1. 字符串
1.1 创建和赋值
字符串或串是由数字、字母、下划线组成的一串字符。可以简单的通过在引号间(单引号、双引号、三引号)包含字符的方式创建它。
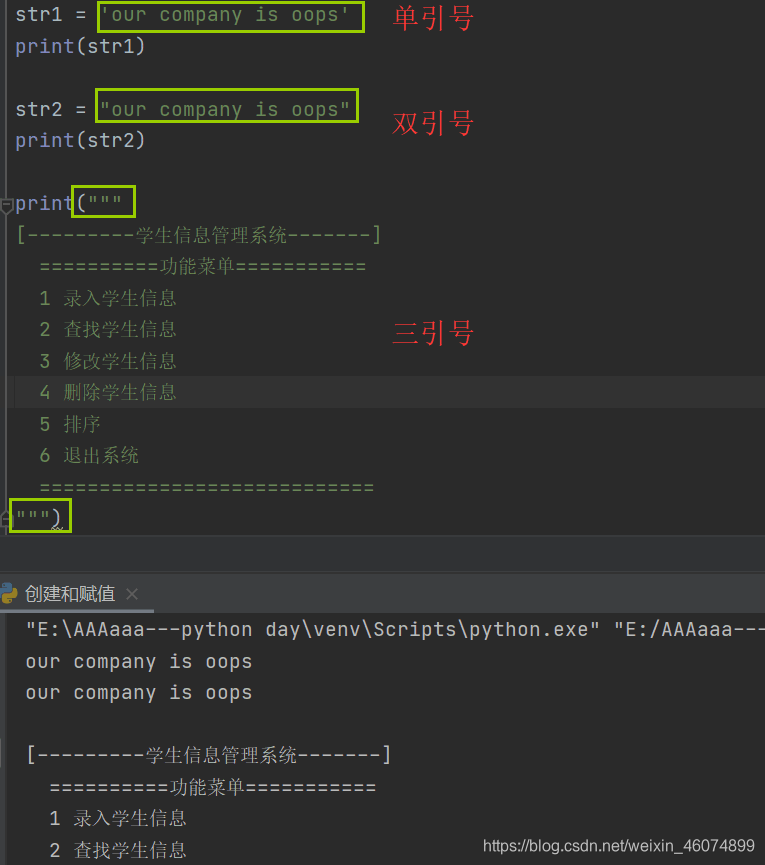
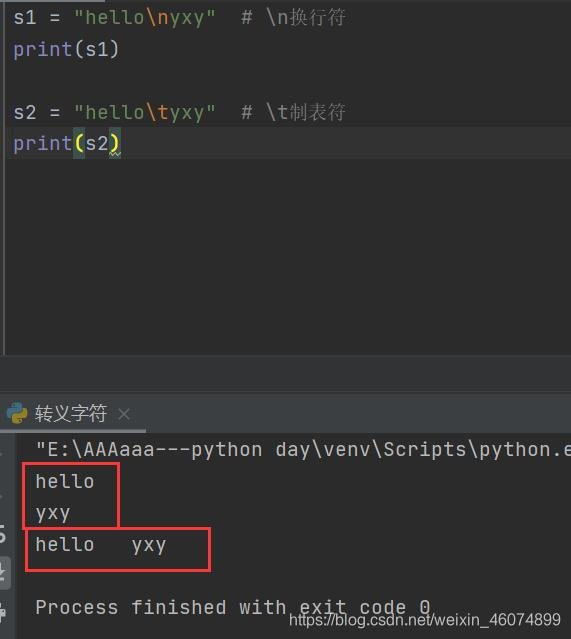
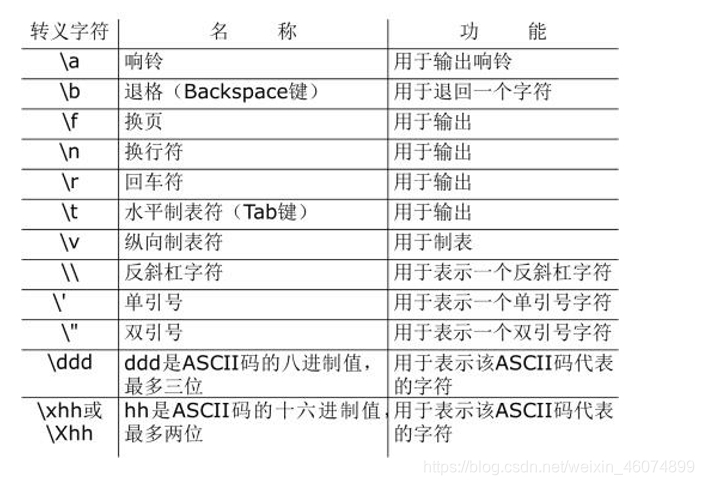
一个反斜线加一个单一字符可以表示一个特殊字符,通常是不可打印的字符。
1.2 字符串的基本特性
1.2.1 连接操作符和重复操作符
- 连接:+ 重复:*
name = 'yxy'
print('hello' + name)
print('*'*10)
结果:
helloyxy
**********
1.2.2 成员操作符
- 成员操作符:in
s = 'hello yxy'
print('yxy' in s)
print('yxy' not in s)
结果:
True
False
1.2.3 正向索引和反向索引
- 正向索引和反向索引
s = 'have a good time'
print(s[1]) #a
print(s[-4]) #t
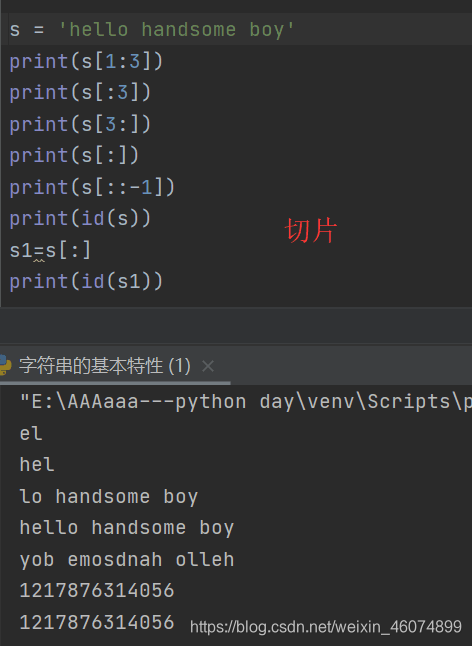
1.2.4 切片
- range:
range(3)
range(1,6,2)
- 切片:切除一部分的内容,从0开始
s[start:end:step]
s[:end]
s[start:]
- 切片总结:
s[:n] 拿出前n个元素
s[n:] 拿出后n个元素
s[:] 从开始到结尾,显示全部内容
s[::-1] 倒叙
1.2.5 可迭代对象/for循环
for循环访问:
s='mmwyj'
count=0
for item in s:
count+=1
print(f"第{count}个元素:{item}")
结果:
第1个元素:m
第2个元素:m
第3个元素:w
第4个元素:y
第5个元素:j
1.2.6 练习- - -回文字符串
用户输入一个字符串, 判断该字符串是否为回文字符串。
eg: "aba"是回文字符串, "abba"也是回文字符串。 "abc"不是回文字符串。
way1:
while True:
str1 = input("please input string:")
if str1[:] == str1[::-1] :
print(f"{str1}是回文字符串!")
else:
print(f"{str1}不是回文字符串!!")
way2:
s = input("please input string:")
result = "是回文字符串" if s == s[::-1] else "不是回文字符串"
print(s + result
1.3 字符串的内建方法
1.3.1 字符串的判断与转换
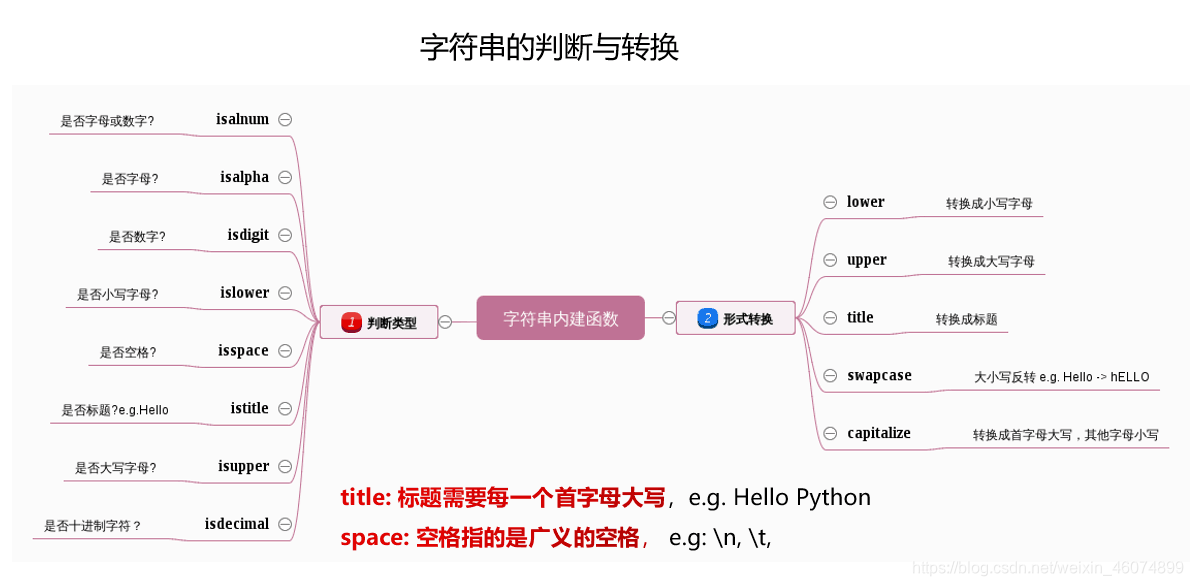
类型的判断:
s = 'hello mmyxy'
print(s.isalnum()) #False
print(s.isdigit()) #False
print(s.islower()) #True
类型的转换:
s='Hello'
print('Hello'.upper()) #HELLO
print('Hello'.lower()) #hello
print('Hello'.title()) #Hello
print('Hello'.capitalize()) #Hello
print('Hello'.swapcase()) #hELLO
需求:用户输入Y或者y都继续执行代码
chose = input("是否选择继续安装程序:Y/y表示同意:")
if chose.lower() == 'y':
print('正在安装程序!!~~~')
1.3.2 字符串的开头和结尾的匹配

# 1. startswith 以什么开头
url='http://www.baidu.com'
if url.startswith('http'):
print(f"{url}是一个正确的网址,可以爬取网站的代码")
else:
print(f"{url}不是一个正确的网址,不可以爬取网站代码哦")
http://www.baidu.com是一个正确的网址,可以爬取网站的代码
# 2. endswith 以什么结尾
# 常用场景:判断文件的类型
filename = 'hello.png'
if filename.endswith('.png'):
print(f"{filename}是一个图片")
elif filename.endswith('.mps'):
print(f"{filename}是一个音乐")
else:
print(f"{filename}是一个其他文件")
hello.png是一个图片
1.3.3 字符串的数据清洗
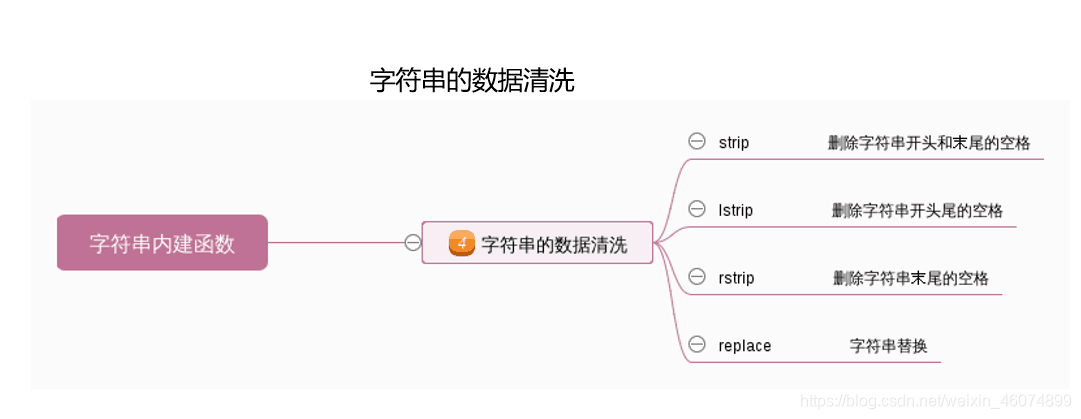
数据清洗的思路:
strip:删除开头结尾的空格,广义的空格如真实的空格‘ ’,\n \t 等也都删除
lstrip:删除左侧的空格,广义的空格如真实的空格‘ ’,\n \t 等也都删除
rstrip:删除右侧的空格,广义的空格如真实的空格‘ ’,\n \t 等也都删除
replace:替换
s=' hello mmyxy '
print(s.strip())
print(s.lstrip())
print(s.rstrip())
print(s.replace(' ','&'))
hello mmyxy
hello mmyxy
hello mmyxy
&hello&mmyxy&&
1.4 字符串的位置调整

print("学生管理系统".center(50))
print("学生管理系统".center(50,'*'))
print("学生管理系统".ljust(50,'*'))
print("学生管理系统".rjust(50,'-'))
#输出结果
学生管理系统
**********************学生管理系统**********************
学生管理系统********************************************
--------------------------------------------学生管理系统
1.5 字符串的搜索、统计

s = 'hello world'
# find如果找到子串,则返回字串的索引位置,否则返回-1
# index如果找到字串,则返回子串的索引位置,否则报错(抛出异常)
print(s.find('llo'))
print(s.find('xxx'))
print(s.index('he'))
print(s.count('l'))
print(s.count('xxx'))
print(s.find('l',1,3))
#print(s.index('xxx'))
输出结果:
2
-1
0
3
0
2
1.6 字符串的分离与拼接
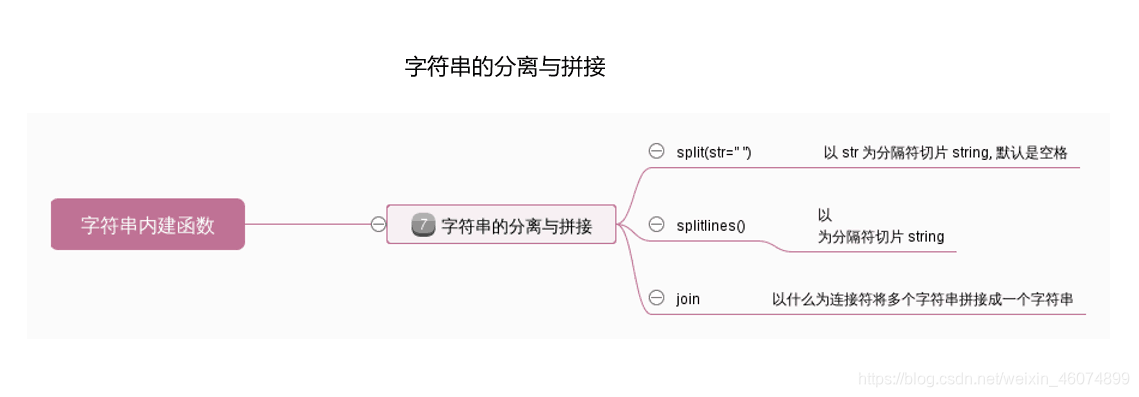
ip = '192.168.43.1'
item1 = ip.split('.') #分离
print(item1)
item2 = '-'.join(item1) #拼接
print(item2)
['192', '168', '43', '1']
192-168-43-1
1.7 string模块
# 需求:随机生成100个验证码
import random,string
for i in range(100):
print(''.join(random.sample(string.digits,2)) + ''.join(random.sample(string.ascii_letters,4)))
1.8 其他内置方法
s = 'hello world'
print(len(s)) 返回字符串的字符数
print(max(s)) 返回最大的字符,(按照 ASCII 码值排列)
print(min(s)) 返回最小的字符,(按照 ASCII 码值排列)
print(enumerate(s)) 枚举对象同时列出数据和数据下标
print(zip(s)) 将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表
1.9 小学生计算能力测试系统
设计一个程序,用来实现帮助小学生进行算术运算练习,它具有以下功能:提供基本算术运算(加减乘)的题目,每道题中的操作数是随机产生的,练习者根据显示的题目输入自己的答案,程序自动判断输入的答案是否正确并显示出相应的信息,最后显示正确率。
- 思路:
运行程序, 设定测试次数,输入测试数字的大小范围
任意键进入测试
系统进行测试并判断对错
系统根据得分情况进行总结,退出程序
import random
count = int(input("please input test count:"))
right_count=0
for i in range(count):
num1 = random.randint(1,10)
num2 = random.randint(1,10)
symbol = random.choice(["+","-","*","/"])
result = eval(f"{num1}{symbol}{num2}")
question = print(f"{num1}{symbol}{num2}=")
user_answer = int(input(f"答案为:"))
if user_answer == result:
right_count += 1
print("回答正确")
else:
print("回答错误")
print("right percent: %.2f"%(right_count/count*100))
结果:
please input test count:4
1/6=
答案为:1
回答错误
4*2=
答案为:8
回答正确
8-9=
答案为:-1
回答正确
10-5=
答案为:5
回答正确
right percent: 75.00
1.10 IPV4合法性判断
- 编写一个函数来验证输入的字符串是否是有效的 IPv4 ?
- IPv4 地址由十进制数和点来表示,每个地址包含4个十进制数,其范围为 0 - 255, 用(".")分割。
比如,172.16.253.1; - IPv4 地址内的数不会以 0 开头。比如,地址 172.16.254.01 是不合法的。
ip=str(input("请输入一个有效的IP地址:"))
ip_list=ip.split('.')#分隔
flag=True
#判断以'.'分隔并且分为四个参数
if ip.count('.')==3 and len(ip_list)==4:
#判断第一个是否在1-255之间的整数
if ip_list[0].isdigit() and int(ip_list[0]) <= 255 and int(ip_list[0]) >= 1:
#判断后三位的地址是否是0-255之间的整数
for i in range(1, 4):
if ip_list[i].isdigit() and int(ip_list[i]) <= 255 and int(ip_list[i]) >= 0:
flag=True
else:
flag=False
break
else:
flag=False
else:
flag=False
if flag==True:
print('IPv4!')
else:
print('Neither!')
1.11 机器人平面题
-
在二维平面上,有一个机器人从原点(0,0)开始,给出它移动顺序,判断这个机器人在完成移动后是否在(0,0)处结束
-
移动顺序由字符串表示,字符 move[i] 表示第 i 次移动。机器人的有效动作有 R(右)、L(左)、U(上)、D(下)。如果机器人在完成所有动作后返回原点,则返回true,否则false
-
注:机器人“面朝”的方向无关紧要。“R”始终使机器人向右移动一次,“L”始终是向左移动等。此外,假设每次移动机器人的移动幅度相同。
orientation = input("上(U),下(D),左(L),右(R) :")
U=D=R=L=1
for i in orientation:
if i == "U":
U+=1
elif i == "D":
D+=1
elif i == "R":
R+=1
elif i == "L":
L+=1
else:
print("请输入正确的方向!!")
print("True" if U==D and R==L else "False")
上(U),下(D),左(L),右(R) :UDRL
True
上(U),下(D),左(L),右(R) :DDU
False
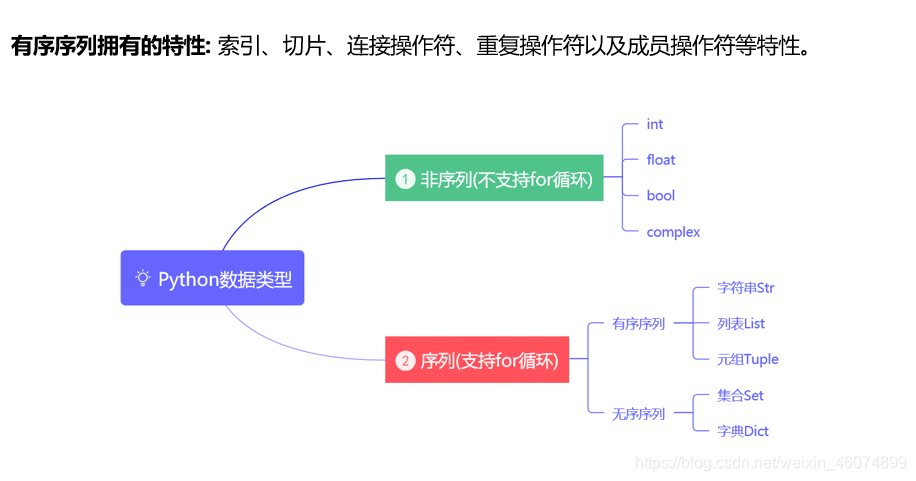
2. 序列
- 成员有序排列的,且可以通过下标偏移量访问到它的一个或者几个成员,这类类型统称为序列。
序列数据类型包括:字符串,列表,和元组类型。
特点: 都支持下面的特性
索引与切片操作符
成员关系操作符(in , not in)
连接操作符(+) & 重复操作符(*)
3. 数组、列表、元组
- 数组array:存储相同数据类型的数据结构。[1,2,3] [1.1,2.2]
- 列表list:打了激素的数组,可以存储不同数据类型的数据结构。[1,1.1,'hello']
- 元组tuple:带了紧箍咒的列表,和列表唯一区别就是不能增删改
3.1 列表
3.1.1 列表的创建
list = [1,2,1.2,'hello','nice to']
print(list)
结果:
[1, 2, 1.2, 'hello', 'nice to']
3.1.2 列表的基本特性
1.连接操作符和重复操作符
print([1,2]+[2,3])
print([1,2]*3)
结果:
[1, 2, 2, 3]
[1, 2, 1, 2, 1, 2]
2.成员操作符
print(1 in [1,2])
print(1 in ['a',True,[1,2]])
print(1 in ['a',False,[1,2]])
#bool类型:True=1 False=0
结果:
True
True
False
3.索引
list = [1,2,3,[1,'b',3]]
print(list[0])
print(list[-1])
print(list[-1][1]) #-1里面的1
print([3][-1])
结果:
1
[1, 'b', 3]
b
3
4.切片
list = ['172','23','12','5']
print(list[:2])
print(list[1:])
print(list[::-1])
print('-'.join(list[3:0:-1]))
print('-'.join(list[1:][::-1]))
结果:
['172', '23']
['23', '12', '5']
['5', '12', '23', '172']
5-12-23
5-12-23
5. for循环
names = ['1','2','3']
for name in names:
print(f"name{name}")
结果:
name1
name2
name3
3.1.3 列表的常用方法(增删改查)
1.增加
list = [1,2,3]
1.1 追加
list.append(4)
print(list) #[1, 2, 3, 4]
1.2 列表指定位置添加
list.insert(0,'cat')
print(list) #['cat', 1, 2, 3, 4]
list.insert(1,'dog')
print(list) #['cat', 'dog', 1, 2, 3, 4]
1.3 一次追加多个元素
list.extend([4,5,6])
print(list) #['cat', 'dog', 1, 2, 3, 4, 4, 5, 6]
2.修改
li = [1,2,3]
li[0] = 'cat'
print(li)
li[2] = 'dog'
print(li)
li[:2] = [1,1]
print(li)
结果:
['cat', 2, 3]
['cat', 2, 'dog']
[1, 1, 'dog']
3.查看 通过索引和切片查看元素,查看索引值和出现次数
li = [1,2,3,1,2,3,4,1]
print(li.count(1)) #3
print(li.index(4)) #6
4.删除
4.1 根据索引删除
li = [1,2,3]
delete_num = li.pop(-1)
print(li) #[1, 2]
4.2 根据value值删除
li = [1,2,3]
li.remove(3)
print(li) #[1, 2]
4.3 全部清空
li = [1,2,3]
li.clear()
print(li) #[]
其他操作
1.反转
li = [1,2,3,4]
li.reverse()
print(li) #[4, 3, 2, 1]
2.排序
sort排序默认由小到大,如果想由大到小排序,设置reverse=True
li.sort()
print(li) #[1, 2, 3, 4]
li.sort(reverse=True)
print(li) #[1, 2, 3, 4]
3.复制,id不同
li1=li.copy()
print(li,li1) #[4, 3, 2, 1] [4, 3, 2, 1]
print(id(li),id(li1)) #2239037465160 2239037465224
4.直接删除li列表
del li
3.2 元组
3.2.1 元组操作
0.元组简单示例
tuple1=(1,2.2,'cas',[1,2,3])
print(tuple1) #(1, 2.2, 'cas', [1, 2, 3])
1.元组的创建
t1 = () #空元组
print(t1,type(t1)) #() <class 'tuple'>
t2 = (1,) ##重点:元组单个元素一定要加逗号
print(t2,type(t2)) #(1,) <class 'tuple'
t3 = (1,1.1,True)
print(t3,type(t3)) #(1, 1.1, True) <class 'tuple'>
2.元组的特性
2.1连接操作符和重复操作符
print((1,2,3)+(4,)) #(1, 2, 3, 4)
print((1,2,3)*3) #(1, 2, 3, 1, 2, 3, 1, 2, 3)
2.2成员操作符
print(1 in (1,2,3)) #True
2.3切片
t = (1,2,3)
print(t[0]) #1
print(t[:]) #(1,2,3)
print(t[-1]) #3
print(t[::-1]) #(3,2,1)
print(t[:2]) #(1,2)
print(t[1:]) #(2,3)
3.常用方法
count和index,元组是不可变类型,不能增删改查
t = (1,2,3,4,1,1)
print(t.count(1)) #3
print(t.index(2)) #1
3.2.2 命名元组的操作
- Tuple还有一个兄弟,叫namedtuple。虽然都是tuple,但是功能更为强大。
collections.namedtuple(typename, field_names)
typename:类名称
field_names: 元组中元素的名称
tuple = ('yxy',18,'西安') #普通元组
命名元组解决了读代码的烦恼
from collections import namedtuple
1.创建命名元组对象User
User = namedtuple('User',('name','age','city'))
2.给命名元组传值
user1 = User('yxy',18,'西安')
3.打印命名元组
print(user1) #User(name='yxy', age=18, city='西安')
print(user1.name) #yxy
print(user1.age) #18
print(user1.city) #西安
3.3 地址引用、深拷贝和浅拷贝

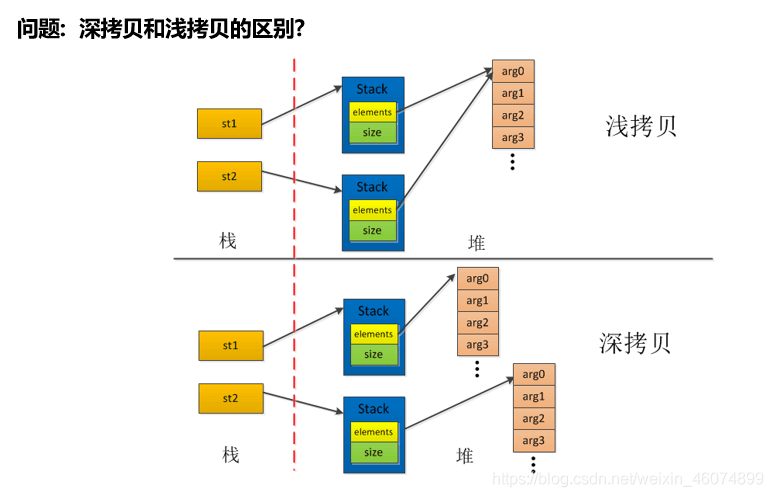
深拷贝和浅拷贝最根本的区别在于是否真正获取一个对象的复制实体,而不是引用。
假设B复制了A,修改A的时候,看B是否发生变化:
如果B跟着也变了,说明是浅拷贝,拿人手短!(修改堆内存中的同一个值)
如果B没有改变,说明是深拷贝,自食其力!(修改堆内存中的不同的值)
1.值的引用
赋值: 创建了对象的一个新的引用,修改其中任意一个变量都会影响到另一个。(=)
num1 = [1,2,3]
num2 = num1 #此时指向同一个内存空间
print(num2) #[1, 2, 3]
num1.append(4)
print(num1) #[1, 2, 3, 4]
print(num2) #[1, 2, 3, 4]
2.浅拷贝
n1 = [1,2,3]
n2 = n1.copy() ##n1.copy和ni[:]都可以实现拷贝
print(id(n1),id(n2)) ##copy指向不同的内存空间,所以互不影响
n1.append(4)
print(n1) ##相当于打印一份,然后在一份上做修改,不影响另一份
print(n2)
结果:
2813399097928 2813399097992
[1, 2, 3, 4]
[1, 2, 3]
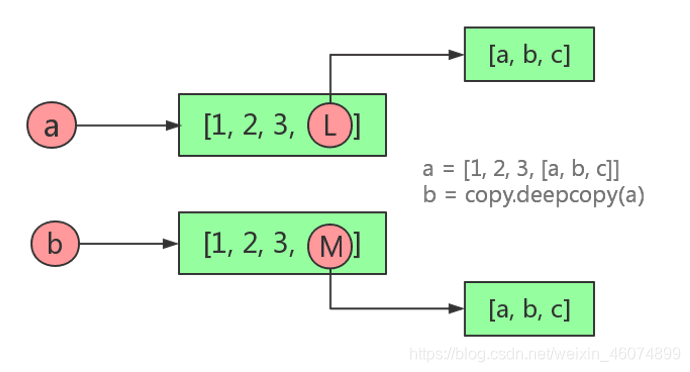
3.深拷贝
"""
如果列表的元素包含可变数据类型,一定要使用深拷贝
可变数据类型(可增删改的): list
不可变数据类型(变量指向的内存空间的值不会改变): str,tuple,nametuple
"""
n1 = [1,2,[1,2]]
n2 = n1.copy()
#查看n1和n2的内存地址,发现进行了拷贝
print(id(n1),id(n2)) #2640188957320 2640192640200
#n1[-1]和n2[-1]的内存地址
print(id(n1[-1]),id(n2[-1])) #2640188957256 2640188957256
n1[-1].append(4)
print(n1) #[1, 2, [1, 2, 4]] 修改成功
print(n2) #[1, 2, [1, 2, 4]],也随之改变
4. 如何实现深拷贝copy.deepcopy
"""
深拷贝: 一个变量对另外一个变量的值拷贝。(copy.deepcopy())
两个变量的内存地址不同;
两个变量各有自己的值,且互不影响;
对其任意一个变量的值的改变不会影响另外一个;
"""
import copy
n1 = [1,2,[1,2]]
n2 = copy.deepcopy(n1)
#查看n1和n2地址,发现进行了拷贝
print(id(n1),id(n2)) #2468787314632 2468787360264
#n1[-1]和n2[-1]的内存地址
print(id(n1[-1]),id(n2[-1])) #2468787204488 2468787360712
n1[-1].append(4)
print(n1) #[1, 2, [1, 2, 4]]修改成功
print(n2) #[1, 2, [1, 2]]
3.4 云主机操作练习
menu = """
云主机管理系统
1). 添加云主机
2). 搜索云主机(IP搜索)
3). 删除云主机
4). 云主机列表
5). 退出系统
请输入你的选择:"""
#思考1.所有的云主机信息如何存储?选择何种类型的数据类型存储?list
#思考2.每一个云主机(IP,hostname,IDC)应该如何存储?命名元组
from collections import namedtuple
hosts = []
Host = namedtuple('Host',('ip','hostname','IDC'))
while True:
choice = input(menu)
if choice =='1' :
print("添加云主机".center(50,'*'))
ip = input("ip:")
hostname = input("hostname:")
IDC = input("IDC:")
host1 = Host(ip,hostname,IDC)
hosts.append(host1)
print(f'添加{IDC}的云主机成功,ip地址为{ip}')
elif choice =='2' :
print("搜索云主机(IP搜索)".center(50, '*'))
#作业:for循环(for ...else),判断,break
for host in hosts:
ipv4 = input("please input ipv4:")
if ipv4 == host.ip:
print(f'{ipv4} 对应的主机为{host.hostname}')
else:
break
elif choice == '3':
print("删除云主机".center(50, '*'))
#作业:(选做)
for host in hosts:
delete_hostname = input("please input delete hostname:")
if delete_hostname == host.hostname:
hosts.remove(host)
print(f'对应的主机为{host.hostname}')
else:
break
elif choice == '4':
print("云主机列表".center(50, '*'))
print("IP\t\thostname\tIDC")
count = 0
for host in hosts:
count +=1
print(f'{host.ip}\t{host.hostname}\t{host.IDC}')
print('云主机总个数为', count)
elif choice == '5':
exit()
print("退出系统".center(50, '*'))
else:
print("请输入正确的选项")
4. 集合与字典
- 集合set:不重复且无序的(交集和并集)
- 字典dict:{
"name":"westos","age":10},键值对
4.1 集合
4.1.1 集合的操作
定义:
- 集合(set)是一个无序的不重复元素序列。1,2,3,4,1,2,3 = 1,2,3,4
集合的创建:
1). 使用大括号 {
} 或者 set() 函数创建集合;
2). 注意:
创建一个空集合必须用 set() 而不是 {
}
{
} 是用来创建一个空字典。
操作:
0.set集合简单操作
set1 = {
1,2,3,5}
set2 = {
2,3,4}
print("交集:",set1 & set2) #交集: {2, 3}
print("并集:",set1 | set2) #并集: {1, 2, 3, 4, 5}
1.集合的创建
s = {
1,2,3,1,2,3}
print(s,type(s)) #{1, 2, 3} <class 'set'>
注意:
· 集合的元素必须是不可变数据类型
s = {
1,2,[1,2]}
print(s,type(s)) TypeError: unhashable type: 'list'
· 空集合不能使用{
},而要使用set()
s = set()
print(s,type(s)) #set() <class 'set'>
2.集合的特性:不重复无序的
'''
不支持+ , * ,in ,index , slice(切片)
支持in 和 not in 成员操作符
'''
s = {
1,2,3,4}
print(1 in s) #True
3.集合的常用方法
3.1 增加:
s = {
1,2,3}
s.add(100) #add添加单个元素
print(s) #{1, 2, 3, 100}
s.update('456') #update添加多个元素
print(s) #{1, 2, 3, 100, '6', '4', '5'}
s.update({
4,5,6})
print(s) #{1, 2, 3, 100, 4, 5, '6', 6, '5', '4'}
3.2 删除:
'''
remove,如果元素存在删除,否则报错
discard,如果元素存在删除,否则不做任何操作
pop,随即删除一个元素,集合为空报错
'''
s = {
1,2,3}
s.remove(1)
print(s) #{2,3}
s.discard(2)
print(s) #{3}
s.discard(10)
print(s) #{3}
s = {
1,2,3,4}
s.pop()
print(s) #{2,3,4}
3.3 查看
差集s1-s2,交集s1&s2,对称差分s1^s2,并集s1|s2
s1 = {
1,2,3}
s2 = {
1,2}
print(s1-s2) #{3}
print(s1&s2) #{1, 2}
print(s1|s2) #{1, 2, 3}
对称差分(并集-交集)
s1 = {
1,2,3}
s2 = {
1,2,4}
print(s1^s2) #{3, 4}
子集
sa = {
1,2,3,4}
sb = {
1,2}
print(sb.issubset(sa)) #True b是a的子集嘛
print(sb.isdisjoint(sa)) #False 两者没有交集嘛
print(sa.issuperset(sb)) #True a是b的父集嘛
4. 排序
s = {
1,42,55,2,3,5,8,34}
sorted(s)
print(s)
5. 拓展:frozenset不可变集合
s = frozenset({
1,2,3})
print(s,type(s))
#frozenset({1, 2, 3}) <class 'frozenset'>
4.1.2 集合的练习

import random
N = int(input("please input people N:")) #生成N随机学号
s = set()
for i in range(N):
num = random.randint(1,1000)
s.add(num)
s = sorted(s,reverse=True) #必须重新赋值给s,不然排序不生效
print(s)
结果:
please input people N:3
[960, 638, 100]
4.2 字典
4.2.1 字典的操作
定义:
- 字典是另一种可变容器模型,且可存储任意类型对象。
键一般是唯一的,如果重复最后的一个键值对会替换前面的,值不需要唯一。
操作:
1.字典的创建dict
key-value对或键值对
dict1 = {
"name":"yxy","age":"21","city":"tc"}
print(dict1,type(dict1)) #{'name': 'yxy', 'age': '21', 'city': 'tc'} <class 'dict'>
print(dict1["name"]) #yxy
2.字典的特性:无序不重复
不支持+ , * ,in ,index , slice(切片)
支持in 和 not in 成员操作符(主要是判断key值)
dict1 = {
"name":"yxy","age":"21","city":"tc"}
print("name" in dict1) #True
print("xa" in dict1) #False
3.字典的常用方法
3.1查看
"""
查看所有: keys,values,items
查看局部: d[keys],d.get()
"""
操作:
dict1 = {
"name":"yxy","age":"21","city":"tc"}
print(dict1.keys()) #查看字典所有的key值
print(dict1.values()) #查看你字典所有的values值
print(dict1.items()) #查看字典的item元素
print(dict1['name']) #查看key-name对应的value值
#print(dict1['province']) #查看key不存在的会报错
print(dict1.get('provience')) #获取查看key对应的value值,如果存在则返回,不存在返回None。
print(dict1.get('province','shanxi')) #获取查看key对应的value值,如果存在则返回,不存在返回默认值shanxi 。
dict1 = {
"name":"yxy","age":"21","city":"tc","provience":"shanxi"}
print(dict1.get("provience"))
结果:
dict_keys(['name', 'age', 'city'])
dict_values(['yxy', '21', 'tc'])
dict_items([('name', 'yxy'), ('age', '21'), ('city', 'tc')])
yxy
None
shanxi
shanxi
3.字典的常用方法
3.2增加和修改
update添加多个元素
操作:
dict1 = {
"name":"yxy","age":"22"}
dict1["city"] = "西安" #key 不存在则添加
print(dict1)
dict1["city"] = "北京" #key 存在则修改
print(dict1)
dict2 = {
"name":"yxy","age":"11"}
dict2.setdefault("city","西安") #key不存在则添加
print(dict2)
dict2.setdefault("city","背景") #key存在则不做任何操作
print(dict2)
结果:
{
'name': 'yxy', 'age': '22', 'city': '西安'}
{
'name': 'yxy', 'age': '22', 'city': '北京'}
{
'name': 'yxy', 'age': '11', 'city': '西安'}
{
'name': 'yxy', 'age': '11', 'city': '西安'}
3.字典的常用方法
3.3 删除pop和del常用,popitem随机删除不常用
操作:
dict1 = {
"name":'yxy',"age":'10'}
dict1.pop("name")
print(dict1)
dict2 = {
"name":'yxy',"age":'10'}
del dict2["age"]
print(dict2)
结果:
{
'age': '10'}
{
'name': 'yxy'}
3.字典的常用方法
3.4遍历字典
操作:
dict1 = {
"name":'yxy',"age":"10","city":"xian"}
#默认情况下,指挥遍历key
for item in dict1:
print(dict1)
#如何遍历字典的key和value呢?重要!!
for item in dict1.items():
print(item)
for key,value in dict1.items():
print(f"key={key},value={value}")
结果:
{
'name': 'yxy', 'age': '10', 'city': 'xian'}
{
'name': 'yxy', 'age': '10', 'city': 'xian'}
{
'name': 'yxy', 'age': '10', 'city': 'xian'}
('name', 'yxy')
('age', '10')
('city', 'xian')
key=name,value=yxy
key=age,value=10
key=city,value=xian
4.2.2 默认字典
什么是默认字典?


from collections import defaultdict
d = defaultdict(int)
d["aaa"] += 1
d["ooo"] += 1
print(d)
d1 = defaultdict(list)
d1["allow_user"].append("yxy")
d1["deny_user"].append("gyh")
print(d1)
d2 = defaultdict(set)
d2["movies"].add("你好,李焕英")
d2["movies"].update({
"人潮汹涌"})
print(d2)
结果:
defaultdict(<class 'int'>, {
'aaa': 1, 'ooo': 1})
defaultdict(<class 'list'>, {
'allow_user': ['yxy'], 'deny_user': ['gyh']})
defaultdict(<class 'set'>, {
'movies': {
'你好,李焕英', '人潮汹涌'}})
4.2.3 字典的练习
技能需求:
1.文件操作
2.字符串的分割操作
3.字典操作
功能需求:词频统计
1.读取文件song.txt with open(song.txt) as f : content = f.read()
2.加载分析文件中的每一个单词,统计每个单词出现的次数,使用split分割
#先设定空字典{},统计次数一个一个往进加
song.txt文件内容
hello python
hello java
hello golong
hello sql
hello php
hello perl
hello ruby
hello k8s
k8s is good
k8s is best
方法1:
word = {
}
with open("./song.txt") as f:
content = f.read()
song = content.split(' ' or '\n')
print(song)
for item in song:
if item not in word:
word[item]=1
else:
word[item]+=1
print(word)
方法2:
with open("./song.txt") as f:
content = f.read().split()
result = {
}
for word in content:
if word in result:
result[word] += 1
else:
result[word] = 1
import pprint #自动换行小技巧,友好打印信息
pprint.pprint(result)
结果:
{
'best': 1,
'golong': 1,
'good': 1,
'hello': 8,
'is': 2,
'java': 1,
'k8s': 3,
'perl': 1,
'php': 1,
'python': 1,
'ruby': 1,
'sql': 1}
方法3:
with open("./song.txt") as f:
content = f.read().split()
from collections import Counter
counter = Counter(content) #统计个数Counter
print(counter)
result = counter.most_common(5) #统计出现次数最多的5个单词
print(result)
结果:
Counter({
'hello': 8, 'k8s': 3, 'is': 2, 'python': 1, 'java': 1, 'golong': 1, 'sql': 1, 'php': 1, 'perl': 1, 'ruby': 1, 'good': 1, 'best': 1})
[('hello', 8), ('k8s', 3), ('is', 2), ('python', 1), ('java', 1)]
5. 内置数据结构总结


6. 算法练习题
6.1 俩数之和
给定一个整数数组nums和一个整数目标值target,请你在该数组中找出和为目标值的那两个整数,并返回他们的数组下标。
你可以假设没中输入只会对应一个答案,但是, 数组中同一个元素不能使用两遍。
你可以按任意顺序返回答案。

方法1:
nums = [2,5,8,22,34]
n = len(nums)
target = int(input("please input target:"))
for i in range(n):
for j in range(i+1,n):
if nums[i] + nums[j] == target:
print(f"{i}和{j}")
结果:
please input target:7
0和1
方法2:不懂
时间复杂度为O(1),采用hash/字典办法
nums = [2,5,8,22,34]
n = len(nums)
target = int(input("please input target:"))
hashes = {
}
for i in range(n):
if target - nums[i] in hashes:
print(hashes[target - nums[i]],i)
hashes[nums[i]] = i
结果:
please input target:7
0 1
6.2 无重复字符串
