开源代码:https://github.com/jfzhang95/pytorch-video-recognition
系统:Ubuntu16.04 显卡1070
编译器:pycharm
UCF数据集包括101类视频,分别是:
1 ApplyEyeMakeup
2 ApplyLipstick
3 Archery
4 BabyCrawling
5 BalanceBeam
6 BandMarching
7 BaseballPitch
8 Basketball
9 BasketballDunk
10 BenchPress
11 Biking
12 Billiards
13 BlowDryHair
14 BlowingCandles
15 BodyWeightSquats
16 Bowling
17 BoxingPunchingBag
18 BoxingSpeedBag
19 BreastStroke
20 BrushingTeeth
21 CleanAndJerk
22 CliffDiving
23 CricketBowling
24 CricketShot
25 CuttingInKitchen
26 Diving
27 Drumming
28 Fencing
29 FieldHockeyPenalty
30 FloorGymnastics
31 FrisbeeCatch
32 FrontCrawl
33 GolfSwing
34 Haircut
35 HammerThrow
36 Hammering
37 HandstandPushups
38 HandstandWalking
39 HeadMassage
40 HighJump
41 HorseRace
42 HorseRiding
43 HulaHoop
44 IceDancing
45 JavelinThrow
46 JugglingBalls
47 JumpRope
48 JumpingJack
49 Kayaking
50 Knitting
51 LongJump
52 Lunges
53 MilitaryParade
54 Mixing
55 MoppingFloor
56 Nunchucks
57 ParallelBars
58 PizzaTossing
59 PlayingCello
60 PlayingDaf
61 PlayingDhol
62 PlayingFlute
63 PlayingGuitar
64 PlayingPiano
65 PlayingSitar
66 PlayingTabla
67 PlayingViolin
68 PoleVault
69 PommelHorse
70 PullUps
71 Punch
72 PushUps
73 Rafting
74 RockClimbingIndoor
75 RopeClimbing
76 Rowing
77 SalsaSpin
78 ShavingBeard
79 Shotput
80 SkateBoarding
81 Skiing
82 Skijet
83 SkyDiving
84 SoccerJuggling
85 SoccerPenalty
86 StillRings
87 SumoWrestling
88 Surfing
89 Swing
90 TableTennisShot
91 TaiChi
92 TennisSwing
93 ThrowDiscus
94 TrampolineJumping
95 Typing
96 UnevenBars
97 VolleyballSpiking
98 WalkingWithDog
99 WallPushups
100 WritingOnBoard
101 YoYo本文实验使用的所有python包版本为:
joblib 0.14.1
numpy 1.18.5
opencv-python 3.4.1.15
pip 19.0.3
protobuf 3.14.0
scikit-learn 0.22.2.post1
scipy 1.4.1
setuptools 40.8.0
six 1.15.0
tensorboardX 2.1
torch 0.4.0
tqdm 4.53.0训练视频分类模型的方法可以参考开源代码的Readme。本文实验nEpochs改为50,snapshot改为5。train和val在训练完成后的准确率分别为99.7%和96%。训练完成后会在工程路径下产生一个run文件,如下:
模型下载:https://pan.baidu.com/s/1ykXuyZdth0cSZBMuTsYJ_Q
提取码:ajij
--------------------
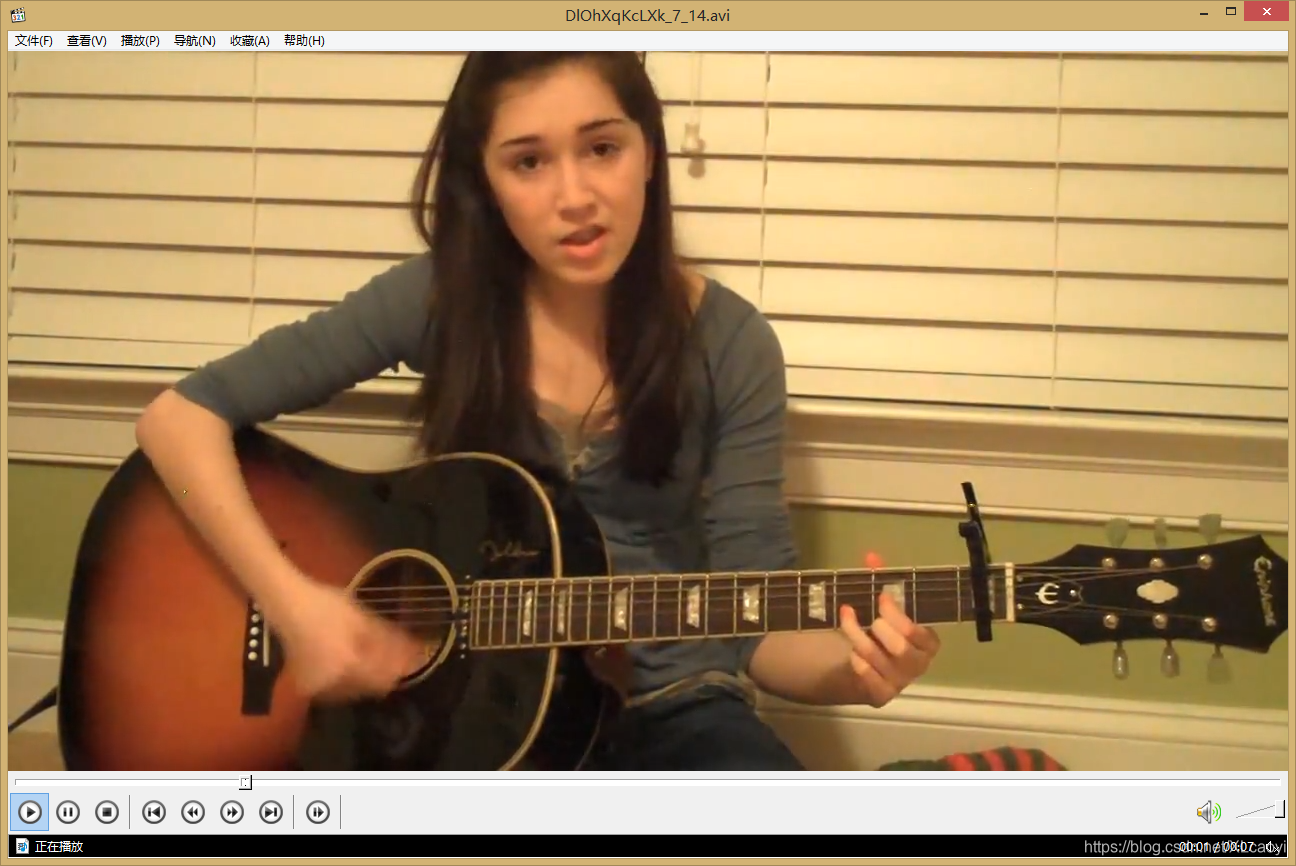
测试一个视频。我们选择MSVD数据集里面的DlOhXqKcLXk_7_14.avi,如图:
在训练工程中新建一个文件test.py,代码如下:
import torch
from torch import nn
import cv2 as cv
import numpy as np
from network import C3D_model
if __name__=='__main__':
model = C3D_model.C3D(num_classes=101, pretrained=False)
model = model.cuda()
checkpoint = torch.load('/home/dl/PycharmProjects/video_classify/run/run_0/models/C3D-ucf101_epoch-49.pth.tar', map_location=lambda storage, loc: storage)
model.load_state_dict(checkpoint['state_dict'])
model.eval()
capture = cv.VideoCapture('/home/dl/PycharmProjects/video_classify/DlOhXqKcLXk_7_14.avi')
frame_count = int(capture.get(cv.CAP_PROP_FRAME_COUNT))
frame_width = int(capture.get(cv.CAP_PROP_FRAME_WIDTH))
frame_height = int(capture.get(cv.CAP_PROP_FRAME_HEIGHT))
EXTRACT_FREQUENCY = 4
clip_len = 16
resize_height = 128
resize_width = 171
crop_size = 112
count = 0
retaining = True
#get frame frome video skip 4
frames = []
while (count < frame_count and retaining):
retaining, frame = capture.read()
if frame is None:
continue
if count % EXTRACT_FREQUENCY == 0:
frame = cv.resize(frame, (resize_width, resize_height))
frames.append(frame)
count += 1
#rgb int to buf float32
buffer = np.empty((frame_count, resize_height, resize_width, 3), np.dtype('float32'))
for i, frame in enumerate(frames):
frame = np.array(frame).astype(np.float64)
buffer[i] = frame
#c3d model need [112,112] and 16 frames
#time_index = np.random.randint(buffer.shape[0] - clip_len)
height_index = np.random.randint(buffer.shape[1] - crop_size)
width_index = np.random.randint(buffer.shape[2] - crop_size)
buffer = buffer[0:0 + clip_len,
height_index:height_index + crop_size,
width_index:width_index + crop_size, :]
#normalize
for i, frame in enumerate(buffer):
frame -= np.array([[[90.0, 98.0, 102.0]]])
buffer[i] = frame
#trans shape to [1,3,16,112,112]
crop_buffer = buffer.transpose(3, 0, 1, 2)
crop_buffer = np.expand_dims(crop_buffer, axis=0)
input = torch.from_numpy(crop_buffer)
input = input.cuda()
#
with torch.no_grad():
output = model(input)
probs = nn.Softmax(dim=1)(output)
preds = torch.max(probs, 1)[1]
print(preds)
输出为62(ID范围为[0~100]共101类),对应上面的 63 PlayingGuitar。
