目录
一、Kafka 系统架构
此处创建的Kafka集群有2个结点(Broker1,Broker2)
下图的Kafka集群可以通过命令创建(此处我用的是confluent公司下的confluent包大家也可以下载confluent里面包含zookeeper、kafka、kafka connect等kafka生态系统所有组件):
<confluent-path> bin/kafka-topics --create --bootstrap-server node01:9092 --topic A --partitions 2 --replication-factor 2 

(1)Topic A : 表明名为A 的主题。 不同主题可以暂存放不同分类的消息
(2)Partition : 分区。提高了Topic的并发能力 注:同一个分区中的消息不能被同一个消费者中的不同消费者消费消息。(例如,图中消费者组中有A、B和C三个消费者,则A、B和C不能同时消费主题A或B中的消息)
(3)Replication: 副本。 用来被备份每一个broker中leader的消息。 若只有一个broker,则replication-factor(副本数)最多为1。
(4)Leader/Follower : 表示一个Broker中存在唯一一个Leader和若干个Follwer。但生产者或消费者只连接Leader来生产或消费消息,Follower用来备份Leader中的数据
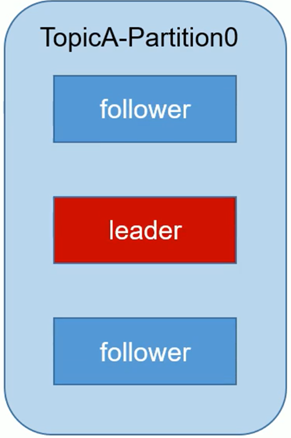
注:大家要搞清partition、replication、leader/follower的关系。 假如副本数(replication-factor)为3,则一个partition(分区)中存在1个leader和2个follower。不管分区数多大,一个分区中只能存在一个leader;副本数最少为1,此时分区中只有一个leader无follower。
下图所示,在分区partition-0中replication-factor=3的情况。此处针对整个Topic的partition而言。上面那个图是针对存在多个broker而言,但我们可以看出上面图中Topic A的replication-factor=2,有一个Leader和一个Follower。
二、Kafka的分区策略
1.Kafka生产者分区原因
a. 方便在集群中扩展,每个Partition可以通过调整以适应它所在的机器,而一个topic又可以有多个Partition组成,因此整个集群就可以适应任意大小的数据
b.可以提高并发,因为可以以Partition为单位读写
2.Kafka生产者分区的原则
我们需要将producer发送的数据封装成一个ProducerRecord对象。 下面代码为ProducerRecord类的构造器
public ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value)
{
this(topic, partition, timestamp, key, value, (Iterable)null);
}
public ProducerRecord(String topic, Integer partition, K key, V value, Iterable<Header> headers) {
this(topic, partition, (Long)null, key, value, headers);
}
public ProducerRecord(String topic, Integer partition, K key, V value) {
this(topic, partition, (Long)null, key, value, (Iterable)null);
}
public ProducerRecord(String topic, K key, V value) {
this(topic, (Integer)null, (Long)null, key, value, (Iterable)null);
}
public ProducerRecord(String topic, V value) {
this(topic, (Integer)null, (Long)null, (Object)null, value, (Iterable)null);
}(1)前三个构造器存在partition的参数,所以直接将输入的值作为partition的值;
(2)第四个构造器没有指明partition值但有key的情况下,将有key的hash值与topic的partition数进行取余得到partition值;
(3)最后一个构造器既没有partition值又没有key值的情况下,第一次调用的时候随机生成一个整数(后面每次调用在这个整数上自增),将这个值与topic可用的partition总数取余得到partition值。
3.Kafka消费者分区策略
一个consumer group中有多个consumer,一个topic有多个partition,所以必然会涉及到partition的分配问题,即确定哪个partition由哪个consumer来消费。 Kafka有两种分配策略,一个是RoundRobin(轮询),一个是Range。
消费者消费Topic中partition前如下图:

(1)采用RoundRobin分区策略
partition-0 ->partition-5 来源于一个topic ,但consumer group可以同时订阅多个主题的数据。

(2)采用Range分区策略(Kakfa默认策略)
一个分区范围(6/3)分配给一个消费者。 这种分区策略可能会造成消费者消费的分区数不对等的情况,若存在多有Topic,并且每个Topic分区数并不能刚好将分区数平分给分区数(例如7/3,则第一个消费者每次会多消费一个数据的消息),从而造成问题。

三、Kafka生产者数据可靠性保证
为保证producer发送的数据,能可靠的发送到指定的topic,topic的每个partition收到producer发送的数据后,都需要向producer发送Ack,如果producer收到ack,就会进行下一轮发送,否则重新发送数据。
1.针对producer与整个Topic中的parition情况
下图的流程:Producer向TopicA发送消息,若TopicA的parition0确认收到后返回给producer一个ack,然后producer会继续发送消息 ;若TopicA的parition0没有确认收到,则producer会重新发送消息。

2.针对producer与Topic中parition里的Leader和Follower情况
producer发送消息只发送给Leader,而Follower要备份Leader中的数据,,那么就存在何时发送ack问题。

(1)副本数据同步策略

Kafka选择了第二种方案,原因如下:
①同样为了容忍n台节点的故障,第一种方案需要2n+1个副本,而第二种方案只需要n+1个副本,而Kafka的每个分区都有大量的数据,第一种方案会造成大量数据冗余。
②虽然第二种方案的网络延迟会比较高,但网络延迟对Kafka的影响较小。
(2)ISR(in-sync replica set)
输入命令查看ISR:
( 前提是你已经创建了Topic first,若没有创建可以通过命令创建:
<confluent-path>bin/kafka-topics --create --bootstrap-server node01:9092 --topic first --partitions 2 --replication-factor 2)
<confluent-path>bin/kafka-topics --describe --topic first --zookeeper node01:2181
下图为上面Topic first的Kafka系统架构:

在采用副本数据同步策略中第二种方案后,若有如下场景:leader收到数据,所有follower都开始同步数据,但有一个follower因为某种故障吃吃不能与leader同步,那么leader就要一直等下去,直到它完成同步,才能发送ack。
这个问题的解决就需要用到ISR,Leader维护了一个动态的in-sync replica set(ISR),意为和leader保持同步的follower集合。当ISR中的follower完成数据的同步之后,leader就会给follower发送ack。如果follower长时间未向leader同步数据,则该follower将被踢出ISR,该时间值由replica.lag.time.max.ms参数设定。Leader发生故障之后,就会从ISR中选举新的leader。