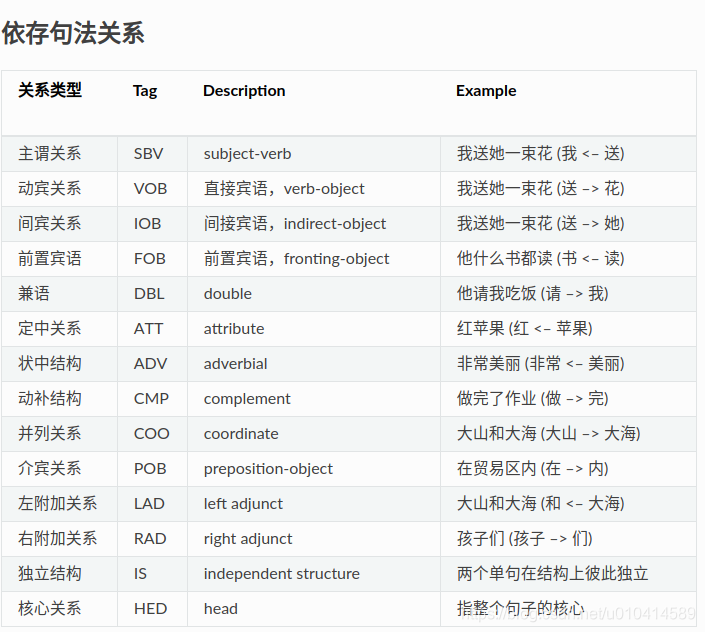
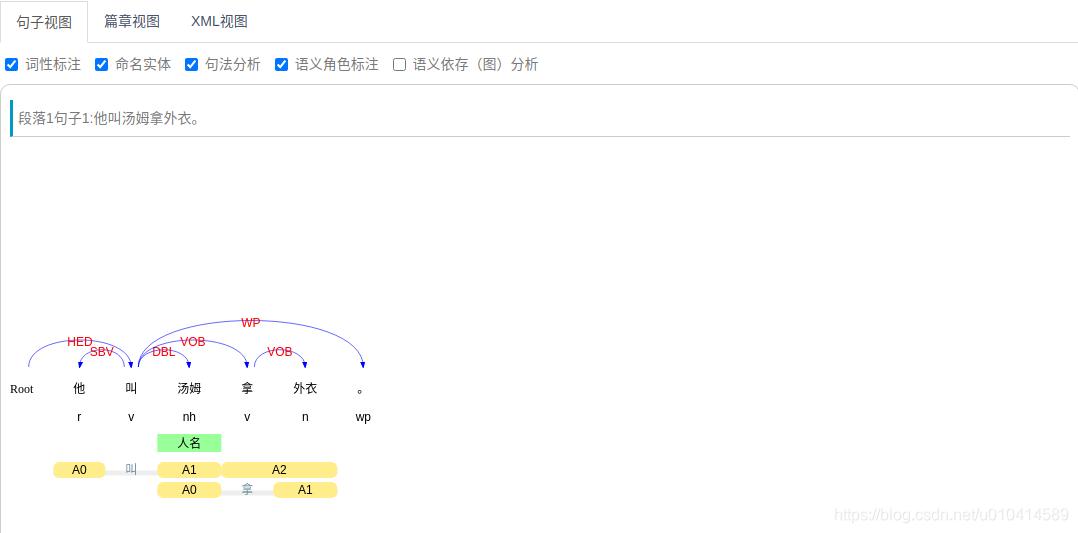
语义角色标注
import pyltp
from pyltp import SementicRoleLabeller#导入库SementicRoleLabeller
math_path = "/home/lxn/goal/ltp/ltp_data_v3.4.0/pisrl.model"#LTP语义角色标注模型库
labeller = SementicRoleLabeller() # 初始化实例
labeller.load(math_path)#加载语义标注库
words = ['他', '叫', '汤姆', '拿', '外衣', '。'] #分词结果
postags = ['r', 'v', 'nh', 'v', 'n', 'wp'] #词性标注结果
roles = labeller.label(words, postags, arcs) # 语义角色标注,这里的words是分词结果,postags是词性标注结果,arcs是依存句法分析结果
# 打印结果
for role in roles:
print (role.index, "".join(
["%s:(%d,%d)" % (arg.name, arg.range.start, arg.range.end) for arg in role.arguments]))
labeller.release() # 释放模型
1 A0:(0,0)A1:(2,2)A2:(3,4)
3 A1:(4,4)
参考文献
https://pyltp.readthedocs.io/zh_CN/latest/api.html
https://ltp.readthedocs.io/zh_CN/latest/appendix.html#id3
在线演示环境:http://ltp.ai/demo.html