点赞、收藏后可私信我领取完整得Python学习思维导图^ ^
目录
- 一、Python简介
- 二、环境搭建
- 三、正式进入Python
-
- 1.语句块规范
- 2.注释方法
- 3.常见的内置函数
- 4.变量
- 5.数值类型
- 6.数值类型操作符
- 7.列表(List)
- 8.元组(Tuple)
- 9 .列表/元组操作
- 10.range类型
- 11.列表、元组、range转换
- 12.pack与unpack
- 13.常见的序列操作
- 14.Set(集合)
- 15.集合操作
- 16.字典(Dict)
- 17.字符串
- 17.None和布尔值
- 18.比较运算符
- 19.流程控制语句
- 20.三元表达式
- 21.列表生成式
- 21.自定义函数
- 22.函数参数
- 23.Python中函数是对象
- 24.嵌套函数
- 25.装饰器
- 26.变量作用域
- 27.LEGB规则
- 28.函数的返回值
- 29.yield关键字
- 31.lambda匿名函数
- 32.正则表达式
一、Python简介
Python 是一种解释型、面向对象、动态数据类型的高级程序设计语言。
Python 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。
Python 的设计具有很强的可读性,相比其他语言经常使用英文关键字,其他语言的一些标点符号,它具有比其他语言更有特
- Python 是一种解释型语言:这意味着开发过程中没有了编译这个环节。
类似于 PHP 和 Perl 语言。 - Python 是交互式语言:这意味着,你可以在一个 Python 提示符 >>> 后
直接执行代码。 - Python 是面向对象语言: 这意味着 Python 支持面向对象的风格或代码
封装在对象的编程技术
二、环境搭建
Python 环境安装可以采用单独安装 Python 解释器和需要使用的库或者选择某一集成发行版安装工具安装。单独安装的好处安装的速度快,占的空间小。但是问题就是 Python 的版本众多,不同版本的库之间会出现兼容性问题。一般在使用 Python 开发网站应用时会使用这种安装方式。
在数据科学领域,普遍采用 Anaconda 来安装 Python 开发环境。Anaconda 集成了很多数据分析常用的库及软件,如 NumPy、Pandas、Matplotlib 和JupyterNoteBook 等。
Anaconda 在 Linux 和 Windows 上都可以安装。
如果使用 Anaconda 安装 Python,最好先卸载当前操作系统中的其他 Python环境,清除环境变量相关设置。经常出现的一种情况是之前学生因为各种原因在电脑上安装过其他版本的 Python,然后再安装 Anaconda,导致使用时出现各种版本问题,非常难于解决。所以如果 Python 环境出现问题,首先考虑之前这台电脑上是不是安装过 Python
安装Anaconda3
下载地址:官网下载
如果操作系统是 Win10 系统,请右键点击安装文件,选择以“管理员身份运行”(之前出现过在 Win10 上,未使用管理员权限安装导致后面 Scrapy 爬虫安装失败的情况)






下一步,点击 Skip,不安装 VSCode。我们使用 PyCharm 作为开发工具

等待安装完成即可
- 验证安装是否成功
按win+R输入cmd进入命令行

输入python回车即可看到一下信息

然后就可以在这里运行程序

使用Jupyter NoteBook
Jupyter Notebook 是以网页的形式打开,可以在网页页面中直接编写代码和运行代码,代码的运行结果也会直接在代码块下显示。如在编程过程中需要编写说明文档,可在同一个页面中直接编写,便于作及时的说明和解释。
Jupyter NoteBook 在数据分析领域使用十分广泛,但使用 Jupyter NoteBook在程序出异常和 Debug 代码上不是很方便。在课程中,经常需要代码结合输出结果进行分析调整的情况下可以使用 Jupyter NoteBook。如 PySpark 开发就可以采用 Jupyter NoteBook。
Jupyter NoteBook 修改默认路径方式:
- 找到安装好Anaconde后的位置,可以到就有Jupyter NoteBook

- 右击属性,查看起始位置

- 到达该位置并找到.jupyter文件夹
如果没有这个文件夹就在windows命令框输入下面这句执行,然后再去看看该文件是否存在
jupyter notebook --generate-config

- 进去找到一个名为jupyter_notebook_config.py的文件

- 右击编辑(这里推荐使用Notepad++打开),找到notebook_dir的配置项,指定默认路径

- 保存退出
运行Jupyter NoteBook
- 右击以管理员运行Anaconde,然后点击左侧的Environments,然后点击baes(root),然后选择第一个

- 此时出现黑界面,输入jupyter notebook

- 然后会自动跳出一个界面,就是jupyter notebook的操作界面、

- 创建文件

- 然后就可以编写/运行Python代码

设置自动补齐
-
依然是右击以管理员运行Anaconde,然后点击左侧的Environments,然后点击baes(root),然后选择第一个
-
在windows命令框下依次运行以下几条命令
pip install jupyter_contrib_nbextensions
jupyter contrib nbextension install --user
pip install jupyter_nbextensions_configurator
jupyter nbextensions_configurator enable --user

- 然后重新进入jupython notebook中,点击Nbextensions页,勾选在Hinterland

- 测试,出现提示内容表示操作成功

PyCharm
PyCharm 是基于 IDEA 开发的 Python 集成开发环境,适用于工程类代码的开发比如 Web 应用或爬虫应用。PyCharm 安装很容易,但是使用时要注意设置工程使用哪个 Python 解释器
- 创建工程的时候需要选择解释器

三、正式进入Python
1.语句块规范
缩进
- Python中要求强制缩进以区分层次和代码块
- 缩进可以使用2个空格、4个空格、1个tab键实现
- 推荐只使4个空格进行缩进
因缩进方式不同会引起编译错误提示
需要手动修改统一缩进方式 - PyCharm默认设置不使用“TAB缩进符”,而是设置一个TAB=4个空格
2.注释方法
- 单行注释:使用“#”进行注释
- 多行注释:使用三个单引号或三个双引号进行注释、
3.常见的内置函数

4.变量
命名原则
- 以_或字母开头
- 变量名以_、数字、字母组成
- 变量名大小写敏感
- 不能使用Python保留的关键字
查看Python关键字的方法

变量的特点 - 使用变量前不需要声明
- 变量的类型不固定
- Python变量是实际值的引用:id(var)判断两个变量是否引用了同一个值
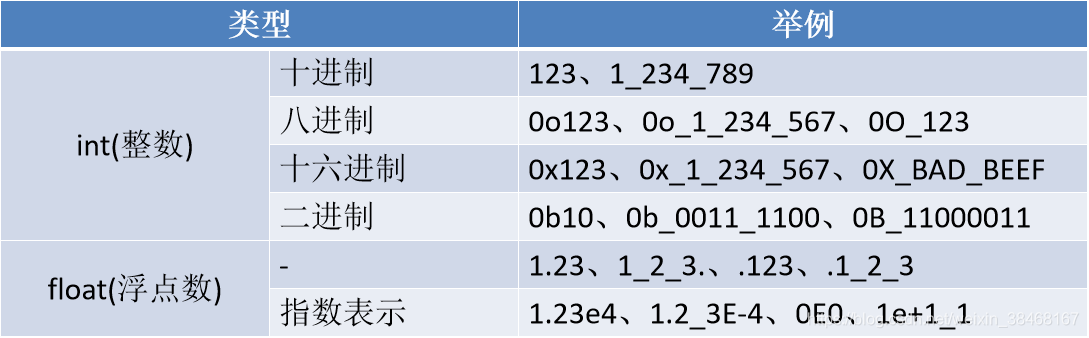
5.数值类型
6.数值类型操作符
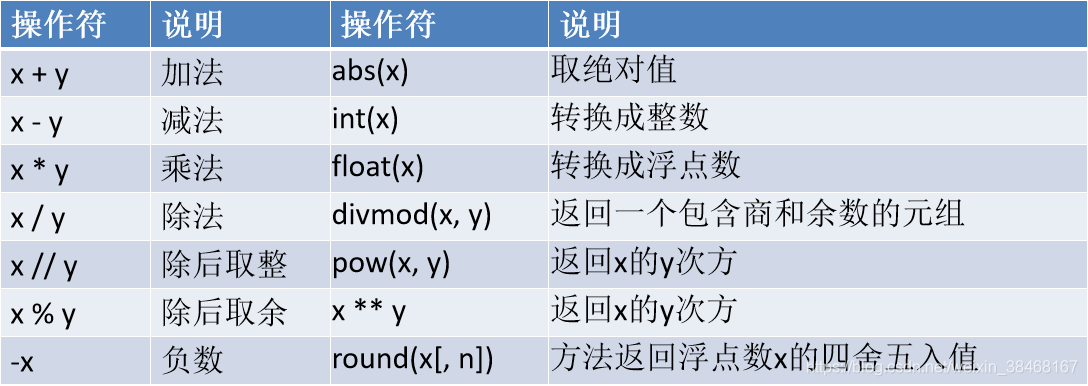
7.列表(List)
特点
- 用来储存多个数据的数据结构
- 储存的数据是有序的,可使用位置索引
- 列表长度和元素都是可变的
- 可储存不同类型的数据
使用方法
- 创建列表
['one', 2, [3, 4], (5, 6)]
- 使用索引获取列表中的数据
x[0], x[2], x[-1], x[-3]
- 判断值是否存在于列表中
in 和 not in

8.元组(Tuple)
特点
- 储存形式与列表相似
- 与列表不同的地方
元素不可修改
长度不可改变 - 常用于安全级别较高的场景应用
使用方法
- 创建元组
t1=(1, 2, 3, 4, 5)
t2='one', 2, [3, 4], (5, 6)
t3=tuple([1,2,3])
- 使用索引获取元组中的数据
x[0], x[2], x[-1], x[-3]
- 判断值是否存在于元组中
in 和 not in
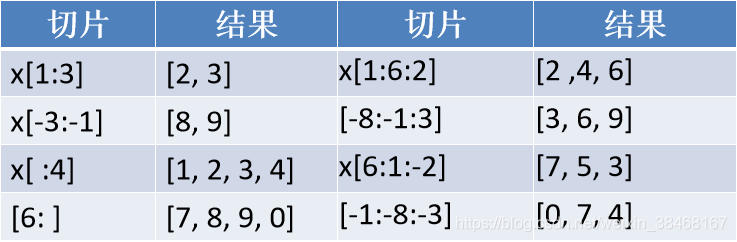
9 .列表/元组操作
通过切片获得新的列表/元组
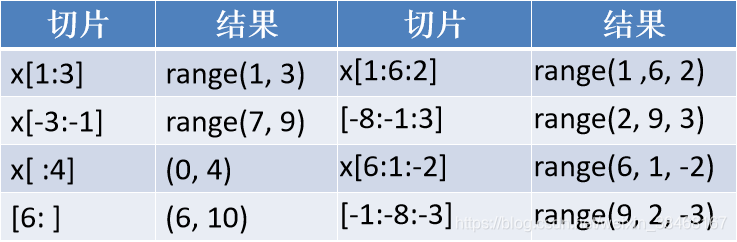
- 格式:[start: end :step]
start:起始索引,从0开始,-1表示结束
end:结束索引
step:步长,end-start,步长为正时,从左向右取值。步长为负时,反向取值
示例
- 对列表x = [1, 2, 3, 4, 5, 6, 7, 8, 9, 0]切片
遍历列表/元组中的元素
#x为集合或元组
for v in x:
print(v)
zip()函数
- 将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象
//示例一
matrix = [[1, 2, 3, 4],[5, 6, 7, 8],[9, 10, 11]]
list(zip(*matrix)) # result: [(1, 5, 9), (2, 6, 10), (3, 7, 11)]
//示例二
t = (1,2,3,4)
list(zip(t))
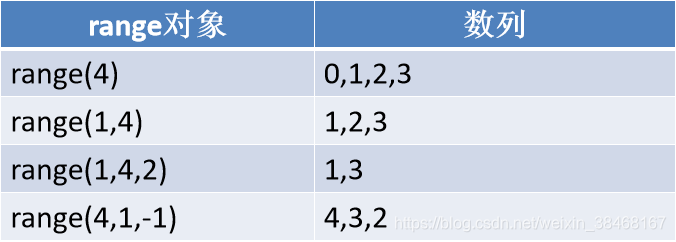
10.range类型
- 一段不可变的数字序列
- 经常被用作for里面来指定循环次数
创建range对象
- range(start, stop, step)
start的默认值是0,step的默认值是1
示例
range操作方法
- range类型也支持切片:测试 x=range(10)
使用for循环遍历range()
for v in range(10):
print(v)
#输出 0,1,2,3,4,5,6,7,8,9
11.列表、元组、range转换
- 列表转元组
t = tuple(l)# l是列表
- 元组转列表
l = list(t)# t是元组
- range转列表
l = list(r)# r是range
- range转tuple
t = tuple(r)# r是range
12.pack与unpack
pack
- 变量转换成序列
t = 1,2,3 #t是(1,2,3)
unpack
- 序列转换成变量
a,b,c=t #a=1,b=2,c=3
unpack中使用*
a, b, *c = 1,2,3,4,5 # a=1, b=2, c=[3, 4, 5]
a, *b, c = 1,2,3,4,5 # a=1, b=[2, 3, 4], c=5
*a, b, c = 1,2,3,4,5 # a=[1, 2, 3], b=4, c=5
*a, b, c, d, e, f = 1,2,3,4,5 # a=[], b=1, c=2, d=3, e=4, f=5
交换两个变量的值
a, b = b, a
在for循环中unpack元组
l = [(1,2), (3,4), (5,6)]
result=0
for x, y in l:
result += x*y
print(result)
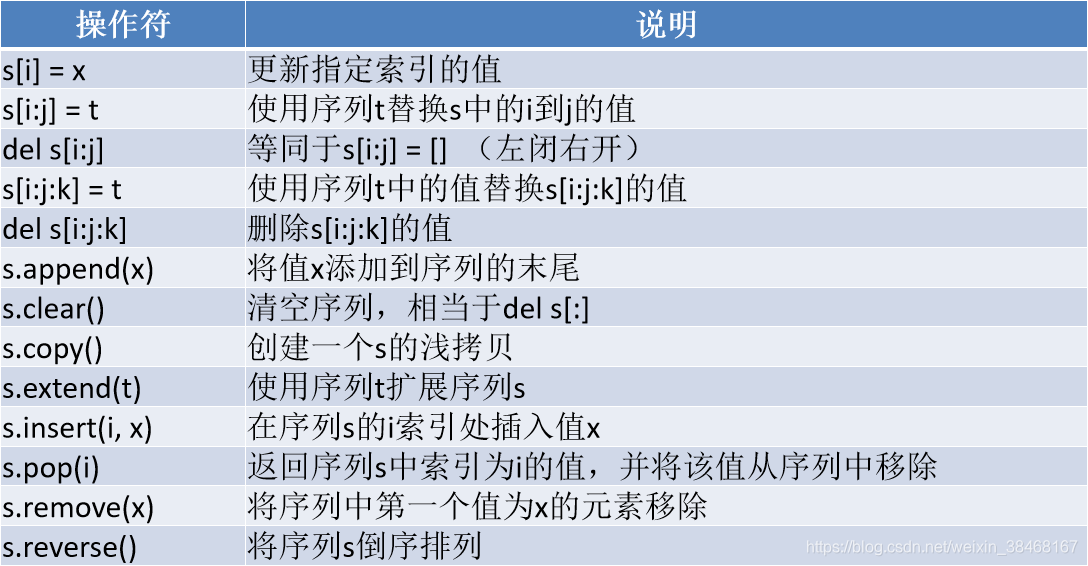
13.常见的序列操作
- 测试:s = [1,2,3] t = [4,5,6] n = 2
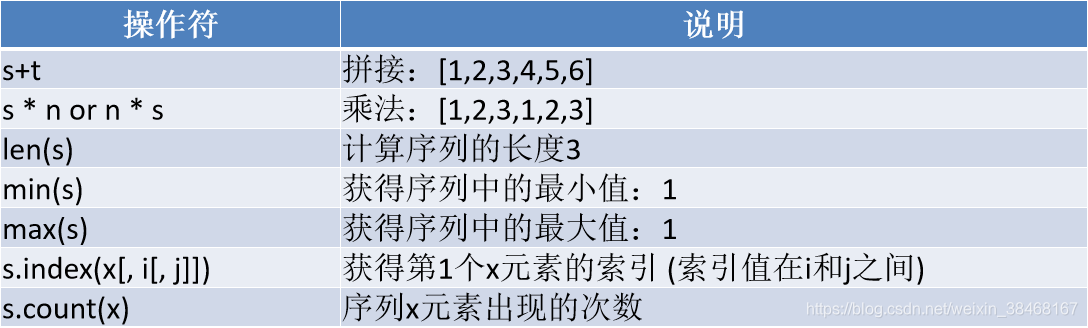
可变序列支持的操作
14.Set(集合)
储存形式与列表相似
- 集合中保存的数据具有唯一性,不可重复
- 集合中保存的数据是无序的
- 往集合中添加重复数据,集合将只保留一个
set集合常被用来去重或者过滤
创建一个集合
- 空集合:
变量=set()
- 非空集合:
变量={
元素1,元素2,…}
集合操作
- 判断值是否存在于集合中
in 和 not in
15.集合操作
- 集合的并集
#方式一
newSet = s1 | s2 | s3
#方式二
newSet = s1.union(s2, s3)
- 集合的交集
#方式一
newSet = s1 & s2 & s3
#方式二
newSet = s1.intersection(s2, s3)
- 集合的差集
#方式一
newSet = s1 - s2 - s3
#方式二
newSet = s1.difference(s2, s3)
- 判断是否是超集
s1.issuperset(s2)
- 判断是否是子集
s2.issubset(s1)
- 判断两个集合是否相交
s1.isdisjoint(s2)
- 集合的遍历与列表的遍历方法相同
16.字典(Dict)
- 通过键值对(key-value)来储存数据
- 储存的数据是无序的,可使用键索引
- 键是必须唯一,但值可以不唯一
- 键的类型只能是字符串、数字或元组,值可以是任何
- 字典操作
#创建字典
dict_1 = {
1:'one', 2:'two', 3:'three'}
#获取字典值
dict_2 = dict(one=1, two=2, three=3)
#遍历dict_2
for i in dict_2:
print(i)
#输出结果
one
two
three
字典操作
- 获取字典中的值
x = d[1] #1是Key,不是索引
x = d['three']
x = d.get(3, 'This value when key is not found') #还可设置未找到时输出的内容
- 判断值是否是字典的键
in 和 not in
- 遍历字典
#遍历字典的键
for k in x: #x.keys()
print(k)
#遍历字典的值
for v in x.values():
print(v)
#遍历字典的键和值
for k,v in x.items():
print(k,v)
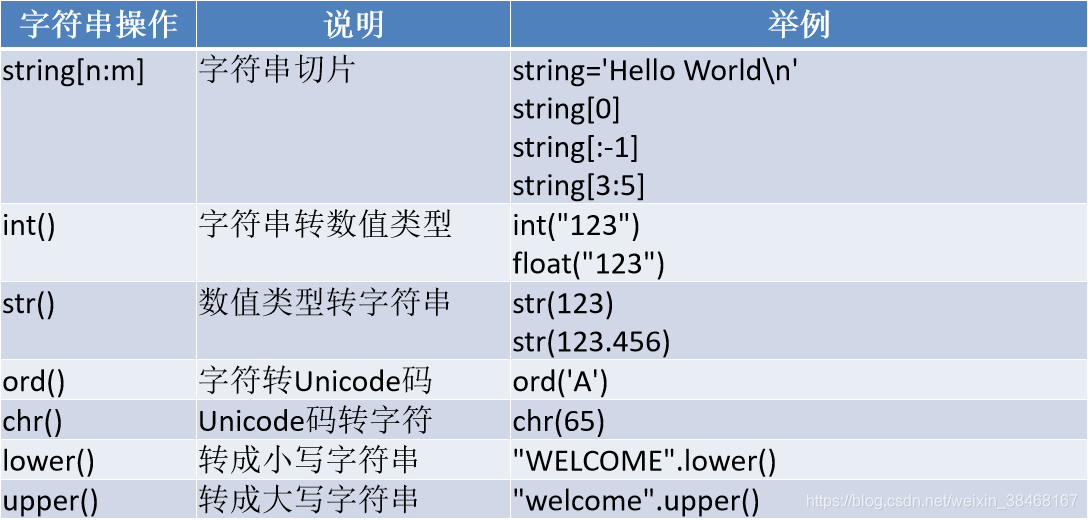
17.字符串
Python定义字符串的三种形式
- 单引号
#单引号
str1 = 'allows embedded "double" quotes'
- 双引号
#双引号
str2 = "allows embedded 'single' quotes"
- 三引号(允许字符串换行)
#三引号
str3= '''Three single quotes,
span multiple lines'''
str4="""Three double quotes,
span multiple lines"""
字符串操作


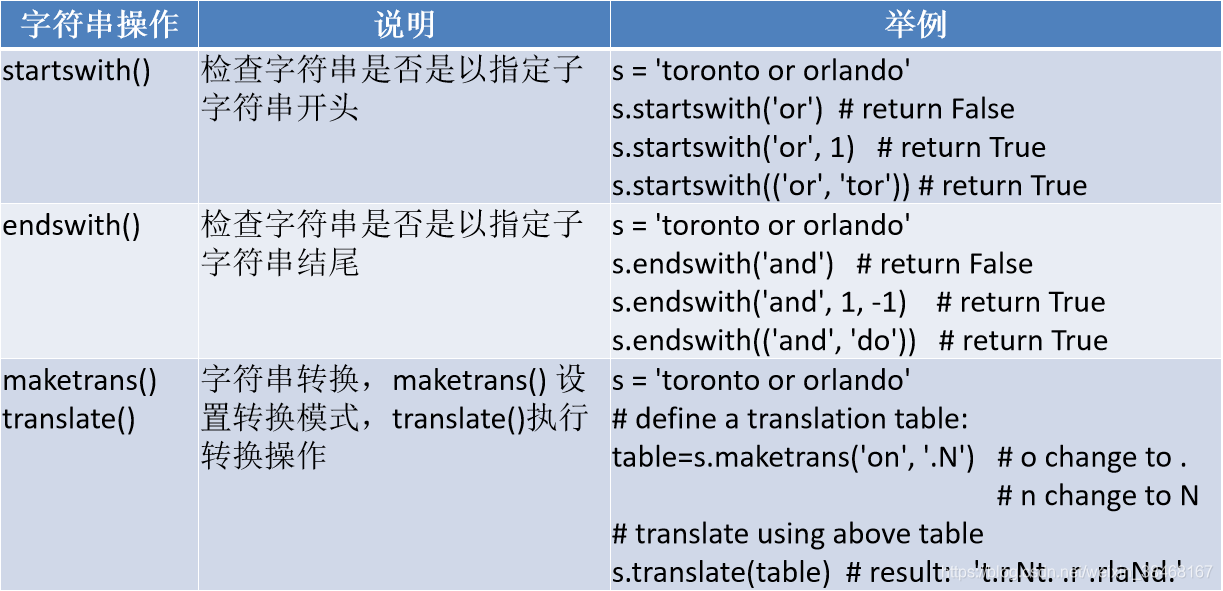
17.None和布尔值
None
- 是一个特殊的常量,表示空值
Python中很多类型可以表示布尔值
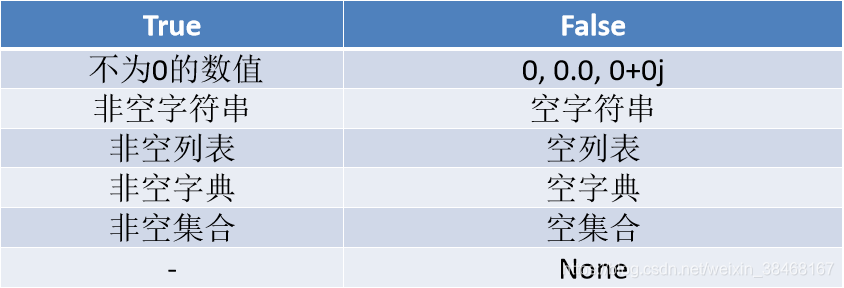
布尔操作符
- or、and、not
18.比较运算符
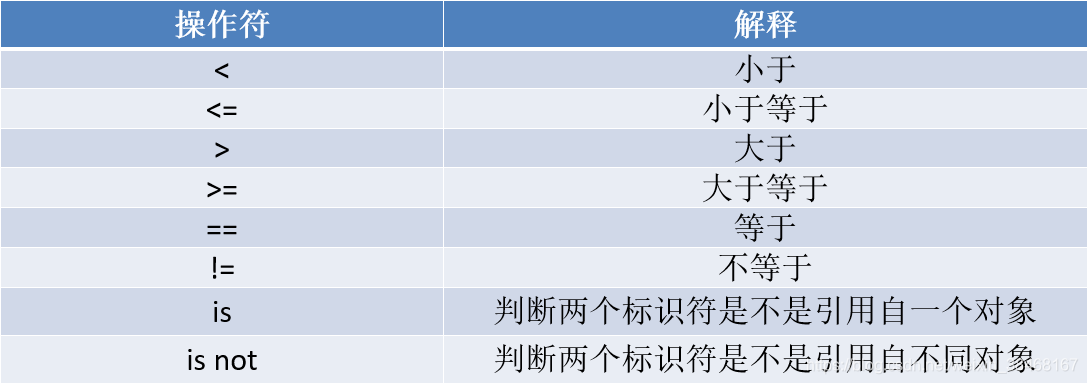
19.流程控制语句
条件选择语句
if guess > secret :
print("too large")
elif guess < secret : # elif is optional
print("too small")
else : # else is optional
print("equals")
循环语句
- where循环
#where循环
while guessed != secret :
guessed = int(input("Guess a number: "))
else : # else is optional
print("Congratulation!")
- for循环
#for循环
for i in range(0, 8, 2) :
print(i)
else : # else is optional
print("Done!")
break
- break语句在循环中的作用是跳出当前循环语句
- 循环语句的else子句不会被执行
continue
- continue语句在循环中的作用是跳出本次循环
- 遇到了continue将跳过本次循环的剩余代码,直接开始下一次循环
pass
- 占位语句
20.三元表达式
- 效果等同于一个if…else语句
result=值1 if x<y else 值2
示例
#单层判断
'even' if x%2==0 else 'odd'
#多层判断
'A' if x%2==0 else 'B' if x%5==0 else 'C'
21.列表生成式
- 用列表生成式创建列表
- 列表生成式
可以生成list列表的表达式

列表生成式举例

字典生成式 - {k:v for k,v in input if xxxx }
#将所有的key值变为大写
d = dict(a=1,b=2)
print({
k.upper():v for k,v in d.items()})
#大小写key值合并, 统一以小写key值输出;
d = dict(a=2, b=1, c=2, B=9, A=5)
print({
k.lower():d.get(k.lower(),0)+d.get(k.upper(),0) for k in d})
集合生成式
- {v for v in input if xxxx}
#筛选字符串中的字母
{
x for x in 'abracadabra' if x not in 'abc'}
21.自定义函数
- 定义方式
def func_name(参数列表):
函数体
[return/yield 函数返回值]
Python函数特点
- 函数参数类型多样
- 允许嵌套函数
- 无需声明函数返回值类型
- yield可以作为函数返回值的关键字
- 函数能够被赋值给变量
22.函数参数
Python的函数参数
- 无参函数
- 位置参数
- 关键字参数
- 包裹位置参数
- 包裹关键字参数
无参函数
#定义函数
def show_log():
print('I am a log')
#直接使用
show_log()
位置参数
- 传入的参数与定义的参数一一对应
#定义函数,并需要传入三个参数
def func_name(arg1,arg2,arg3):
print(arg1,arg2,arg3)
#调用函数,传入的参数会根据位置一一对应
func_name(val1,val2,val3)
关键字参数
- 直接通过等号传递参数
#定义函数,并需要传入三个参数
def func_name(arg1,arg2,arg3):
print(arg1,arg2,arg3)
#调用函数,传入的参数值时指定对应参数名,此时顺序可以忽略
func_name(arg1=val1,arg3=val3,arg2=val2)
默认值参数
- 定义函数时,设置参数的默认值
- 调用函数时,可以指定通过位置或者关键字指定参数的值,如果不指定,参数为默认值
#定义函数,并为参数设置默认值
def func_name(arg1=10,arg2=20,arg3=30) :
print(arg1,arg2,arg3)
#调用函数,不传入参数
func_name()
#输出
10 20 30
#错误示例
#使用默认值参数就需要为所有参数设置默认值
def func1(x=10, y) : # <= ERROR!
...
不定长参数
- 参数的个数不确定
- 可适应更加复杂情况
- 不定长参数种类
包裹(packing)位置参数
接收不定长的位置参数,参数被组织成一个元组传入
包裹(packing)关键字参数
接收不定长的关键字参数,参数被组织成一个字典传入
示例:包裹(packing)位置参数
#参数表示为*args
#调用函数时,参数自动会组织成一个元组传入
#传入的位置参数与组织成的元组索引位置一致
#定义函数,并指定参数为一个元组
def func2( *t ) : # t is a tuple
print(t)
#调用函数
func2() # no argument
func2(1,2,3)
func2(1,2,3,4,5)
示例:包裹(packing)关键字参数
#参数表示为**kwargs
#调用函数时,参数自动会组织成一个字典传入
#传入的位置参数与组织成的字典的键值对一致
#定义函数,并将传入的参数组成成一个字典
def func3( **d ) : # d is a dictionary
print(d)
#调用函数
func3() # no argument
func3(a=1, b=2, c=3)
不同类型函数参数混用顺序
- 位置参数
- 默认值参数
- 包裹位置参数
- 包裹关键字参数
#定义函数,指定多种类型的参数
def func5(x, y=10, *args, **kwargs) :
print(x, y, args, kwargs)
#调用函数
func5(0) #输出 0 10 () {}
func5(a=1, b=2, y=3, x=4) #输出 4 3 () {'a': 1, 'b': 2}
func5(1, 2, 3, 4, a=5, b=6) #输出 1 2 (3, 4) {'a': 5, 'b': 6}
23.Python中函数是对象
- 函数可以被引用,即函数可以赋值给一个变量
- 函数可以当做参数传递
- 函数可以作返回值
- 函数可以嵌套
#定义函数
def factorial(n):
if n <= 2: return n
return factorial(n-1)*n
#将函数传递给一个变量
f=factorial
#此时变量可以认为就是函数
f(4)
#将函数做为集合中的元素
l=[factorial, f]
#调用集合中的函数
l[0](4)
l[1](4)
#将函数做为字典的值
d={
'x':factorial}
#调用字典中的函数
d['x'](4)
24.嵌套函数
- 在函数内部定义新的函数
- 内部函数不能被外部直接调用
- 函数可以被当做变量赋值,因为本质函数是一个对象
#定义函数
def func6() :
#定义嵌套函数
def nestedFunc() :
print('Hi')
return nestedFunc
#调用func6函数,返回的时nestedFunc函数
x = func6() # x is the nestedFunc
#此时调用x对象内的函数,即nestedFunc函数
x()
25.装饰器
- 修改其他函数的功能的函数
- 使函数更加简洁
#定义函数
def my_decorator(some_func):
def wrapper(*args):
print("I am watching you!")
some_func(*args)
print("You are called.")
return wrapper
#使用装饰器
@my_decorator
def add(x, y):
print(x,'+',y,'=',x+y)
#调用函数
add(5,6) #相当于my_decorator(add(5,6))
#输出结果
I am watching you!
5 + 6 = 11
You are called.
26.变量作用域
全局变量
- 定义在模块中的变量
- 全局变量在整个模块中可见
- globals()函数,返回所有定义在该模块中的全局变量
- 修改全局变量时,要先使用global关键字声明变量
#定义全局变量
msg = 'created in module'
#定义函数
def outer() :
#定义嵌套函数,修改全局变量
def inner() :
#修改全局变量
global msg
msg = 'changed in inner'
#调用嵌套函数
inner()
#调用函数
outer()
#输出全局变量
print(msg)
#输出结果:
changed in inner
局部变量
- 定义在函数中的变量
- 局部变量仅在定义的函数中可见
- locals()函数:返回所有定义在函数中的局部变量
- 自由变量:在函数中使用,但未定义在该函数中的非全局变量
#定义函数
def outer_1() :
#定义局部变量
msg = 'created in outer'
def inner() :
#此时msg为自由变量
print(msg) # msg is a Free variable
inner()
#调用函数
outer_1()
- 修改自由变量时,要先使用nonlocal关键字声明变量
#定义函数
def outer():
#定义局部变量
msg = 'created in outer'
#定义嵌套函数
def inner() :
#修改自由变量
nonlocal msg
msg = 'changed in inner' # msg is a Free variable
inner()
#输出局部变量
print(msg)
#调用函数
outer()
27.LEGB规则
-
使用 LEGB 的顺序来查找一个变量对应的对象
Local -> Enclosed -> Global -> Built-in -
Local:一个函数或者类方法内部
-
Enclosed:嵌套函数内
-
Global:模块层级
-
Built-in:Python内置符号
type=4
def f1():
type=3
def f2():
type=2
def f3():
type=1
#输出type变量值,优先使用内部对象
print('type=', type)
f3()
f2()
f1()
28.函数的返回值
- 函数无需声明返回值类型
- 在函数没有返回值时,函数默认返回None
- return关键字用于返回返回值
29.yield关键字
当函数使用yield关键字时,函数变为生成器
- 生成器是Python中的一种可迭代对象
- 能够使用for循环遍历
- 生成器每次只被读取一次
- 生成器有内置方法__next()__,调用后返回下一个元素
yield不会终止程序,返回值之后程序继续运行
示例:求斜边小n的勾股数组合
#定义函数,根据传入的参数求取符合运算所有结果
def list_pythagorean_triples(n) :
for c in range(n):
for a in range(1, c):
for b in range(1, c):
if a*a+b*b==c*c:
yield (a,b,c)
#生成器的使用方法
1.for循环迭代生成器
for i in list_pythagorean_triples(35):
print(i)
2.next()函数从生成器中取值
g = list_pythagorean_triples(100)
next(g)
3.构造生成器的结果列表
g = list_pythagorean_triples(100)
list(g)
- 生成器表达式
#将10以内的值求取3次方
(x**3 for x in range(10))
#遍历输出
for num in (x**3 for x in range(10))
print(num)
#输出
0
1
8
27
64
125
216
343
512
729
- 列表生成式
#定义列表生成方式
[x**3 for x in range(10)]
31.lambda匿名函数
- lambda表达式语法
lambda param1, param2, … : expression
- 使用示例
f=lambda x: x * x
f(3) #输出9
# return results of +, -, *, //, % in a list
f=lambda x,y: [x+y, x-y, x*y, x//y, x%y]
f(10,2) #输出列表[12, 8, 20, 5, 0]
# return max, min, sum in a tuple
f=lambda *n: (max(n), min(n), sum(n))
f(1,2,3,4,5) #输出结果 (5,1,15)
# sum 1 to n
f=lambda n: sum(range(1, n+1))
f(2) #输出3
filter()函数中使用lambda表达式
- 过滤掉不符合条件的元素,返回由符合条件元素组成的新列表
items=[0, 1, 2, 3, 4, 5]
list(filter(lambda x: x%2==0, items))
list(filter(None, items))
map()函数中使用lambda表达式
- 根据提供的函数对指定序列做映射
i1=[1, 2, 3, 4, 5, 6]
i2=[11, 12, 13, 14]
i3=[111, 112]
list(map(lambda x,y,z: x+y+z, i1, i2, i3))
max()函数中使用lambda表达式
- 返回序列中的最大值
max(1,2,3,4)
max([1,2,3,4])
max([1,2,3,4], key=lambda x:-x)
min()函数中使用lambda表达式
- 返回序列中的最小值
min(1,2,3,4)
min([1,2,3,4])
min([1,2,3,4], key=lambda x:-x)
sorted()函数中使用lambda表达式
- 对序列进行排序
sorted([1,2,4,3], reverse=True)
sorted([1,2,4,3], key=lambda x:-x)
32.正则表达式
Python正则表达式模块:import re
常用方法

匹配符



- 默认为贪婪匹配
re.match('.{2,6}c', 'abcdcfchc') # match 'abcdcfc'
- ?为非贪婪匹配
re.match('.{2,6}?c', ' abcdcfchc') # match ‘abc'
- 0长度匹配
re.sub('a?', '-', 'bb') # result: '-b-b-'
re.sub('a*', '-', 'bb') # result: '-b-b-'