一 消息中间件介绍
消息中间件是基于队列与消息传递技术,在网络环境中为应用系统提供同步或异步、可靠的消息传输的支撑性软件系统。
消息中间件利用高效可靠的消息传递机制进行平台无关的数据交流,并基于数据通信来进行分布式系统的集成。通过提供消息传递和消息排队模型,它可以在分布式环境下扩展进程间的通信。
概念图:
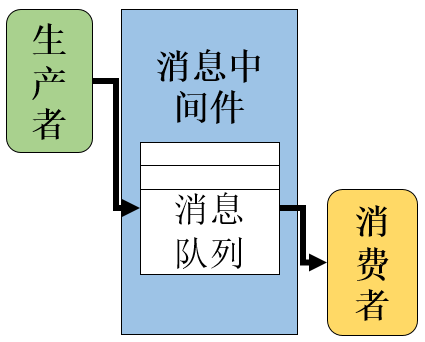
二 消息中间件的使用场景
王阿姨是小军的妈妈。
王阿姨希望小军多读书,常寻找好书给小军看,之前的方式是这样:王阿姨问小军什么时候有空,把书给小军送去,并亲眼监督小军读完书才走。久而久之,两人都觉得麻烦。
后来的方式改成了:王阿姨对小军说「我放到书架上的书你都要看」,然后王阿姨每次发现不错的书都放到书架上,小军则看到书架上有书就拿下来看。
书架就是一个消息队列,王阿姨是生产者,小军是消费者。
这带来的好处有:
1.王阿姨想给小军书的时候,不必问小军什么时候有空,亲手把书交给他了,王阿姨只把书放到书架上就行了。这样王阿姨小军的时间都更自由。
2.王阿姨相信小军的读书自觉和读书能力,不必亲眼观察小军的读书过程,王阿姨只要做一个放书的动作,很节省时间。
3.当明天有另一个爱读书的小伙伴小强加入,王阿姨仍旧只需要把书放到书架上,小军和小强从书架上取书即可(唔,姑且设定成多个人取一本书可以每人取走一本吧,可能是拷贝电子书或复印,暂不考虑版权问题)。

4.书架上的书放在那里,小军阅读速度快就早点看完,阅读速度慢就晚点看完,没关系,比起王阿姨把书递给小军并监督小军读完的方式,小军的压力会小一些。
这就是消息队列的四大好处:
1.解耦
每个成员不必受其他成员影响,可以更独立自主,只通过一个简单的容器来联系。
王阿姨甚至可以不知道从书架上取书的是谁,小军也可以不知道往书架上放书的人是谁,在他们眼里,都只有书架,没有对方。
毫无疑问,与一个简单的容器打交道,比与复杂的人打交道容易一万倍,王阿姨小军可以自由自在地追求各自的人生。
2.提速
王阿姨选择相信「把书放到书架上,别的我不问」,为自己节省了大量时间。
王阿姨很忙,只能抽出五分钟时间,但这时间足够把书放到书架上了。
3.广播
王阿姨只需要劳动一次,就可以让多个孩子有书可读,这大大地节省了她的时间,也让新的孩子的加入成本很低。
4.削峰
假设小军读书很慢,如果采用王阿姨每给一本书都监督小军读完的方式,小军有压力,王阿姨也不耐烦。
反正王阿姨给书的频率也不稳定,如果今明两天连给了五本,之后隔三个月才又给一本,那小军只要在三个月内从书架上陆续取走五本书读完就行了,压力就不那么大了。
当然,使用消息队列也有其成本:
1.引入复杂度
毫无疑问,「书架」这东西是多出来的,需要地方放它,还需要防盗。
2.暂时的不一致性
假如小军爸爸问王阿姨「小军最近读了什么书」,在以前的方式里,王阿姨因为亲眼监督小军读完书了,可以底气十足地告诉小军爸爸,但新的方式里,王阿姨回答小军爸爸之后会心想「小军应该会很快看完吧……」
这中间存在着一段「小军爸爸认为小军看了某书,而小军其实还没看」的时期,当然,小军最终的阅读状态与小军爸爸的认知会是一致的,这就是所谓的「最终一致性」。
那么,该使用消息队列的情况需要满足什么条件呢?
1.生产者不需要从消费者处获得反馈
引入消息队列之前的直接调用,其接口的返回值应该为空,这才让明明下层的动作还没做,上层却当成动作做完了继续往后走——即所谓异步——成为了可能。
王阿姨放完书之后小军到底看了没有,王阿姨根本不问,她默认他是看了,否则就只能用原来的方法监督到看完了。
2.容许短暂的不一致性
小军爸爸可能会发现「有时候据说小军看了某书,但事实上他还没看」,只要小军爸爸满意于「反正他最后看了就行」,异步处理就没问题。
如果小军爸爸对这情况不能容忍,对王阿姨大发雷霆,王阿姨也就不敢用书架方式了。
3.确实是用了有效果
即解耦、提速、广播、削峰这些方面的收益,超过放置书架、监控书架这些成本。
否则如果是盲目照搬,「听说老王家买了书架,咱们家也买一个」,买回来却没什么用,只是让步骤变多了,还不如直接把书递给对方呢,那就不对了。
三 主流消息中间件及比较
目前在市面上比较主流的消息队列中间件主要有,Kafka、ActiveMQ、RabbitMQ、RocketMQ等这几种。
不过我想说的是,ActiveMQ和RabbitMQ这两着因为吞吐量还有GitHub的社区活跃度的原因,在各大互联网公司都已经基本上绝迹了,
业务体量一般的公司会是有在用的,但是越来越多的公司更青睐RocketMQ这样的消息中间件了。Kafka和RocketMQ一直在各自擅长的领域发光发亮。
我这里用网上找的对比图让大家看看差距到底在哪里:

对比发现,如果你不做大数据或日志采集方面的东西,那么RocketMQ是最佳选择
四、RocketMQ基本概念
RocketMQ是阿里出品的一款开源的消息中间件,让其声名大噪的就是它的事务消息的功能。在企业中,消息中间件选择使用RocketMQ的还是挺多的,这一系列的文章都是针对RocketMQ的,咱们先从RocketMQ的一些基本概念和环境的搭建开始聊起。
RocketMQ由4部分组成,分别是:名称服务(Name Server)、消息队列(Brokers)、生产者(producer)和消费者(consumer)。这4部分都可以进行水平扩展,从而避免单点故障,如下图,

这是RocketMQ官网上的一张图,非常清晰的列出了4个部分,并且都是集群模式。下面我们就分别说一说这4部分。
4.1 名称服务(NameServer)
Name Server扮演的角色是一个注册中心,和Zookeeper的作用差不多。它的主要功能有两个,如下:
broker的管理:broker集群将自己的信息注册到NameServer,NameServer提供心跳机制检测每一个broker是否正常。
路由管理:每一个NameServer都有整个broker集群和队列的信息,以便客户端(生产者和消费者)查询。
NameServer协调着分布式系统中的每一个组件,并且管理着每一个Topic的路由信息。
4.2 Broker
Broker主要是存储消息,并且提供Topic的机制。它提供推和拉两种模式,还有一些容灾的措施,比如可以配置消息副本。下面我们看一看Brokcer的主从机制。
Broker的角色分为“异步主”、“同步主”和“从”三个角色。如果你不能容忍消息的丢失,你可以配置一个“同步主”和“从”两个Broker,如果你觉得消息丢失也无所谓,只要队列可用就ok的话,你可以配置“异步主”和“从”两个broker。如果你只是想简单的搭建,只配置一个“异步主”,不配置“从”也是可以的。
上面提到的是broker之间的备份,broker里的信息也是可以保存到磁盘的,保存到磁盘的方式也有两种,推荐的方式是异步保存磁盘,同步保存磁盘是非常损耗性能的。
4.3 生产者
生产者支持集群部署,它们向broker集群发送消息,而且支持多种负载均衡的方式。
当生产者向broker发送消息时,会得到发送结果,发送结果中有一个发送状态。假设我们的配置中,消息的配置isWaitStoreMsgOK = true,这个配置默认也是true,如果你配置为false,在发送消息的过程中,只要不发生异常,发送结果都是SEND_OK。当isWaitStoreMsgOK = true,发送结果有以下几种,
FLUSH_DISK_TIMEOUT:保存磁盘超时,当保存磁盘的方式设置为SYNC_FLUSH(同步),并且在syncFlushTimeout配置的时间内(默认5s),没有完成保存磁盘的动作,将会得到这个状态。
FLUSH_SLAVE_TIMEOUT:同步“从”超时,当broker的角色设置为“同步主”时,但是在设置的同步时间内,默认为5s,没有完成主从之间的同步,就会得到这个状态。
SLAVE_NOT_AVAILABLE:“从”不可用,当我们设置“同步主”,但是没有配置“从”broker时,会返回这个状态。
SEND_OK:消息发送成功。
再来看看消息重复与消息丢失,当你发现你的消息丢失时,通常有两个选择,一个是丢就丢吧,这样消息就真的丢了;另一个选择是消息重新发送,这样有可能引起消息重复。通常情况下,还是推荐重新发送的,我们在消费消息的时候要去除掉重复的消息。
发送message的大小一般不超过512k,默认的发送消息的方式是同步的,发送方法会一直阻塞,直到等到返回的响应。如果你比较在意性能,也可以用send(msg, callback)异步的方式发送消息。
4.4 消费者
多个消费者可以组成消费者组(consumer group),不同的消费者组可以订阅相同的Topic,也可以独立的消费Topic,每一个消费者组都有自己的消费偏移量。
消息的消费方式一般有两种,顺序消费和并发消费。
顺序消费:消费者将锁住消息队列,确保消息按照顺序一个一个的被消费掉,顺序消费会引起一部分性能损失。在消费消息的时候,如果出现异常,不建议直接抛出,而是应该返回SUSPEND_CURRENT_QUEUE_A_MOMENT这个状态,它将告诉消费者过一段时间后,会重新消费这个消息。
并发消费:消费者将并发的消费消息,这种方式的性能非常好,也是推荐的消费方式。在消费的过程中,如果出现异常,不建议直接抛出,而是返回RECONSUME_LATER状态,它告诉消费者现在不能正确的消费它,过一段时间后,会再次消费它。
在消费者内部,是使用ThreadPoolExecutor作为线程池的,我们可以通过setConsumeThreadMin和setConsumeThreadMax设置最小消费线程和最大消费线程。
当一个新的消费者组建立以后,它要决定是否消费之前的历史消息,CONSUME_FROM_LAST_OFFSET将忽略历史消息,消费新的消息。CONSUME_FROM_FIRST_OFFSET将消费队列中的每一个消息,之前的历史消息也会再消费一遍。CONSUME_FROM_TIMESTAMP可以指定消费消息的时间,指定时间以后的消息会被消费。
如果你的应用不能容忍重复消费,那么在消费消息的过程中,要做好消息的校验。
4.5 Topic
首先看看官方的定义:
Topic是生产者在发送消息和消费者在拉取消息的类别。Topic与生产者和消费者之间的关系非常松散。具体来说,一个Topic可能有0个,一个或多个生产者向它发送消息;相反,一个生产者可以发送不同类型Topic的消息。类似的,消费者组可以订阅一个或多个主题,只要该组的实例保持其订阅一致即可。
Topic在百度翻译中解释为话题或主题。我们可以理解为第一级消息类型,类比于书的标题。在应用系统中,一个Topic标识为一类消息类型,比如交易信息。
在Producer中使用Topic:
Message msg = new Message("TopicTest" /* Topic */,
"TagA",("Hello RocketMQ " + i).getBytes(RemotingHelper.DEFAULT_CHARSET));在Consumer中订阅Topic:
consumer.subscribe("TopicTest", "*");4.6.Tag
同样,先看看官方怎么定义的:
tag即标签,换句话的意思就是子主题,为用户提供了额外的灵活性。有了标签,来自同一业务模块的具有不同目的的消息可以具有相同的主题和不同的标记。标签有助于保持代码的清晰和连贯,同时标签也方便RocketMQ提供的查询功能。
Tag在百度翻译中解释为标签。我们可以理解为第二级消息类型,类比于书的目录,方便检索使用消息。在应用系统中,一个Tag标识为一类消息中的二级分类,比如交易信息下的交易创建、交易完成。
在Producer中使用Tag:
Message msg = new Message("TopicTest",
"TagA" /* Tag */,
("Hello RocketMQ " + i).getBytes(RemotingHelper.DEFAULT_CHARSET));在Consumer中订阅Tag:
consumer.subscribe("TopicTest", "TagA||TagB");// * 代表订阅Topic下的所有消息4.7.GroupName
和现实世界中一样,RocketMQ中也有组的概念。代表具有相同角色的生产者组合或消费者组合,称为生产者组或消费者组。作用是在集群HA的情况下,一个生产者down之后,本地事务回滚后,可以继续联系该组下的另外一个生产者实例,不至于导致业务走不下去。在消费者组中,可以实现消息消费的负载均衡和消息容错目标。
另外,有了GroupName,在集群下,动态扩展容量很方便。只需要在新加的机器中,配置相同的GroupName。启动后,就立即能加入到所在的群组中,参与消息生产或消费。
在Producer中使用GroupName:
DefaultMQProducer producer = new DefaultMQProducer("group_name_1");// 使用GroupName来初始化Producer,如果不指定,就会使用默认的名字:DEFAULT_PRODUCER在Consumer中使用GroupName:
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("group_name_1");// 使用GroupName来初始化Consumer,如果不指定,就会使用默认的名字:DEFAULT_CONSUMER好了,这一篇就介绍到这里。