SQL专栏
SQL基础知识汇总
SQL高级知识汇总
鉴于不少同学对SQL优化不是很感兴趣,以后放在次条推送,有兴趣的小伙伴还请继续关注。
上一讲我们使用DISTINCT来去掉重复行以提高查询效率,这和小伙伴们平常听到的一条优化建议:尽量少使用DISTINCT相悖。下面我们来看看DISTINCT到底该不该使用。如果不想看处理过程的可以直接跳到红色结论部分。
1.使用DISTINCT去掉重复数据
我们重复一下上一讲的例子:
SELECT DISTINCT UnitPrice
FROM [Sales].[SalesOrderDetail]
WHERE UnitPrice>1000;
执行完之后的结果如下:

接下来,我们将这个表里的数据增大到194万条,再重复上面的实验。
--将表SalesOrderDetail插入到一张物理表中
SELECT * INTO Sales.Temp_SalesOrder
FROM [Sales].[SalesOrderDetail] ;
--通过新增的物理表进行自循环插入3次,将数据增加到1941072行
DECLARE @i INT;
SET @i=0
WHILE @i<4
BEGIN
--这里没有将SalesOrderDetailID这个自增长的放在列中,是为了让系统自动填充不同的数字进去,保证唯一性。
INSERT INTO Sales.Temp_SalesOrder
(SalesOrderID,CarrierTrackingNumber,OrderQty,ProductID,SpecialOfferID,
UnitPrice,UnitPriceDiscount,LineTotal,rowguid,ModifiedDate)
SELECT
SalesOrderID,CarrierTrackingNumber,OrderQty,ProductID,SpecialOfferID,
UnitPrice,UnitPriceDiscount,LineTotal,NEWID(),ModifiedDate
FROM Sales.Temp_SalesOrder
SET @i=@i+1;
END;
SELECT COUNT(1) FROM Sales.Temp_SalesOrder;
(提示:可以左右滑动代码)
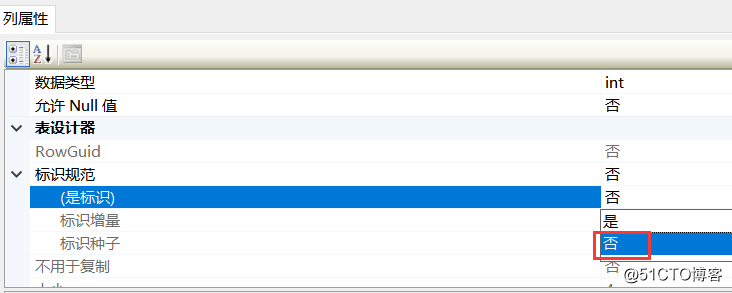
将SalesOrderDetailID的自增长属性取消掉之后,插入1000条自身的数据,这样我们就可以得到1000条重复的SalesOrderDetailID,相比1942072条记录占比很小了
如下图,将自增长标识的是换成否后即可插入了。
INSERT INTO sales.Temp_Salesorder
SELECT TOP 1000 * FROM sales.Temp_Salesorder;
数据插入完整后,我们在将上一讲的内容重复一下,看看效果如何?
A.在没建索引的情况下,我们只查询UnitPrice这一列
SELECT UnitPrice FROM Sales.Temp_SalesOrder ;
我们看一下执行情况:

接下来是鉴证奇迹的时刻了,我们加DISTINCT在UnitPrice前面试试
SELECT DISTINCT UnitPrice FROM sales.Temp_Salesorder;

和之前的实验结果一致,在执行时间没有多大差别的情况下,分析时间成倍的减少了。
B.当SalesOrderDetailID取消掉自增长属性后就和普通列一样了。
我们来重复上面的步骤:
SELECT SalesOrderDetailID FROM sales.Temp_Salesorder
执行完后结果如下:

与上面的UnitPrice没使用DISTINCT情况基本一致。
然后我们给SalesOrderDetailID加上DISTINCT后会怎么样呢?
SELECT DISTINCT SalesOrderDetailID
FROM sales.Temp_Salesorder
我们可以看到如下执行情况:

从上图可以看到,DISTINCT已经排除了1000条记录,但是在执行时花的时间比没加DISTINCT更久了。
通过上述两个实验,我们可以得出这样一条结论:在重复量比较高的表中,使用DISTINCT可以有效提高查询效率,而在重复量比较低的表中,使用DISTINCT会严重降低查询效率。所以并不是所有的DISTINCT都是降低效率的,当然你得提前判断数据的重复量。
2.GROUP BY与DISTINCT去掉重复数据的对比
GROUP BY与DISTINCT类似,经常会有一些针对这两个哪个效率高的争议,今天我们就将这两个在不同重复数据量的效率作下对比。
A.重复数据量多的情况下,对UnitPrice进行去重
SELECT DISTINCT UnitPrice FROM sales.Temp_Salesorder;
SELECT UnitPrice FROM sales.Temp_Salesorder GROUP BY UnitPrice;将上述两条语句一起执行,结果如下:

可以看出两条语句对应的执行时间GROUP BY比DISTINCT效率高一点点。
B.重复数据量少的情况下,对SalesOrderDetailID进行去重
SELECT DISTINCT SalesOrderDetailID FROM sales.Temp_Salesorder
SELECT SalesOrderDetailID FROM sales.Temp_Salesorder
GROUP BY SalesOrderDetailID
也是同时执行上述两条语句,其结果如下:
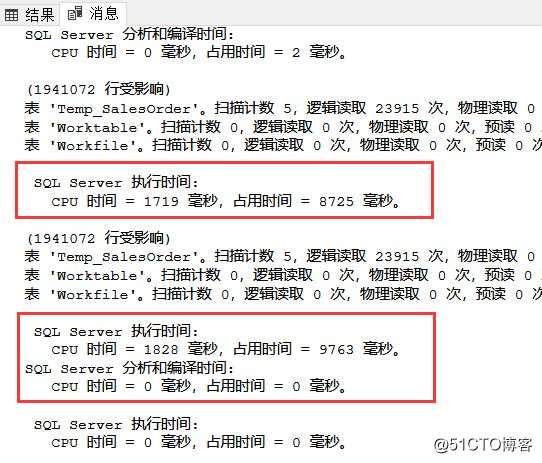
作者对上述语句同时执行多次,针对重复量多的UnitPrice,GROUP BY总的处理效率比DISTINCT高一点点,但是针对重复量低的SalesOrderDetailID,DISTINCT就比GROUP BY快一点了,而如果随着整体数据量的增加,效果会越来越明显。
今天的课就讲到这里,小伙伴可以动手尝试一下。如有不明白的可以在下方留言一起探讨。