大白话 时间 窗口 watermark
一、前言
通过前面几篇博客,我们学到的,仅仅是在代码层面上能够有些实践入门。但是什么是流式处理?Flink如何实现流式处理?Flink架构是什么样的?这些问题,我们还没有答案。
二、流处理术语
1 延迟和吞吐
对批处理而言,我们通常关心的是总执行时间(读取数据,执行计算,写回结果总共的时间)。但由于流处理的输入数据是源源不断的,所以流处理中没有总执行时间的概念。
流处理需要对到来的数据尽可能快的算,同时还要很高的事件接入速率。我们用延迟和吞吐分别表示这2个方面的性能。这2个指标并非相互独立,它们是相互影响的。
1.1 延迟
延迟表示处理一个事件所花费的时间。本质上,它是从接收事件到完成输出结果的时间间隔。都说Flink如何如何快,不是说Flink没有延迟。而是Flink能提供几毫秒这样的低延迟,相比批处理的几分钟延迟,可以说Flink是所谓的实时流处理架构。
1.2 吞吐
吞吐是用来衡量系统处理能力(处理速率)的指标,它表示系统每单位时间可以处理多少事件。对于流处理系统,我们肯定是希望延迟越低越好,吞吐越高越好。但是要注意,吞吐低不代表系统性能低。因为处理速率依赖数据到达的速率,如果数据源每隔5分钟发一次事件来,Flink在5ms内就处理完了,然后等待,那么吞吐还是低。
2 数据流上的操作
Flink引擎提供一系列内置操作实现数据流的获取、转换,和输出。这些操作可以是无状态的,也可以是有状态的。
状态,你可以理解为计算的中间结果,简单的map操作只是把当前输入值做个转换,和之前的输入没有关系,那就是无状态的。
reduce操作,例如求一串数字的最大值,Flink内部得记录当前的最大值,以便和后面的输入值比较,这个中间计算结果就是状态state。
2.1 数据接入和数据输出
数据接入就是从外部数据源获取原始数据,并将其转换成合适后续处理的格式。数据源可以是TCP套接字、文件、Kafka或传感器等。
数据输出就是把数据以合适外部系统的格式输出。
2.2 转换操作
转换操作是分别处理每个事件,对每个事件做转换后,结果就产生了一个新的输出流。
例如下图,把每个圆形转换为菱形。
2.3 滚动聚合
滚动聚合(如求和,求最大值,求最小值),它根据新来的事件,持续计算最新的结果。聚合操作都是有状态的,它把新来的事件和已有的状态一起计算,产生新的结果。
2.4 窗口操作
窗口操作时在无限的数据流上,产生有限的数据集,这个有限集合通常称为“桶”。例如每隔5分钟,求这个5分钟内数据的平均值,这5分钟内接入的数据集合是有限的。窗口操作还涉及到另外一个重要的概念:时间语义Time。
Flink的核心概念有4个:Window、Time、State和Checkpoint。他们是Flink的基石,接下来会单拎出来重点讲解。
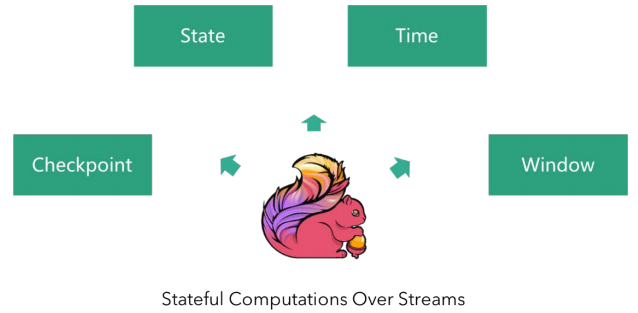
三、窗口 Window
咱们简单的想象下,在一个源源不断的数据流上,我们要截取其中一段数据进行计算。
例如:有一个数字流,1,3,2,3,5,6…这样的
每隔10秒钟计算一下:最近10秒内的数据的平均值
每来10个数计算一下:这10个数的平均值
这样好理解了,窗口机制就是在无限数据流上获取有限数据集合的一种方法。
1 按照业务维度分类
按照业务维度分类可以把窗口分为时间窗口和计数窗口。
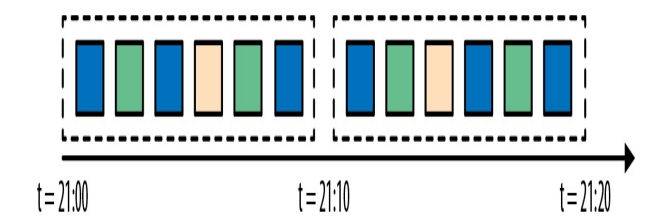
1.1 时间窗口 TimeWindow
每个事件的产生,它就天然的带上了时间属性,不管是事件的产生时间还是事件进入Flink的时间,这些时间都可以作为业务维度来划分窗口。
如下图:每隔10分钟,划分一个窗口。
1.2 计数窗口 CountWindow
事件是依次进入Flink的,以固定个数的事件为单位,划分窗口,就是计数窗口。
如下图:每4个事件,划分一个窗口。
2 按照窗口移动方式分类
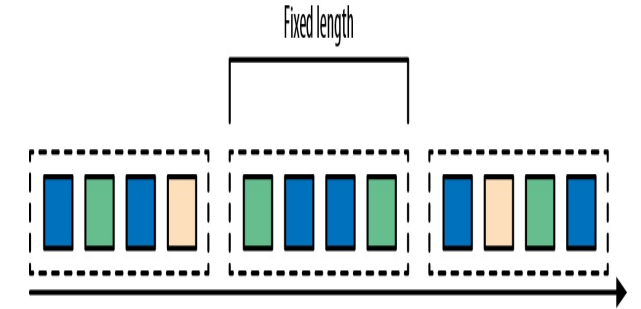
2.1 滚动窗口
滚动窗口将事件分配到长度固定且不重叠的桶中。
再按照业务维度,又可以在细分为滚动时间窗口和滚动计数窗口。

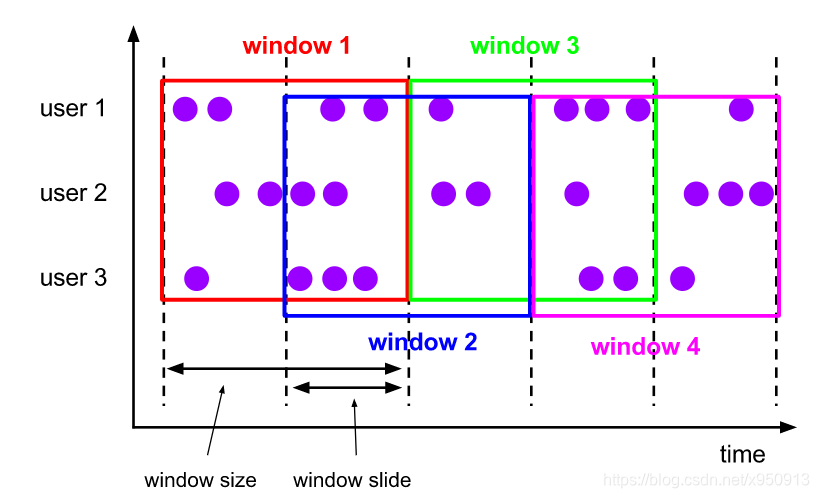
2.2 滑动窗口
滑动窗口将事件分配到大小固定且允许相互重叠的桶中,这意味着每个事件有可能同时属于多个桶。要指定窗口的长度和滑动间隔来定义滑动窗口。
再按照业务维度,又可以在细分为时间滑动窗口和计数滑动窗口。
如下图,假设每个window size=10s,窗口可以想右侧滑动,每次只滑动5s。
那么window2会和window1重叠5s,window3和window2重叠5s。举例:
- 每隔5秒钟,计算一次前10秒的数据
可以看出滑动窗口有2个参数,窗口大小 和 滑动步长。
窗口大小 > 滑动步长时,窗口之间有重叠,前2个窗口是下图的window1和window2。
窗口大小 = 滑动步长时,也就是滚动窗口了,前2个窗口是下图的window1和window3。
窗口大小 < 滑动步长时,窗口之间不会重叠,前2个窗口是下图的window1和window4,会遗漏数据。
2.3 会话窗口
会话窗口在一些常见的真实场景中非常有用,这些场景既不适合用滚动窗口,也不适用滑动窗口。
会话窗口(Session Windows)主要是将某段时间内活跃度较高的数据聚合成一个窗口进行计算,窗口的触发的条件是 Session Gap,是指在规定的时间内如果没有数据活跃接入,则认为窗口结束,然后触发窗口计算结果。
需要注意的是如果数据一直不间断地进入窗口,也会导致窗口始终不触发的情况。与滑动窗口、滚动窗口不同的是,Session Windows 不需要有固定 windows size 和 slide time,只需要定义 session gap,来规定不活跃数据的时间上限即可。

四、时间语义 Time
在流式计算中,时间Time是一个很重要的概念,这里不搬运官文解释,就举个栗子吧。
1 时间类型
假设有个股票数据量化系统:
- 首先爬虫从新浪财经上获取当前股票最新价格(每5秒取一次价格),然后推到Kafka。
- Flink程序从Kafka中获取数据。
- Flink程序每隔1分钟计算最近1分钟的股价平均值。
假设有一条数据流程是这样的:
- 爬虫获取了某个股票价格为12.5元,股价的时间->2020-06-12 10:00:00
- 经过网络传输,Flink数据源收到这数据,当前系统时间->2020-06-12 10:00:10
- Flink执行计算最近1分钟内平均价格,当前系统时间->2020-06-12 10:00:20
上面有3个时间,它们分别是3种类型:
- 2020-06-12 10:00:00 -> 事件时间(Event Time)
- 2020-06-12 10:00:10 -> 摄入时间(Ingestion Time)
- 2020-06-12 10:00:20 -> 处理时间(Window Processing Time)
三种时间类型:
- 事件时间:每个事件在其生产设备上发生的时间,是事件的属性之一。
- 摄入时间:是事件进入Flink的时间。
- 处理时间:Flink处理事件记录时,当前的系统时间。
这里你对Flink时间的3种类型有了大概了解了吧,下面放张官网图方便理解。
2 Watermark(水位线)
数据产生时是有序的,但是考虑到网络延迟,它们到达Flink时,有可能时乱序的,先发生的事件延时到达。为了解决事件延时到达(或者说减少延时数据对计算结果的影响),有了watermark机制。
watermark有个参数允许延迟时间,举例:
窗口大小=10s,允许延迟时间=5s。
- 当事件时间>=10:08:08 00:00:10的事件到时,Flink不认为事件时间=[10:08:08 00:00:00, 10:08:08 00:00:10)事件都到了。
- 当事件时间>=10:08:08 00:00:15的事件到时,Flink会认为事件时间=[10:08:08 00:00:00, 10:08:08 00:00:10)事件都到了(虽然有可能还有数据没到,但是不等那些了)。
- 注意上面我用的左闭右开,但是根据Flink官网文档理解,10:08:08 00:00:10这个事件也到了。但是窗口计算左闭右开。
在Flink中,watermark是一种特殊的事件,它只包含时间戳,它被安插在数据流中。
如下图:
三角形的事件5到时,Flink不会认为<5的事件都到了,当到圆形watermark5时,才认为<5的事件都到了。
这时延时到达的事件3会被在窗口中计算,但是事件4迟迟没来,就不等了,事件4就被丢弃了。

五、结语
代码写的再多,不了解其背后的道理,也只能是代码的搬运工。就像搞JavaWeb开发好几年,@RestController、@Service、@Autowired这些Spring注解用的666,但是对Spring结构不理解,只能称为代码搬运工。
所以学一门技术,要先学会如何用,能够写点简单的案例,然后再学习其原理和架构,这样能反哺我们更好更深入地用它。