
21CTO社区导读:
今天我们来讨论关于一个非常有意义的话题,这就是推荐系统。我们讨论如何使用Python来构建推荐系统,我们将焦点和一些详细深度着重在如何让推荐系统干活。
在这篇手册中,我们将讨论以下两个主题:
1、为什么需要推荐系统
2、怎样构建推荐系统

本文篇幅较长,敬请耐心阅读,选择咖啡还是啤酒,需要有一点耐心。我将一步步的介绍推荐系统工作,辅以实战,希望我们都有自己的推荐系统。
我们核心的目标是从基础(零起点)开始,用Python构建推荐引擎,未来的你也可以有能力用python实现自己的推荐系统。
我会把Git仓库链接发出来,里面有全部的Python文件,请尽管拿去。
下面,我们再将两个主要题目分成若干个小主题,如下:
1)什么是推荐引擎与实例
2)收集过滤器与基于内容的方法
3)一步一步构建推荐系统
(1)余弦相似性
(2)个性化相关
4)小结
1 推荐引擎与实例
首先,我们思考一下你在Youtube上最后一次看的歌曲。你或许知道,Youtube最近更新了UI,并且增加了自动播放按钮。
假设你正在学习计算机科学技术,你可能不记得最后关闭的标签,或者最后一次考试通过的页面是什么。但是你喜欢的歌放完后,系统会继续播放你喜欢或这首歌类似的歌曲或讲座。
这个魔法肯定不是自动播放按钮在起作用。而是Youtube的系统在后台计算一些公式后,提供最合适的内容匹配,对我们来说最好的歌曲。这样的系统被称为推荐系统或推荐引擎。
1.1 推荐系统类型
推荐系统有不同的类型,包括如下:
电影推荐引擎
商品推荐引擎
机器学习推荐引擎
使用商品推荐算法的个性化商品推荐引擎
预测引擎
音乐推荐引擎
这些推荐系统均基于机器学习,输入数据需要一些由个人或其它离散的系统收集,根据个人行为,推荐新的内容。
有不少新手工程师会混淆这两种类型的输入集合。我们来看一些例子:
个人用户数据输入:
喜欢/不喜欢
赞/贬
评论
分享等
从其它离散系统的输入
1 从用户互动行为中实时收集数据
Youtube: 在较短时间内有大量的同样的短语(关键词)搜索
Google: 用户打开大量类似的网站
Twitter/Facebook:一些公众号(商业,市场,娱乐...)被大量关注(订阅)
2 通过询问兴趣来收集数据(用户注册或提供兴趣资料后)
Tumblr
StumbleUpon
Flickr
2 协同过滤
想要了解如何构建推荐系统,需要了解协同过滤(Collaborative Filtering)的一些基础知识。
Google一下“Collaborative Filtering”,我们会在Wikipedia得到如下定义:
In the newer, narrower sense, collaborative filtering is a method of making automatic predictions (filtering) about the interests of a user by collecting preferences or taste information from many users (collaborating).
译文:
在较新的狭义定义下,协同过滤通过收集来自大量用户的偏好和品味信息(协作)来对用户兴趣进行自动预测(过滤)的方法。
如前所述,要理解如何构建推荐系统,要有两个数据输入选项。我们需求有一个反馈功能系统,比如像喜欢/不喜欢或任何其它表单订阅和用户互动。很明显,我们没有办法从用户那提取到任何关于他个性化兴趣的信息。
但是我们知道谁连接了我们的系统或网站,给他们提供了什么,是全部服务还是部分服务。但是我们没法检测与用户兴趣类似的其它任何内容,因为没有反馈,没有评论,没有赞等功能,只能拿到小部分数据。
为解决此问题,我们采用协同过滤方法,这种方法是基于机器学习算法和人工智能,暂时稍后讨论。
WordPress.com,Google,Youtube等经常使用协同过滤方法,它给用户提供非常好的建议,包括推荐和内容输出。但是它们怎么工作的?
那么,我们暂时不在人工智能上讨论更多细节,而是使用一些例子来掌握基础知识。
2.1 实例 - 谷歌
谷歌有一支个性化的广告系统,用来展示自身网站或合作伙伴上的广告。同时,它也会从用户浏览器中收集数据,包括浏览器名称,网络服务商,搜索关键字,用户观看过的视频等。
这个数据对于系统来说意义重大,但对个人来说甲是垃圾,对另一个人则是黄金。Google通过这些信息,对关键字相关性,页面相似性,页面权限等进行实时计算。
通过大量的预测和分析,为用户提供个性化的广告,在大多数的情况下,你会看到感兴趣的广告内容。就像微信朋友圈中大家点赞的广告,是同样的道理。

内容推荐系统
“如何构建一个推荐系统”,包含一个或多种类型的算法,这被称为“基于内容的方法/算法”。
在一个基于内容的推荐系统里,使用关键字来描述项目,并且构建用户画像,用以描述该用户喜欢的项目类型。换句话说,这些算法尝试推荐用户喜欢的项目(或正在进行的测试)—— Wikipedia
基于内容的方法是基于用户交互(UI),这意味着用户能够提供关于内容的反馈。这些反馈包括多种方式获得:喜欢/不喜欢,评分,分享等。
这种方法通常用于电子商务或视频网站。
系统从用户交互中提取数据,把这些数据保存在数据。当同一个用户再次访问网站时,就可以访问到自己喜欢的内容。与此同时,系统根据协同过滤算法,决定用户应该获得到哪些内容。综合以上例子,就可以看到其中的差异。
3.1 实例 - YouTube
Youtube的推荐和Google不一样(虽然YouTube是Google子公司)。用户画像是通过视频阅读的用户交互(UI)获得的。我们可以喜欢或不喜欢某个视频,分享到社交网站或者发表评论。
每次我们给视频点一个赞/喜欢,都是告诉系统我们对什么样的视频(喜剧,教育、记录片)等感兴趣。这些信息是在Youtube顺序排列的,之后它会根据算法公式,为你所观看的视频提供更精确的内容服务。如果我们对某个产品不满意,它会从你的兴趣列表中删除。
我们看到的两类系统是非常复杂的,这一切都基于人工智能,但是用基本的推荐系统并不那么复杂,不需要任何AI方面的知识。
4 一步一步构建推荐系统
在学习前,比较容易构建的基于内容的推荐器系统。在继续之前,我们可以看一张与此相关的图。
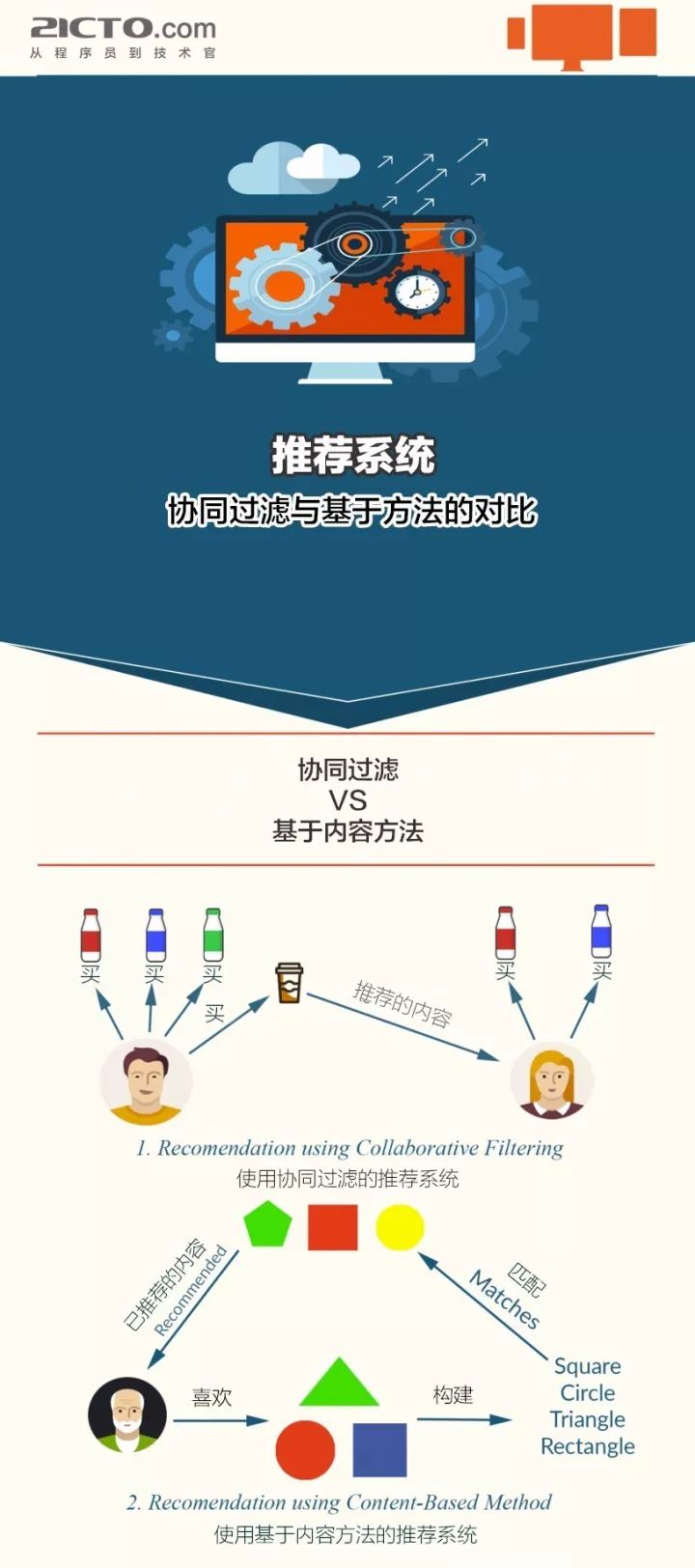
如何构建推荐系统 协同过滤与基于内容的方法的差异
第一步,我们需要一些基础工具和环境来设置。需要如下:
Python环境和IDE(推荐使用Pytharm)
一些学习的数据
一些测试数据
学习数据:
UserRatings={
'Lisa Rose':{
'Catch Me If You Can':3.0,
'Snakes on a Plane':3.5,
'Superman Returns':3.5,
'You, Me and Dupree':2.5,
'The Night Listener':3.0,
'Snitch':3.0
},
'Gene Seymour':{
'Lady in the Water':3.0,
'Snakes on a Plane':3.5,
'Just My Luck':1.5,
'The Night Listener':3.0,
'You, Me and Dupree':3.5
},
'Michael Phillips':{
'Catch Me If You Can':2.5,
'Lady in the Water':2.5,
'Superman Returns':3.5,
'The Night Listener':4.0,
'Snitch':2.0
},
'Claudia Puig':{
'Snakes on a Plane':3.5,
'Just My Luck':3.0,
'The Night Listener':4.5,
'Superman Returns':4.0,
'You, Me and Dupree':2.5
},
'Mick LaSalle':{
'Lady in the Water':3.0,
'Snakes on a Plane':4.0,
'Just My Luck':2.0,
'Superman Returns':3.0,
'You, Me and Dupree':2.0
},
'Jack Matthews':{
'Catch Me If You Can':4.5,
'Lady in the Water':3.0,
'Snakes on a Plane':4.0,
'The Night Listener':3.0,
'Superman Returns':5.0,
'You, Me and Dupree':3.5,
'Snitch':4.5
},
'Toby':{
'Snakes on a Plane':4.5,
'Snitch':5.0
},
'Michelle Nichols':{
'Just My Luck':1.0,
'The Night Listener':4.5,
'You, Me and Dupree':3.5,
'Catch Me If You Can':2.5,
'Snakes on a Plane':3.0
},
'Gary Coleman':{
'Lady in the Water':1.0,
'Catch Me If You Can':1.5,
'Superman Returns':1.5,
'You, Me and Dupree':2.0
},
'Larry':{
'Lady in the Water':3.0,
'Just My Luck':3.5,
'Snitch':1.5,
'The Night Listener':3.5
}
}
如果你不知道上面的代码是什么,我会继续解释的。如果你懂,可以跳过这一部分。
这里“UserRatings”是一个Python数据集(JSON)。 在此集合中,我们保留用户名,并为每个用户名保留电影的评分。 例如:
'Lisa Rose':{
'Catch Me If You Can':3.0,
'Snakes on a Plane':3.5,
'Superman Returns':3.5,
'You, Me and Dupree':2.5,
'The Night Listener':3.0,
'Snitch':3.0
}
该用户名是Lisa Rose,Lisa给电影做了一些适当的评分:
movie: Catch Me If You Can / Snakes on a Plane
rating: 3.0 / 3.5
这是这位用户对电影的评分。重要的我们需要知道相关电影的变化 ,因为并不是所有电影这个用户都会参与评分。例如;
'Lisa Rose':{
'Catch Me If You Can':3.0,
'Snakes on a Plane':3.5,
'Superman Returns':3.5,
'You, Me and Dupree':2.5,
'The Night Listener':3.0,
'Snitch':3.0
}
'Michelle Nichols':{
'Just My Luck':1.0,
'The Night Listener':4.5,
'You, Me and Dupree':3.5,
'Catch Me If You Can':2.5,
'Snakes on a Plane':3.0
}
两个相关电影数据:You,Me and Dupree,Catch Me if You Can与Snakes on a Plane。没有评分的有:Just My Luck,Superen Returns,Snitch。
You, Me and Dupree':{
'Lisa Rose':3.5,
'Michelle Nichols':3.5,
}
需要进行转换,我们需要定义自己的函数,命名为transform()。
MovieRates={} #Declaring empty set for our new transformed data
def transform(): #Transformation Set
for person in UserRatings:
for movie in User[person]:
if movie not in MovieRates:
MovieRates[movie]={}
MovieRates[movie][person]=UserRatings[person][movie]
该程序执行后的返回结果如下:
{ 'The Night Listener':{ 'Michelle Nichols':4.5, 'Jack Matthews':3.0, 'Lisa Rose':3.0, 'Michael Phillips':4.0, 'Gene Seymour':3.0, 'Larry':3.5, 'Claudia Puig':4.5 }, 'Snitch':{ 'Toby':5.0, 'Larry':1.5, 'Jack Matthews':4.5, 'Lisa Rose':3.0, 'Michael Phillips':2.0 }, 'Superman Returns':{ 'Jack Matthews':5.0, 'Lisa Rose':3.5, 'Michael Phillips':3.5, 'Mick LaSalle':3.0, 'Gary Coleman':1.5, 'Claudia Puig':4.0 }, 'Just My Luck':{ 'Michelle Nichols':1.0, 'Gene Seymour':1.5, 'Claudia Puig':3.0, 'Mick LaSalle':2.0, 'Larry':3.5 }, 'You, Me and Dupree':{ 'Michelle Nichols':3.5, 'Jack Matthews':3.5, 'Lisa Rose':2.5, 'Mick LaSalle':2.0, 'Gene Seymour':3.5, 'Gary Coleman':2.0, 'Claudia Puig':2.5 }, 'Snakes on a Plane':{ 'Toby':4.5, 'Michelle Nichols':3.0, 'Jack Matthews':4.0, 'Lisa Rose':3.5, 'Gene Seymour':3.5, 'Mick LaSalle':4.0, 'Claudia Puig':3.5 }, 'Catch Me If You Can':{ 'Michelle Nichols':2.5, 'Michael Phillips':2.5, 'Jack Matthews':4.5, 'Lisa Rose':3.0, 'Gary Coleman':1.5 }, 'Lady in the Water':{ 'Mick LaSalle':3.0, 'Jack Matthews':3.0, 'Larry':3.0, 'Gene Seymour':3.0, 'Michael Phillips':2.5, 'Gary Coleman':1.0 }}
限于篇幅限制,下篇继续。