利用上一篇文章介绍的方法生成模型后,就可以利用该模型进行服务了。不过上一篇文章主动设了项目名称的参数,这样得到的模型目录不会出现default文件夹,在调用服务的时候估计得加入对应的项目名称参数才能正常运行。如果不想/不会在用cmd启动服务的时候加入这个参数,需要对调用train.py的命令参数进行修改。修改后的命令为(需要在控制台cd到项目根目录E:\workspace-python\Rasa_NLU_Chi\后再执行命令):
python -m rasa_nlu.train -c sample_configs/config_jieba_mitie_sklearn.yml --data data/examples/rasa/demo-rasa_zh.json --path models启动服务
windows下启动服务运行参数:-m -c ../sample_configs/config_jieba_mitie_sklearn.yml --path models
如果运行报错No module named 'tubes',那么就安装tubes。
如果是在控制台里运行,cd到项目根目录后使用命令:
python -m rasa_nlu.server -c sample_configs/config_jieba_mitie_sklearn.yml --path models截止到2021-3-4 利用Pycharm启动服务后,在浏览器中调用localhost:5000/parse?q=你好,会报错:
{
"error": "No project found with name 'default'."
}暂时不知道如何解决。
测试服务
在控制台上启动服务后,使用浏览器打开localhost:5000/parse?q=你好
报错:
{
"error": "y should be a 1d array, got an array of shape (1, 5) instead."
}打开一个新的终端,使用curl命令获取结果
curl -XPOST localhost:5000/parse -d '{"q":"明天天气预报", "project":"default", "model":"model_20210304-083819"}'服务器会报错:builtins.UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc3 in position 4: invalid continuation byte
另外,命令行里显示的内容看不清楚,可以在浏览器里试试。直接输入localhost:5000回车会显示:hello from Rasa NLU: 0.12.2。而Rasa的版本号已经到了2.3.4。
将报错内容复制到html文件里用浏览器打开会看得更清楚:

上面三类报错暂时封锁了我前进的道路,无奈之下准备再次使用系列文章中第一篇的方法,试图在test_server.py中找到线索。
首先,安装缺少的treq模块。在tests/base目录下(cd E:\workspace-python\Rasa_NLU_Chi\tests\base)运行py.test -q test_config.py,报错如下:
======================================================= ERRORS ========================================================
_____________________________________ ERROR collecting tests/base/test_server.py ______________________________________
test_server.py:49: in <module>
???
E AttributeError: module 'pytest' has no attribute 'inlineCallbacks'
--------------------------------------------------- Captured stdout ---------------------------------------------------将pytest模块从6.2.1升级到6.2.2。源项目中给的pytest==3.3.2。pytest6.2.2中没有inlineCallbacks,找了一个小时发现pytest_twisted中有inlineCallbacks,解决了一个问题。不过报错内容发生了新的变化:
13 passed, 106 warnings, 6 errors in 5.99s看了看具体的报错都是路径的问题。然后发现更加正确的姿势——需要cd到项目的根目录:cd E:\workspace-python\Rasa_NLU_Chi,然后执行命令:py.test -q tests\base\test_server.py,这样本系列里面第一篇文章修改代码中的一些路径的做法就是冗余的了。笔记本的计算速度非常慢,一中午时间就出了几个点。

在浏览器中输入http://localhost:5000/status,会显示:
{
"available_projects": {
"default": {
"status": "ready",
"available_models": [
"model_20210304-083819"
],
"loaded_models": []
}
}
}loaded_models居然为空,莫非是启动服务的时候参数没设对?暂时放下这个问题,突然对于解决上面提到的1d array的报错似乎有了思路:
{
"error": "y should be a 1d array, got an array of shape (1, 5) instead."
}在文件sklearn_intent_classifier.py中略加几行自己的代码可以得到(1,5)具体的数据,如:[[2 1 0 4 3]],也许该用一对中括号来取代这两对中括号。果然,这样处理以后就又迈进了一步,浏览器中输入http://localhost:5000/parse?q=hello终于可以得到有效结果了:
{
"intent": {
"name": "greet",
"confidence": 0.6839311949011121
},
"entities": [],
"intent_ranking": [
{
"name": "greet",
"confidence": 0.6839311949011121
},
{
"name": "goodbye",
"confidence": 0.12847934411644726
},
{
"name": "affirm",
"confidence": 0.10961868150457925
},
{
"name": "restaurant_search",
"confidence": 0.044551661168386866
},
{
"name": "medical",
"confidence": 0.033419118309474166
}
],
"text": "hello"
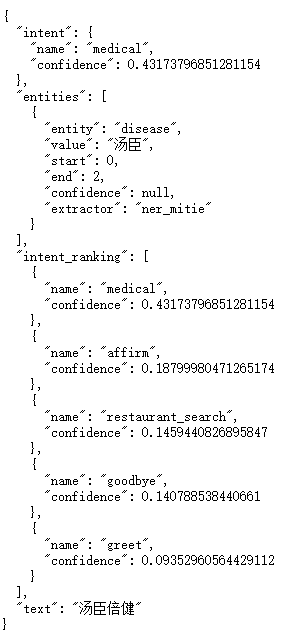
}也支持中文输入,如输入汤臣倍健会得到: