一、cpu使用
从计算每个CPU模式的每秒速率开始。PromQL有一个名为irate的函数,用于计算距离向量中时间序列的每秒瞬时增长率。让我们在``node_cpu_seconds_total`度量上使用irate函数。在查询框中输入:
irate(node_cpu_seconds_total{job="node"}[5m])
avg(irate(node_cpu_seconds_total{job="node"}[5m])) by (instance)
现在,我们将irate函数封装在avg聚合中,并添加了一个by子句,该子句通过实例标签聚合。这将产生三个新的指标,使用来自所有CPU和所有模式的值来平均主机的CPU使用情况。
avg (irate(node_cpu_seconds_total{job="node",mode="idle"}[5m])) by (instance) * 100
在这里,我们查询中添加了一个值为idle的mode标签。这只查询空闲数据。我们通过实例求出结果的平均值,并将其乘以100。现在我们在每台主机上都有5分钟内空闲使用的平均百分比。我们可以把这个变成百分数用这个值减去100,就像这样:
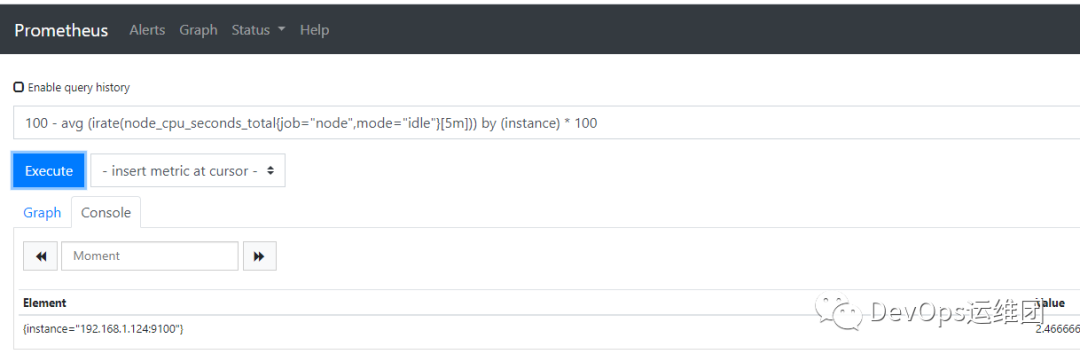
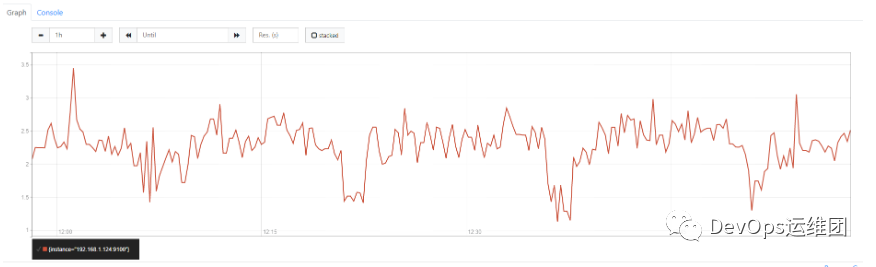
100 - avg (irate(node_cpu_seconds_total{job="node",mode="idle"}[5m])) by (instance) * 100
现在我们有三个指标,每个主机一个指标,显示5分钟窗口内使用的平均CPU百分比。

二、内存使用
以node_memory为前缀的指标列表中找到它们。
将关注node_memory度量的一个子集,以提供我们的利用率度量:
• node_memory_MemTotal_bytes - 主机上的总内存
• node_memory_MemFree_bytes - 主机上的空闲内存
• node_memory_Buffers_bytes_bytes - 缓冲区缓存中的内存
• node_memory_Cached_bytes_bytes - 页面缓存中的内存。
所有这些指标都以字节表示。
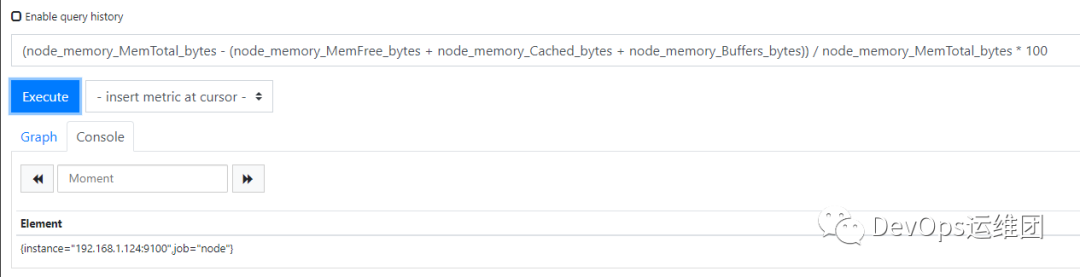
(node_memory_MemTotal_bytes-(node_memory_MemFree_bytes+ node_memory_Cached_bytes + node_memory_Buffers_bytes))
/ node_memory_MemTotal_bytes * 100
三、磁盘使用
对于磁盘,我们只测量磁盘使用情况而不是使用率、饱和度或错误。这是因为在大多数情况下,它是对可视化和警报最有用的数据。Node Exporter的磁盘使用指标位于以node_filesystem为前缀的指标列表
例如,node_filesystem_size_bytes指标显示了被监控的每个文件系统挂载的大小。我们可以使用与内存指标类似的查询来生成在主机上使用的磁盘空间的百分比。但是,与内存指标不同,我们在每个主机上的每个挂载点都有文件系统指标。所以我们添加了mountpoint标签,特别是根文件系统“/”挂载。这将在每台主机上返回该文件系统的磁盘使用指标。
(node_filesystem_size_bytes{mountpoint="/"} - node_filesystem_free_bytes{mountpoint="/"})
/ node_filesystem_size_bytes{mountpoint="/"} * 100

Grafana 可以汉化,同时可以导入mysql、redis等监控模板
↓↓ 点击"阅读原文" 【加入DevOps运维团】
相关阅读:
3、Prometheus+Alertmanager配置邮件报警
请分享到朋友圈扫码关注
