title: Day37-数据结构与算法-串、其他
date: 2021-02-24 17:57:30
author:Liu_zimo
常用的经典数据结构
布隆过滤器(Bloom Filter)
- 1970年由布隆提出
- 它是一个空间效率高的概率型数据结构,可以用来告诉你:一个元素一定不存在或者可能存在
- 优缺点
- 优点:空间效率和查询时间都远远超过一般的算法
- 缺点:有一定的误判率、删除困难
- 它实质上是一个很长的二进制向量和一系列随机映射函数(Hash函数)
- 常见应用
- 网页黑名单系统、垃圾邮件过滤系统、爬虫的网址判重系统、解决缓存穿透问题
布隆过滤器的原理
- 假设布隆过滤器由20位二进制、3个哈希函数组成,每个元素经过哈希函数处理都能生成一个索引位置
- 添加元素:将每一个哈希函数生成的索引位置都设为1
- 查询元素是否存在
- 如果有一个哈希函数生成的索引位置不为1,就代表不存在(100%准确)
- 如果每一个哈希函数生成的索引位置都为1,就代表存在(存在一定的误判率)
- 添加、查询的时间复杂度都是:O(k),k是哈希函数的个数。空间复杂度是:O(m),m是二进制位的个数
- 误判率p受3个因素影响:二进制位的个数m、哈希函数的个数k、数据规模n
- p = (1 - e- ( [k(n + 0.5)] / (m - 1) ))k == (1 - e- (kn / m))k
- 已知误判率p、数据规模n,求二进制位的个数m、哈希函数的个数k
- m = - (nlnp) / (ln2)2 lnp = logep
- k = (m / n) ln2 k = - (lnp / ln2) = -log2p
布隆过滤器的实现
- Guava:Google Core Libraries For Java
https://mvnrepository.com/artifact/com.google.guava/guava
package com.zimo.算法.串_其他;
/**
* 布隆过滤器
*
* @author Liu_zimo
* @version v0.1 by 2021/2/25 10:14
*/
public class BloomFilter<T> {
private int bitSize; // 二进制向量的长度(一共有多少个二进制位)
private long[] bits; // 二进制向量 [[0-63], [64-127], [128 - 191]] [64,63,62,61,...2,1,0]
private int hashSize; // 哈希函数的个数
/**
* 构造一个布隆过滤器
* @param n 数据规模
* @param p 误判率,取值范围(0,1)
*/
public BloomFilter(int n, double p) {
double ln2 = Math.log(2);
// 求出二进制向量的长度
this.bitSize = (int)(- (n * Math.log(p)) / (ln2 * ln2));
// 求出哈希函数的个数
this.hashSize = (int) (bitSize * ln2 / n);
this.bits = new long[(bitSize + Long.SIZE - 1)/ Long.SIZE];
}
/**
* 添加元素
* @param value
*/
public void put(T value){
nullCheck(value);
int hash1 = value.hashCode();
int hash2 = hash1 >>> 16;
for (int i = 0; i <= hashSize; i++) {
int combinedHash = hash1 + (i * hash2);
if (combinedHash < 0){
combinedHash = ~combinedHash;
}
// 生成一个二进制位的索引
int index = combinedHash % this.bitSize;
// 设置index位置的二进制位为1
set(index);
}
}
/**
* 判断是否存在一个元素
* @param value
* @return
*/
public boolean contains(T value){
nullCheck(value);
int hash1 = value.hashCode();
int hash2 = hash1 >>> 16;
for (int i = 0; i <= hashSize; i++) {
int combinedHash = hash1 + (i * hash2);
if (combinedHash < 0){
combinedHash = ~combinedHash;
}
// 生成一个二进制位的索引
int index = combinedHash % this.bitSize;
// 查询index位置的二进制位是否为0
if (!get(index)) return false;
}
return true;
}
private void set(int index){
// 找到对应的long位置
long value = this.bits[index / Long.SIZE];
// 找到二进制位在long内部的索引
this.bits[index / Long.SIZE] = value | (1 << (index % Long.SIZE));
}
private boolean get(int index){
long value = this.bits[index / Long.SIZE];
value = value & (1 << (index % Long.SIZE));
return value != 0;
}
private void nullCheck(T value){
if (value == null){
throw new IllegalArgumentException("value must not be null");
}
}
public static void main(String[] args) {
BloomFilter<Integer> integerBloomFilter = new BloomFilter<>(1_00_0000, 0.01);
for (int i = 0; i < 500; i++) {
integerBloomFilter.put(i);
}
for (int i = 0; i < 500; i++) {
System.out.println(integerBloomFilter.contains(i));
}
int error = 0;
for (int i = 500; i < 1000; i++) {
if (integerBloomFilter.contains(i)){
error++;
}
}
System.out.println(error);
}
}
跳表(SkipList)
-
一个有序链表搜索、添加、删除的平均时间复杂度是多少?
- O(n)
-
能否利用二分搜索优化有序链表,将搜索、添加、删除的平均时间复杂度降低至O(logn)?
- 链表没有像数组那样的高效随机访问(O(1)时间复杂度),所以不能像有序数组那样直接进行二分搜索进行优化
-
那有没有其他办法让有序链表搜索、添加、删除的平均时间复杂度降低至O(logn)?
- 使用跳表(SkipList)
-
跳表,又叫做跳跃表、跳跃列表,在有序链表的基础上增加了“跳跃”的功能
- 由William Pugh于1990年发布,设计的初衷是为了取代平衡树(比如红黑树、AVL树)
-
Redis中的SortedSet、LevelDB中的MemTable都用到了跳表
- Redis、LevelDB都是著名的Key-Value数据库
-
对比平衡树
- 跳表的实现和维护会更加简单
- 跳表的搜索、删除、添加的平均时间复杂度是O(logn)

跳表的搜索
- 从顶层链表的首元素开始,从左往右搜索,直至找到一个大于或等于目标的元素,或者到达当前层链表的尾部
- 如果该元素等于目标元素,则表明该元素已被找到
- 如果该元素大于目标元素或已到达链表的尾部,则退回到当前层的前一个元素,然后转入下一层进行搜索
跳表的添加、删除
- 添加的细节
- 随机决定新添加元素的层数
- 删除的细节
- 删除一个元素后,整个跳表的层数可能会降低
跳表的层数
- 跳表是按层构造的,底层是一个普通的有序链表,高层相当于是低层的“快速通道”
- 在第i层中的元素按某个固定的概率p(通常为1/2或1/4)出现在第i+1层中,产生越高的层数,概率越低
- 元素层数恰好等于1的概率为1 - p
- 元素层数大于等于2的概率为p,而元素层数恰好等于2的概率为p * (1 - p)
- 元素层数大于等于3的概率为p ^ 2,而元素层数恰好等于3的概率为p ^ 2 * (1 - p)
- 元素层数大于等于4的概率为p ^ 3,而元素层数恰好等于4的概率为p ^ 3 * (1 - p)
- …
- 一个元素的平均层数是1 / (1 - p)
- 在第i层中的元素按某个固定的概率p(通常为1/2或1/4)出现在第i+1层中,产生越高的层数,概率越低
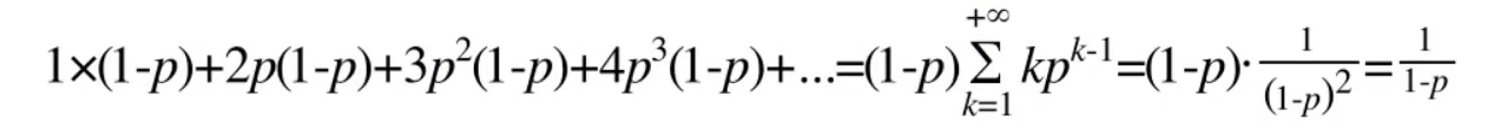
- 当p = 1/2时,每个元素所包含的平均指针数量是2
- 当p= 1/4时,每个元素所包含的平均指针数量是1.33
跳表的复杂度
- 每一层的元素数量
- 第1层链表固定有n个元素
- 第2层链表平均有n * p个元素
- 第3层链表平均有n * p ^ 2个元素
- 第k层链表平均有n * p ^ k个元素
- …
- 另外
- 最高层的层数是log1/pn,平均有个1/p元素
- 在搜索时,每一层链表的预期查找步数最多是1/p,所以总的查找步数是-(logpn/p),时间复杂度是O(logn)
B+树
-
B+树是B树的变体,常用于数据库和操作系统的文件系统中
- MySQL数据库的索引就是基于B+树实现的
-
B+树的特点
-
分为内部节点(非叶子)、叶子节点2种节点
内部节点只存储key,不存储具体数据
叶子节点存储key和具体数据 -
所有的叶子节点形成一条有序链表
-
m阶B+树非根节点的元素数量x
ceil(m/2) ≤ x ≤ m
-
MySQL的索引底层为何使用B+树
- 为了减小IO操作数量,一般把一个节点的大小设计成最小读写单位的大小
- MySQL的存储引擎lnnoDB的最小读写单位是16K
- 对比B树,B+树的优势是
- 每个节点存储的key数量更多,树的高度更低
- 所有的具体数据都存在叶子节点上,所以每次查询都要查到叶子节点,查询速度比较稳定
- 所有的叶子节点构成了一个有序链表,做区间查询时更方便
B*树
- B* 树是B+树的变体:给内部节点增加了指向兄弟节点的指针
- m阶B*树非根节点的元素数量x
ceil(2m/3) ≤ x ≤ m
串(Sequence)
-
本课程研究的串是开发中非常熟悉的字符串,是由若干个字符组成的有限序列
String Text = "thank"; -
字符串thank的前缀(prefix)、真前缀(proper prefix)、后缀(suffix)、真后缀(proper suffix)
前缀 t、th、tha、than、thank 真前缀 t、th、tha、than 后缀 thank、hank、ank、nk、k 真后缀 hank、ank、nk、k
串匹配算法
-
本课程主要研究串的匹配问题,比如
-
查找一个模式串(Pattern)在文本串(Text)中的位置
String text = "Hello World"; String pattern = "or"; text.indexOf(pattern); // 7 text.indexOf("other"); // -1
-
-
几个经典的串匹配算法
- 蛮力(Brute Force)
- KMP
- Boyer-Moore
- Rabin-Karp
- Sunday
-
本课程用tlen代表文本串Text的长度,plen 代表模式串Pattern的长度
蛮力(Brute Force)
- 以字符为单位,从左到右移动模式串,直到匹配成功

- 蛮力算法有两种常见实现思路
蛮力1

package com.zimo.算法.串_其他.串.蛮力;
/**
* 蛮力算法1
*
* @author Liu_zimo
* @version v0.1 by 2021/2/26 14:46
*/
public class BruteForce_1 {
private static int indexOf(String text, String pattern){
if (text == null || pattern == null) return -1;
char[] textChars = text.toCharArray();
int tlen = textChars.length;
if (tlen == 0) return -1;
char[] patternChars = pattern.toCharArray();
int plen = patternChars.length;
if (plen == 0) return -1;
if (tlen < plen) return -1;
int pi = 0, ti = 0;
while (pi < plen && ti <tlen){
if (textChars[ti] == patternChars[pi]){
ti++;
pi++;
}else{
ti -= pi - 1;
pi = 0;
}
}
return pi == plen ? (ti - pi) : -1;
}
private static int indexOf2(String text, String pattern){
if (text == null || pattern == null) return -1;
char[] textChars = text.toCharArray();
int tlen = textChars.length;
if (tlen == 0) return -1;
char[] patternChars = pattern.toCharArray();
int plen = patternChars.length;
if (plen == 0) return -1;
if (tlen < plen) return -1;
int pi = 0, ti = 0;
while (pi < plen && ti - pi <= tlen - plen){
// 优化
if (textChars[ti] == patternChars[pi]){
ti++;
pi++;
}else{
ti -= pi - 1;
pi = 0;
}
}
return pi == plen ? (ti - pi) : -1;
}
}
- 因此,ti的退出条件可以从ti < tlen 改为
- ti - pi <= tlen - plen
- ti - pi是指每一轮比较中Text首个比较字符的位置
蛮力2

package com.zimo.算法.串_其他.串.蛮力;
/**
* 蛮力算法2
*
* @author Liu_zimo
* @version v0.1 by 2021/2/26 14:46
*/
public class BruteForce_2 {
private static int indexOf(String text, String pattern){
if (text == null || pattern == null) return -1;
char[] textChars = text.toCharArray();
int tlen = textChars.length;
if (tlen == 0) return -1;
char[] patternChars = pattern.toCharArray();
int plen = patternChars.length;
if (plen == 0) return -1;
if (tlen < plen) return -1;
for (int ti = 0; ti <= tlen - plen; ti++) {
int pi = 0;
for (;pi < plen; pi++) {
if (textChars[ti + pi] != patternChars[pi])break;
}
if (pi == plen) return ti;
}
return -1;
}
}
蛮力 - 性能分析
- n是文本串长度,m是模式串长度
- 最好情况
- 只需一轮比较就完全匹配成功,比较m次( m是模式串的长度)
- 时间复杂度为O(m)
- 最坏情况(字符集越大,出现概率越低)
- 执行了n - m + 1轮比较(n是文本串的长度)
- 每轮都比较至模式串的末字符后失败(m - 1次成功,1次失败)
- 时间复杂度为O(m * (n - m + 1)),由于一般m远小于n,所以为O(nm)
KMP
- KMP是 Knuth-Morris-Pratt 的简称(取名自3位发明人的名字),于1977年发布

- KMP会预先根据模式串的内容生成一张next表(一般是个数组)
| 模式串“ABCDABCE”的next表 | ||||||||
|---|---|---|---|---|---|---|---|---|
| 模式串字符 | A | B | C | D | A | B | C | E |
| 索引 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 元素 | -1 | 0 | 0 | 0 | 0 | 1 | 2 | 3 |
KMP - 核心原理

- 当d、e失配时,如果希望Pattern能够一次性向右移动一大段距离,然后直接比较d、c字符
- 前提条件是A必须等于B
- 所以KMP必须在失配字符e左边的子串中找出符合条件的A、B,从而得知向右移动的距离
- 向右移动的距离:e左边子串的长度-A的长度,等价于:e的索-c的索引
- 且c的索引 == next[e的索引],所以向右移动的距离:e的索引 - next[e的索]
- 总结
- 如果在pi位置失配,向右移动的距离是pi - next[pi],所以next[pi]越小,移动距离越大
- next[pi]是pi左边子串的真前缀后缀的最大公共子串长度
KMP - 得到next表
| 模式串字符 | A | B | C | D | A | B | C | E |
| 元素 | 0 | 0 | 0 | 0 | 1 | 2 | 3 | 0 |
- 将最大公共子串长度都向后移动1位,首字符设置为负1,就得到了next表
| 模式串“ABCDABCE”的next表 | ||||||||
|---|---|---|---|---|---|---|---|---|
| 模式串字符 | A | B | C | D | A | B | C | E |
| 索引 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 元素 | -1 | 0 | 0 | 0 | 0 | 1 | 2 | 3 |
KMP - 为什么是“最大”公共子串长度
- 假设文本串是AAAAABCDEF,模式串是AAAAB
| 模式串 | 真前缀 | 真后缀 | 公共子串长度 |
|---|---|---|---|
| AAAA | A,AA,AAA | A,AA,AAA | 1,2,3 |
| AAA | A,AA | A,AA | 1,2 |
| AA | A | A | 1 |

KMP - next表的构造思路

KMP - next表的不足之处

- 在这种情况下,KMP显得比较笨拙
KMP - next表的优化思路

| 模式串“AAAAB”的next表 | ||||||||
|---|---|---|---|---|---|---|---|---|
| 模式串字符 | A | A | A | A | B | |||
| 索引 | 0 | 1 | 2 | 3 | 4 | |||
| 优化前 | -1 | 0 | 1 | 2 | 3 | |||
| 优化后 | -1 | -1 | -1 | -1 | 3 | |||
package com.zimo.算法.串_其他.串.KMP;
/**
* KMP算法
*
* @author Liu_zimo
* @version v0.1 by 2021/2/26 17:21
*/
public class KMP {
private static int indexOf(String text, String pattern){
if (text == null || pattern == null) return -1;
char[] textChars = text.toCharArray();
int tlen = textChars.length;
if (tlen == 0) return -1;
char[] patternChars = pattern.toCharArray();
int plen = patternChars.length;
if (plen == 0) return -1;
if (tlen < plen) return -1;
// next表
int[] next = next1(pattern);
int pi = 0, ti = 0;
while (pi < plen && ti - pi <= tlen - plen){
// 优化
if (pi < 0 || textChars[ti] == patternChars[pi]){
ti++;
pi++;
}else{
// 失配情况
pi = next[pi];
}
}
return pi == plen ? (ti - pi) : -1;
}
private static int[] next(String pattern){
char[] chars = pattern.toCharArray();
int[] next = new int[chars.length];
int i = 0;
int n = next[0] = -1; // next表头设置为-1 , n == next[i]
int iMax = chars.length -1;
while (i < iMax){
if (n < 0 || chars[i] == chars[n]){
next[++i] = n + 1;
}else {
n = next[n];
}
}
return next;
}
// 优化next表
private static int[] next1(String pattern){
char[] chars = pattern.toCharArray();
int[] next = new int[chars.length];
int i = 0;
int n = next[0] = -1; // next表头设置为-1 , n == next[i]
int iMax = chars.length -1;
while (i < iMax){
if (n < 0 || chars[i] == chars[n]){
++i;
++n;
if (chars[i] == chars[n]){
next[i] = next[n];
}else {
next[i] = n;
}
}else {
n = next[n];
}
}
return next;
}
public static void main(String[] args) {
System.out.println(KMP.indexOf("AAABCD", "BC"));
}
}
KMP - 性能分析
- KMP主逻辑
- 最好时间复杂度:O(m)
- 最坏时间复杂度:O(n),不超过O(2n)
- next表的构造过程跟KMP主体逻辑类似
- 时间复杂度:O(m)
- KMP整体
- 最好时间复杂度:O(m)
- 最坏时间复杂度:O(n + m)
- 空间复杂度:O(m)
蛮力 vs KMP
- 蛮力算法为何低效?
- 当字符失配时蛮力算法
- ti回溯到左边位置
- pi回溯到0
- KMP算法
- ti不必回溯
- pi不一定要回溯到0
Boyer - Moore
- Boyer-Moore算法,简称BM算法,由Robert S.Boyer和J Strother Moore于1977年发明
- 最好时间复杂度:O(n/m),最坏时间复杂度:O(n + m)
- 该算法从模式串的尾部开始匹配(自后向前)
- BM算法的移动字符数是通过2条规则计算出的最大值
- 坏字符规则(Bad Character,简称BC)
- 好后缀规则(Good Suffix,简称GS)
坏字符(Bad Character)

- 当Pattern中的字符E和Text中的S失配时,称S为“坏字符”
- 如果 Pattern 的未匹配子串中不存在坏字符,直接将 Pattern 移动到坏字符的下一位
- 否则,让 Pattern 的未匹配子串中最靠右的坏字符与Text中的坏字符对齐
好后缀(Good Suffix)

- “MPLE”是一个成功匹配的后缀,“E”、“LE” 、“PLE”、“MPLE”都是“好后缀”
- 如果 Pattern 中找不到与好后缀对齐的子串,直接将Pattern移动到好后缀的下一位
- 否则,从 Pattern 中找出子串与Text 中的好后缀对齐
BM的最好情况

- 时间复杂度:O(n/m)
BM的最坏情况

- 时间复杂度:O(n + m)
- 其中的O(m)是构造 BC、GS表
Rabin-Karp
- Rabin-Karp算法(或Karp-Rabin算法),简称RK算法,是一种基于hash的字符串匹配算法
- 由Richard M. Karp和Michael O. Rabin于1987年发明
- 大致原理
- 将Pattern的hash值与Text中每个子串的hash值进行比较
- 某一子串的hash 值可以根据上一子串的 hash 值在O(1)时间内计算出来
Sunday
- Sunday算法由 Daniel M.Sunday 在1990年提出,它的思想跟BM算法很相似
- 从前向后匹配
- 当匹配失败时,关注的是Text中参与匹配的子串的下一位字符A
- 如果A没有在Pattern 中出现,则直接跳过,即移动位数 = Pattern长度+1
- 否则,让 Pattern中最靠右的A与Text 中的A对齐
