mysql优化
1、存储引擎
1、查看mysql支持的存储引擎方法:SHOW ENGINES;

2、myIsam存储引擎对比innodb
myIsam不支持事务,不支持外键,插入效率高,不适合高并发

2、sql优化步骤
1、查看sql执行影响的行:SHOW STATUS LIKE 'Com_______'; 下划线是占位符,7个就是insert之类的
2、查看innodb引擎sql执行影响的行:SHOW GLOBAL STATUS LIKE 'Innodb_rows_%';
3、查询低效率的sql
1 、慢查询日志查询掉效率的sql
用--log-show-queries[=file_name]启动的时候,就可以有一个日志文件来展示所有慢的sql
2、show processlist
用show processlist 命令可以查询实时的正在执行的线程,包括线程的状态和是否锁表等信息
4、explain分析sql
示例:
1、id
id相同表示从上到下执行:EXPLAIN SELECT * FROM shop_order o ,shop_order_goods og WHERE o.`ID` = og.`ORDER_ID`
id不同表示越大越优先执行:EXPLAIN SELECT * FROM shop_order o WHERE o.`ID` = (SELECT og.order_id FROM shop_order_goods og WHERE og.`ID` = 123242)
2、select_type
效率从上到下越来越慢↓
1、simple:简单的查询,没有子查询,单表查询
2、primary:含有子查询时,外层的表表示的就是primary
3、subquery:含有子查询时,内层的表表示subquery
4、deriaed:在form后包含的子查询 select * (子查询)
5、union(两个表数据放一起):在第二个select中出现union,则表示为union 。EXPLAIN SELECT o.id FROM shop_order o UNION SELECT og.id FROM shop_order_goods og
6、union_result:union表中获取到的result
3、type
效率从上到下越来越慢↓
1、null:不访问任何表。select now();
2、system:只会出现一行记录,查询的子表中只有一行记录 EXPLAIN SELECT * FROM (SELECT o.id FROM shop_order o WHERE o.`ID` = 866) a
3、const:表示通过一次索引就找到,效率也很快。通常是查询主键或者有唯一索引的列才会出现
4、eq_ref:类似ref,根据主键或者唯一索引关联查询出的数据只有一条,就会出现eq_ref
5、ref:非主键索引或者唯一索引,查询时就会出现ref
6、range:用> 、< 、in、like 等就会出现range
7、index:遍历了整个索引树,比all快,但是效率不高,例如查询整个表的id就是index
8、all:查询了整个表
开发时:最起码要达到range,最好能到ref
4、key
1、possible_key:显示可能使用到的索引
2、key:实际使用到的索引,如果建了索引却为null,就要看下为什么没走索引
3、key_len:索引使用到的长度,越短越好
5、rows
扫描到表的行数,不包含查询索引的行。如果加了索引,直接会查索引,在索引中查到之后直接就能找到表中的值,所以加了索引只会找1行
6、extra
其他详细信息,需要关注以下几个信息
1、using filesort:使用不是索引的列进行排序,性能差
2、using temporary:使用了临时表的中间结果,常用语order by 或者 group by,性能差
3、using index:使用了覆盖索引,效率不错
5、show prosfile分析sql
1、打开prosfile功能
是否支持该功能:select @@have_profiling; YES代表可用
默认profiling关闭状态,查看是否开启:select @@profiling;
开启profiling:SET profiling = 1;
2、使用profile
1、show profiles:可用查看之前的sql具体使用的时间

2、查看该query_id具体的使用时间
show profile for query query_id

Sending data:从查询数据到返回数据所有的时间
6、trace分析优化器执行计划
1、开启优化器开关:SET optimizer_trace="enabled=on",end_markers_in_json=ON;
2、设置优化器占用内存最大大小:SET optimizer_trace_max_mem_size=1000000;
3、执行sql后查询优化器执行的sql是怎样的
执行sql:SELECT * FROM shop_order o WHERE o.`ID` < 10
查询优化器如何执行sql的:SELECT * FROM information_schema.`OPTIMIZER_TRACE`;
7、避免索引失效
索引是优化查询效率最最要的方法,可以解决sql中大部分的效率问题
1、全值匹配
对查询列的所有值都指定具体的值
SELECT * FROM `base_backstage_log` WHERE add_time = 20180321184236915 AND SYS_USER_ID = 1 AND TYPE = 1
2、最左前缀法则
利用最左前缀法则,这样能充分使用索引。例如加了 name,phone,age三个联合索引,where条件后同时存在则都走索引,如果只存在name和age,只会走name的索引,where条件后顺序没有要求
举例1、select * from 表名 where phone = 1 and name = 1 and age = 1 ;
上面sql走三个索引,phone的索引长度是9,name 的索引长度是9,age 的索引长度是5,所以一共用了23个索引长度
![]()
举例2、select * from 表名 where name = 1 and age = 1;走一个索引
可以看出只有一个9的索引长度
![]()
3、范围查询之后,后面的列不走索引,当前查询走索引,当复合索引的第一个列是范围查询,都不走索引
举例1:select * from 表名 where name = '1' and phone > 1 and age = 1 ;
只有name和phone走了索引,age没有走索引
举例2:select * from 表名 where name > '1' and phone = 1 and age = 1 ;
都没走索引
4、索引列上做运算操作,索引失效
举例1:select * from 表名 where left(name,8) = '1' and phone = 1 and age = 1 ;
都不走索引
举例2:select * from 表名 where name= '1' and left( phone,8) = 1 and age = 1 ;
只有name走了索引
5、字符串不加单引号,索引失效
走索引:select * from 表名 where name = '1'
不走索引:select * from 表名 where name = 1
6、尽量避免回表查询
尽量使用索引中有的值成为查询结果,如果索引中没有,还需要再去表中查一遍所有,也就需要回表查询
所以,尽量不要使用*作为查询结果
实例1:select * from 表名 where name = '1'
![]()
出现了Using index condition字样,也就表示需要回表查询
实例2:select name from 表名 where name = '1'
![]()
7、or之后的条件如果没有索引,就全部不走索引
走索引:select * from 表名 where name = '1' or phone = 1
不走索引(storeId没有加索引):select * from 表名 where name = '1' or store_id = 1
8、like前加%就会不走索引,加后面走索引
不走索引:select * from 表名 where name like '%1'
查询结果如果是索引列,则走索引(注意,有其他不是索引列则不走索引):select name from 表名 where name like '%1'
解决方案:使用覆盖索引就可以,只查询索引里有的列
9、mysql发现查询表比查询索引快,则会选择查询表
10、in 走索引, not in不走索引
11、单列索引和复合索引的选择
select * from 表名 where phone = 1 and name = 1 and age = 1 ;
1、使用单列索引情况只会走一个索引
![]()
2、使用复合索引会走三个索引
![]()
8、sql优化
1、大数据导入
导入数据sql:load data local infile '文件地址' in table 表明 fileds terminated by ',' lines terminated by '\n'
注意点:
1、数据id有序导入速度更快
2、关闭唯一性校验(也就是校验数据是否重复关闭): SET UNIQUE_CHECKS=0; 0关闭 1开启
2、order by 优化
order by 后的数据要和索引的数据顺序相同,返回数据最好是索引数据,否则会出现filesort
3、group by 优化
group by 后发现也出现了ordersort,也就表示group by 也会进行排序操作
1、得知会排序,也就可以后面加上order by null,表示不排序,也就没有了ordersort
2、添加索引,会效率更高
4、子查询优化
少使用子查询,多使用关联查询
子查询是index:EXPLAIN SELECT o.`ID` FROM shop_order o WHERE o.`ID` = (SELECT og.order_id FROM shop_order_goods og LIMIT 1)

多表查询是ref:EXPLAIN SELECT o.`ID` FROM shop_order o,shop_order_goods og WHERE o.`ID` = og.order_ id

总结:ref比index快,也就表示多表关联查询比子查询快
5、or 优化
1、要保证左右两边的列都要有索引,其中一个没有索引,都不会走索引,即使走索引,也是range,效率不高
EXPLAIN SELECT * FROM shop_order o WHERE o.`ID` = 21423 OR o.`ID` = 1 21
![]()
2、用union替换or,会变为const,效率远高于range
EXPLAIN SELECT * FROM shop_order o WHERE o.`ID` = 21423 UNION SELECT * FROM shop_order o WHERE o.`ID` = 121

6、limit 优化
当页数很大的情况下,查询的时间就会很差,效率很差。原因是因为会前面数据都会查询一遍,但是只要最后分页完的数据,其他记录丢弃,造成浪费
limit查询会造成全表扫描:EXPLAIN SELECT * FROM `base_backstage_log` l LIMIT 1727746,10
![]()
解决:
1、先把id分页,然后再根据id查询到所需要的数据,可以用到id的索引,效率更高
EXPLAIN SELECT * FROM `base_backstage_log` l, (SELECT id FROM `base_backstage_log` l LIMIT 1727746,10) l2 WHERE l.`ID` = l2.ID

2、先根据id查询出分页以后的范围,然后再limit,走id的索引,效率更高。(主键不能出现断层,必须是自增主键,不建议使用)
EXPLAIN SELECT * FROM `base_backstage_log` l WHERE l.`ID` >1727746 LIMIT 10
7、主动告诉sql用哪个索引
1、建议使用该索引(如果数据库觉得搜索表更快,还是会直接查询表);EXPLAIN SELECT * FROM shop_order o USE INDEX(index_sn) WHERE o.`SN` = '18042400074488913'
2、不用该索引:EXPLAIN SELECT * FROM shop_order o IGNORE INDEX(index_sn) WHERE o.`SN` = '18042400074488913'
3、强制使用该索引(如果数据库觉得搜索表更快,会改为搜索索引):EXPLAIN SELECT * FROM shop_order o FORCE INDEX(index_sn) WHERE o.`SN` = '18042400074488913'
9、应用层优化mysql
1、使用数据库连接池
2、减少对数据库的访问
3、增加缓存层减少对数据库的访问,例如redis
4、负载均衡
将压力用算法分布到各个服务器上,降低单个数据库的压力
将mysql主从复制,主节点的数据和从节点的数据完全一致,增删改用的是主节点,主节点同步到从节点,查询操作用算法在各个从节点查询

10、查询缓存优化
当查询两条sql完全一致的时候,优先查询缓存中数据,当数据被修改,缓存失效,再次查询数据返回并存入缓存
1、查询数据库是否支持缓存:SHOW VARIABLES LIKE 'have_query_cache'
2、是否开启了缓存:SHOW VARIABLES LIKE 'query_cache_type'; off 未开启 on 开启 demand 只有sql中添加了sql_cache的语句才会被缓存
3、缓存大小:SHOW VARIABLES LIKE 'query_cache_size';
4、设置缓存大小为32m:SET GLOBAL query_cache_size = 1024 * 1024 * 32;
4、查询缓存的具体情况:SHOW STATUS LIKE 'Qcache%';
Qcache_free_memory:可用内存
Qcache_hits:查询缓存次数
Qcache_inserts:添加到缓存次数
Qcache_lowmem_prunes:内存不足时,被移除出缓存的次数
Qcache_not_cached:没有使用缓存的次数
5、打开缓存功能:
window:服务 中找到 mysql ,右键属性--defaults-file 后面就是my.ini位置,添加 query_cache_type=1 mysql
linux:/use/my.cnf 中添加 query_cache_type=1 重启mysql
6、使用缓存和不使用缓存语句
使用缓存 :SELECT SQL_CACHE COUNT(*) FROM `shop_stock_manage_day_copy`
不使用缓存:SELECT SQL_NO_CACHE COUNT(*) FROM `shop_stock_manage_day_copy`
7、失效原因
1、当有时间等不确定的语句缓存会失效
2、不查表不走缓存
3、sql语句必须一致才会走缓存
4、表数据更改时 缓存失效
11、内存优化
在my.ini中配置
1、索引内存大小设置:key_buffer_size=512M
2、innodb缓存池大小设置:innodb_buffer_pool_size=512M
12、锁
1、锁类型
innodb默认支持行锁
操作粒度区分:
表锁:锁整个表,锁粒度大
行锁:锁这一行,加锁慢,会出现死锁
操作类型区分:
读锁:线程可同时进行
写锁:阻断其他线程
2、行锁介绍
效率低,会出现死锁,并发度高
修改会自动加写锁,查询不会加锁
1、手动增加读锁:SELECT COUNT(*) FROM `表名` LOCK IN SHARE MODE
2、手动添加写锁:SELECT COUNT(*) FROM `表名` FOR UPDATE
3、事务特性(ACID)
原子性:要么成功,要么失败
一致性:事务开始到结束,数据保持一致
隔离性:保证事务不受外界影响
持久性:事务修改后,对数据的修改是永久的
4、并发带来的问题
脏写:两个事务选择同一行,前一个事务修改的值会被下一个事务修改的值覆盖
脏读:一个事务访问到了另一个事务还没提交的数据
不可重复读:一个事务中查询了两次同一个数据,第二次查询出来的数据和之前的数据不一致,被其他事务修改了
幻读:两次查询出来的数据数量不一致,被其他事务增加或删除数据了
5、事务隔离级别
隔离级别越大,效率越低,分为以下四种隔离级别,默认隔离级别为不可重复读
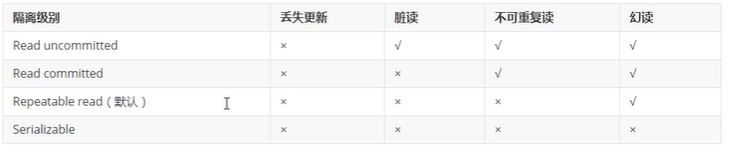
1、查看隔离级别:SHOW VARIABLES LIKE 'tx_isolation'
13、日志
1、错误日志
默认开启
查询错误日志位置:SHOW VARIABLES LIKE 'log_error%'
当数据库发生严重错误的时候会记录在错误日志中,数据库不可用是可以优先看这个日志
2、二进制日志
对数据库的备份起到至关重要的作用,mysql主从复制就是依靠这个日志实现的
show variables like '%log_bin%'; 查看是否开启
1、储存格式:
1、STATEMENT:对数据修改的sql都会存放在日志中
2、ROW:每一行的数据变更都会存放在日志中
2、默认关闭,开启方法,在my.ini中的[mysql]下增加:
1、开启二进制日志: log_bin=mysqlbin
2、sql语句格式储存:binlog_format=STATEMENT
3、日志目录:mysql根目录下的data下
日志索引信息:mysqlbin.index
日志的具体内容,二进制文件:mysqlbin.000001
4、查看方式:mysqlbinlog 二进制文件名
4、查询日志
增删改查sql都会存在查询日志
1、开启查询日志:general_log=1
2、日志位置:general_log_file=query.log
5、慢查询日志
慢的sql会记录在日志中
1、开启慢查询日志:slow_query_log=1
2、慢日志名称:slow_query_log_file=slow_query.log
3、查询时间,大于该时间(秒)的sql记录:long_query_time=1
14、mysql复制
1、复制概念
将主数据库的二进制文件复制到从库中,然后将这些语句重新执行,从而将数据达成同步的效果
mysql支持一个主库向多个从库复制
2、主数据库搭建
1、首先关闭所有服务的防火墙
2、主数据库my.ini添加以下内容:
集群数据库id(要保证id唯一):server-id=1
数据库生成二进制日志:log-bin=/var/lib/mysql/mysqlbin
是否只读(0:读写 1:只读):read-only=0
忽略的数据库:binlog-ignore-db=mysql
3、 重启数据库
4、 指定一个数据库可以同步主数据库的数据
grant replication slave on *点表示所有的数据库所有的表* to '创建的账号'@'从数据库的ip' identified by '账号的密码'
举例:grant replication slave on *.* to 'itcast'@'192.168.0.1' identified by 'itcast'
5、刷新权限列表:flush privileges;
7、查看主节点的状态信息:show master status; 主要查看内部的文件名和文件起始位置
3、从数据库搭建
1、首先关闭所有服务的防火墙
2、从数据库my.ini添加以下内容:
集群数据库id(要保证id唯一):server-id=2
数据库生成二进制日志:log-bin=/var/lib/mysql/mysqlbin
3、 重启数据库
4、链接主数据库:
change master to master_host='主数据库ip' ,master_user='创建的账号',master_password='创建的密码',master_log_file='要复制文件名',master_pos_pos='文件起始位置'
举例: CHANGE MASTER TO MASTER_HOST='192.168.149.131' ,MASTER_USER='slave1',MASTER_PASSWORD='slave1',MASTER_LOG_FILE='mysqlbin2.000001',MASTER_LOG_POS=106
5、开启同步操作:start slave
6、查看同步情况:show slave status
Slave_IO_Running , Slave_SQL_Running 需要都为yes
7、停止同步:STOP SLAVE;
4、执行sql
此时主服务器执行增删改操作,从服务器就可以同步sql了
15、读写分离(aop)
1、配置读写两个数据库

2、配置读写数据源

3、