本次字体反扒实验的网站是起点中文网
GlidedSky字体反扒详解 建议先看完本章
1、网页查看




可见无论是小说文字数量还是推荐数,在我们本来页面中是好好的,可在网页源码中是一对我们看不懂的字体,这其实就是字体加密,所以我想做到字体反扒,就要破解字体加密,接下来我会为大家一一概述。
2、网页爬取代码
内容过于简单,不做过多概述
import requests
headers = {
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36"
}
url = "https://book.qidian.com/info/1018027842"
response = requests.get(url=url,headers=headers)
response.encoding = 'utf-8'
print(response.text)
将打印的粘贴到html中即可好好查看,当然,小伙伴们也可直接保存为html文件,可以自己尝试。
3、字体反扒研究
我们查看小说字数和推荐数都是乱码,查看源码可见样式style中加载了字体文件,这字体文件中包含着加密方法。

访问该链接,即可下载一个文件,这个文件其实就是字体文件,其中记录着一些映射关系
使用正则匹配字体文件url

#匹配字体文件下载地址
font_url = re.findall("; src: url\('(.*?)'\) format",response.text)[1]
print(font_url)

保存字体文件
#匹配字体文件下载地址
font_url = re.findall("; src: url\('(.*?)'\) format",response.text)[1]
font_res = requests.get(url=font_url,headers=headers)
with open("字体文件.woff",mode="wb") as f:
f.write(font_res.content)
保存成功,但是却无法查看,这时我们需要把字体文件进行转化,转化为我们能够阅读的格式
导入TTFont
from fontTools.ttLib import TTFont
font = TTFont('字体文件.woff')
font.saveXML("font.xml")


获取字体映射关系
#获取字体映射关系
font_cmap = font['cmap'].getBestCmap()
print(font_cmap)
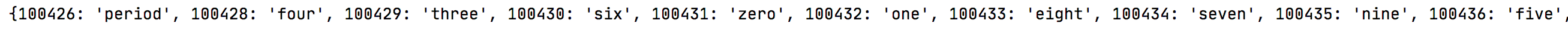
更改映射
f = {
'period':'.', 'four': 4, 'three': 3, 'six':6, 'zero': 0,
'one': 1, 'eight' : 8,'seven': 7,'nine': 9,'five' : 5, 'two': 2}
#更改映射
for key in font_cmap:
font_cmap[key] = f[font_cmap[key]]
print(font_cmap)
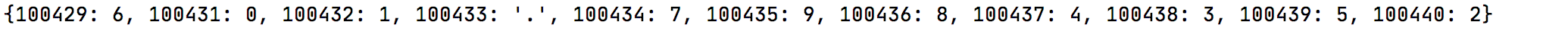
替换映射

#替换映射
for key in font_cmap:
html_data = html_data.replace('&#'+str(key)+';',str(font_cmap[key]))
with open("反扒成功.html","w",encoding="utf-8") as f:
f.write(html_data)



到这也算是反扒成功!希望大家都有所收获吧。
4、完整代码
import requests
import re
from fontTools.ttLib import TTFont
headers = {
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36"
}
url = "https://book.qidian.com/info/1018027842"
response = requests.get(url=url,headers=headers)
response.encoding = 'utf-8'
html_data = response.text
#匹配字体文件下载地址
font_url = re.findall("; src: url\('(.*?)'\) format",response.text)[1]
font_res = requests.get(url=font_url,headers=headers)
with open("字体文件.woff",mode="wb") as f:
f.write(font_res.content)
font = TTFont('字体文件.woff')
font.saveXML("font.xml")
#获取字体映射关系
font_cmap = font['cmap'].getBestCmap()
f = {
'period':'.', 'four': 4, 'three': 3, 'six':6, 'zero': 0,
'one': 1, 'eight' : 8,'seven': 7,'nine': 9,'five' : 5, 'two': 2}
#更改映射
for key in font_cmap:
font_cmap[key] = f[font_cmap[key]]
#替换映射
for key in font_cmap:
html_data = html_data.replace('&#'+str(key)+';',str(font_cmap[key]))
with open("反扒成功.html","w",encoding="utf-8") as f:
f.write(html_data)
博主会持续更新,有兴趣的小伙伴可以点赞、关注和收藏下哦,你们的支持就是我创作最大的动力!
本文爬虫源码已由 GitHub https://github.com/2335119327/PythonSpider 已经收录(内涵更多本博文没有的爬虫,有兴趣的小伙伴可以看看),之后会持续更新,欢迎Star。