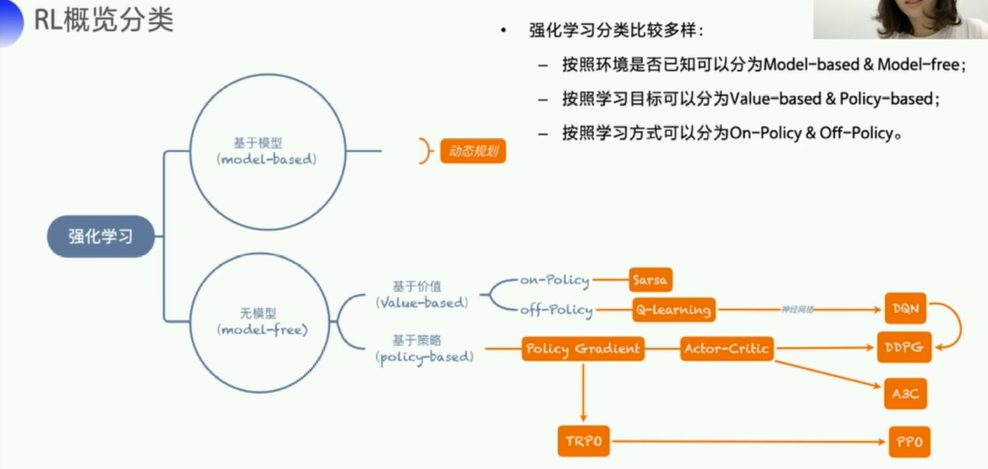
1. Sarsa
1.1 Sarsa简介
- 全称是:
state action reward state action, - 目的是学习特定
state下,特定action的价值Q,最终来建立和优化一个Q表格,以state为行,action为列,根据与环境交互得到的reward来更新Q表格,更新公式为:
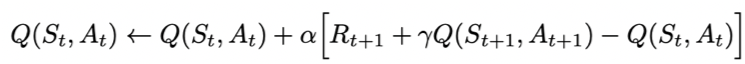

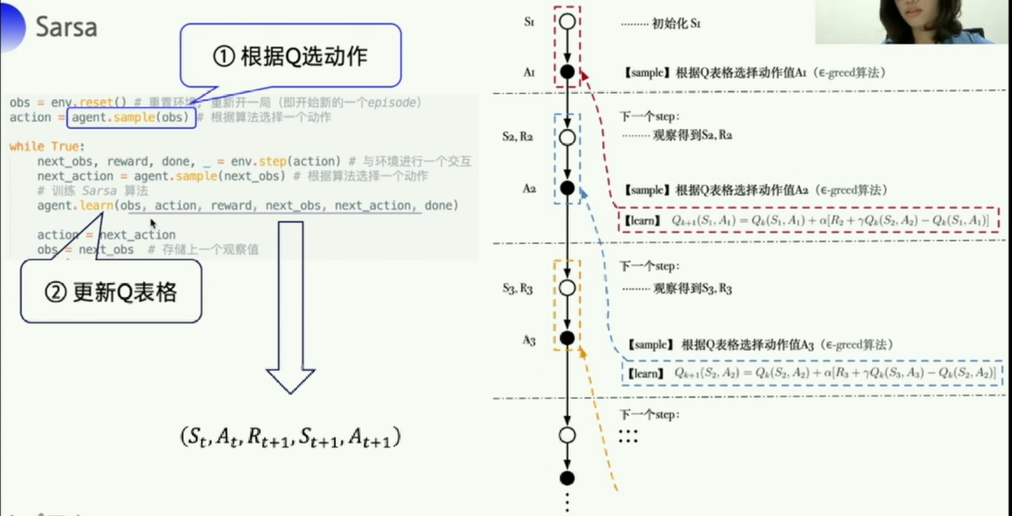


参考教程把代码更新一下,进行一下可视化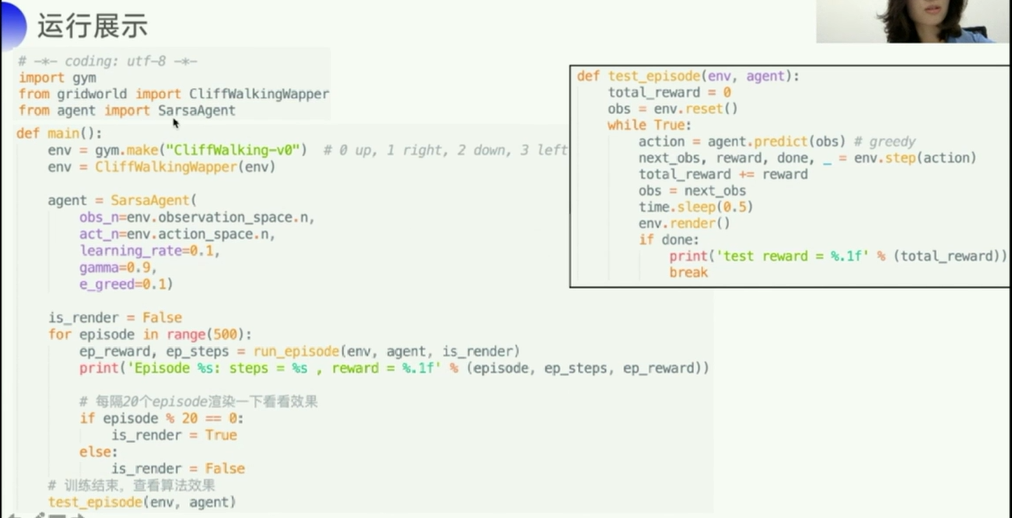
可视化之后,可以很明显看到,有时候得到的最终的reward是-17,走的是最远的路径。。。 - 很明显,不是最优的一个方式
- 尝试修改 ϵ \epsilon ϵ,从0.1→0.5,gamma,0.9→0.7也好像还是没什么用,sarsa总是离悬崖很远,可能是因为悬崖的reward -100惩罚太狠了。
1.2 Sarsa实战
解决悬崖问题 cliff walking
参考:强化学习7日打卡营-世界冠军带你从零实践 Lesson2-Sarsa
一些说明
主要是关于gym中env的一些使用说明,因为agent是自己写的,没有太多要说的。
import gym
env=gym.make("CliffWalking-v0")
env.observation_space.n
Out[4]: 48
env.action_space.n
Out[5]: 4
- env.reset() 重置即初始化环境,一般会返回一个整数,就是初始状态
- 这说明,在gym中,一旦创建了一个环境,
状态空间中状态的个数和动作空间中动作的个数就是确定的
可以看到网上有许多看西瓜书部分强化学习进行的笔记,虽然和抄书没有区别,但是很好看啊,哈哈
- 【西瓜书】第十六章 强化学习
- 【基础知识十六】强化学习
- 强化学习(基本概念)
- 《Machine Learning》 学习笔记十七 强化学习
- 强化学习理论及算法推导
- 强化学习-有模型学习–值函数的T步累积奖赏递归推导过程
1.3 Sarsa参数调整
由于Sarsa确定下一步要执行的action时采用的是 ϵ \epsilon ϵ-greed方式,所以很难收敛,很难求得最优策略,一般会需要再额外制定一个策略,让 ϵ \epsilon ϵ的参数坦索罗在迭代过程中逐渐变小。
由于训练轮数比较多,这里直接调节一波 ϵ \epsilon ϵ参数的初始值,观察一下结果:
ϵ = 0.1 \epsilon=0.1 ϵ=0.1
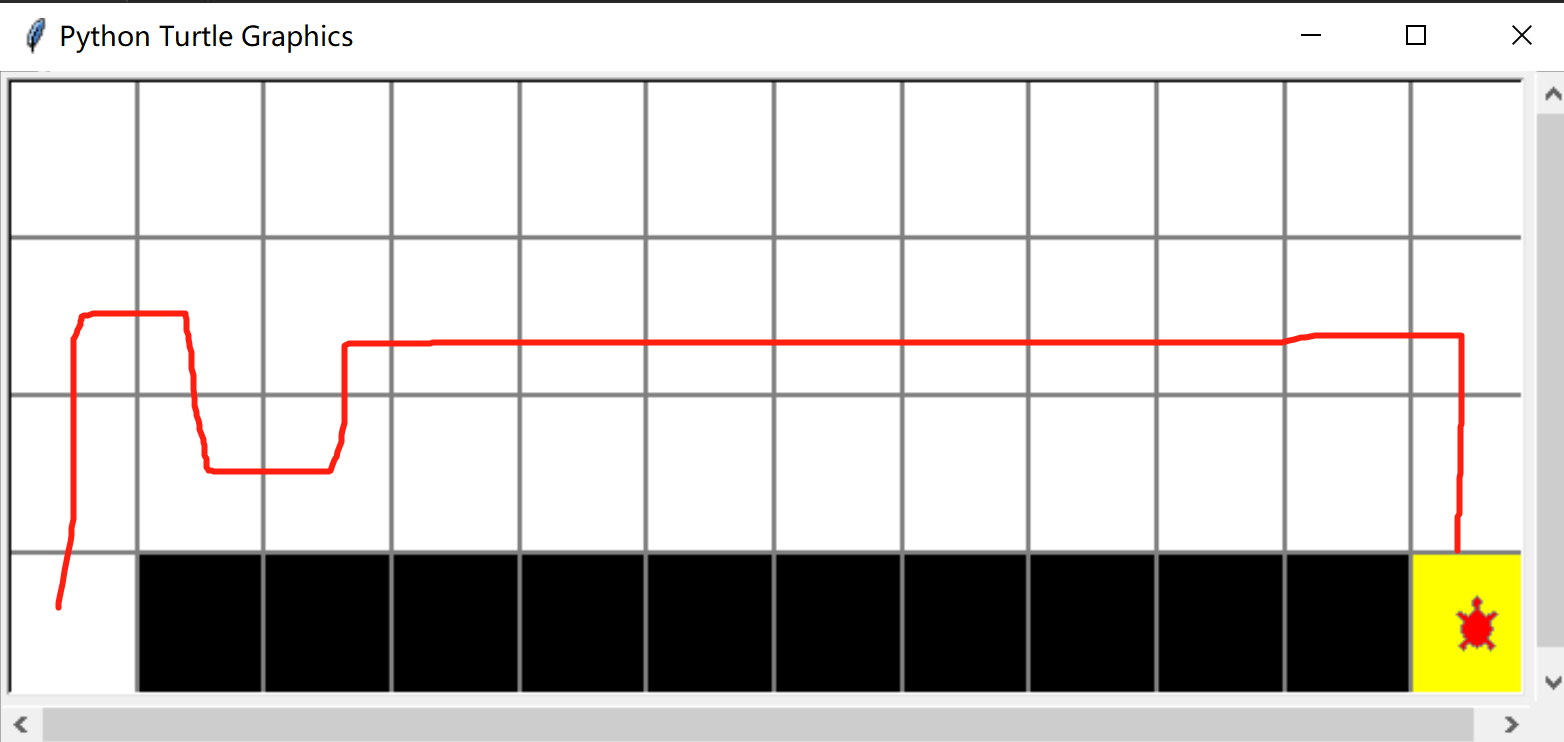
走一步-1的reward,这种路线是-17
ϵ = 0.008 \epsilon=0.008 ϵ=0.008
随机性太强,偶尔能跑出来-17,好的时候可以跑出来-15,有时候会在两个格子之间往复。。。不稳定
2. Q-learning
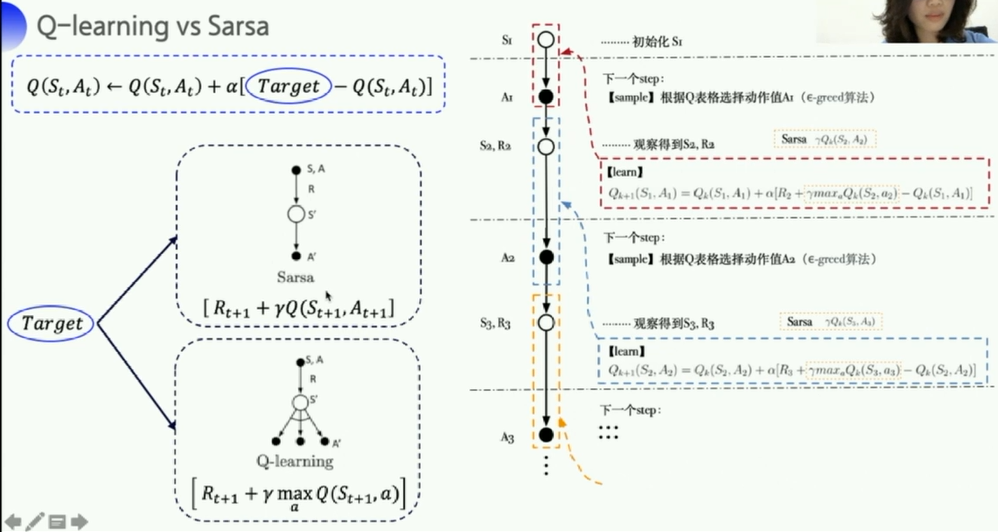
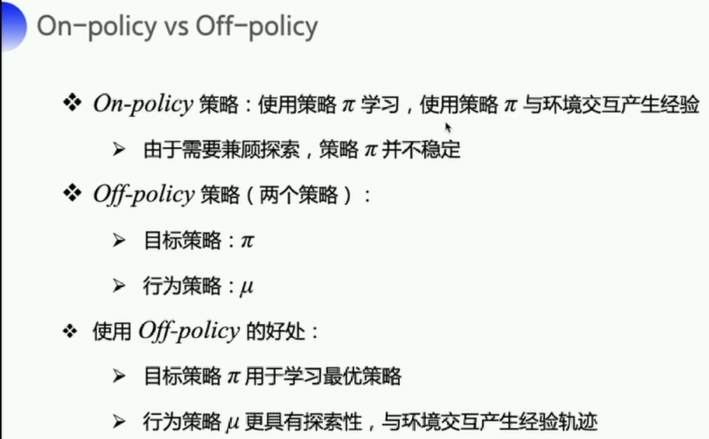
Sarsa是一种on-policy的策略,sarsa实际上优化的是它执行的策略
- on-policy:优化的是实际执行的策略,直接用下一步一定会执行的action(下一步动作已知的情况下)来优化Q表格。
- 所以sarsa在进行动作的时候,如果发现自己的下一步可能是悬崖,那么这个动作就会被调整,离悬崖越远越好
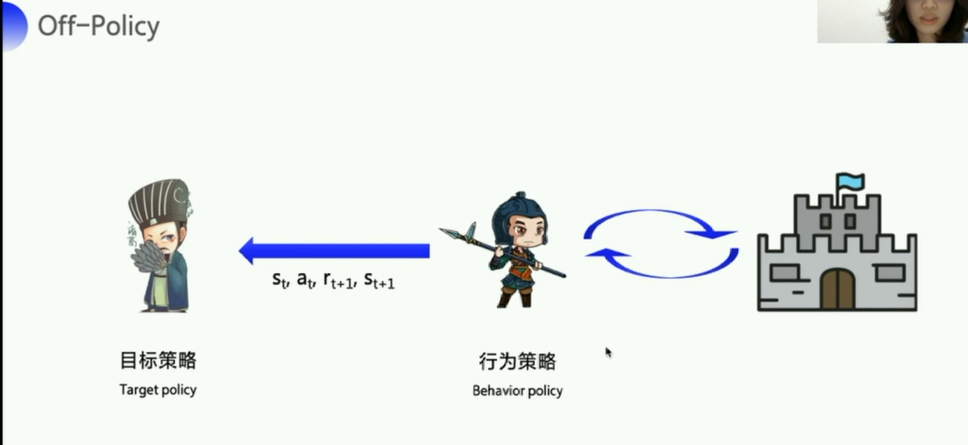
- off-policy:
- 探索环境的策略:行为策略(Behavior policy)
- 目标策略:行为策略把东西传给目标策略(一个是前线士兵,一个是坐镇后方的军师)

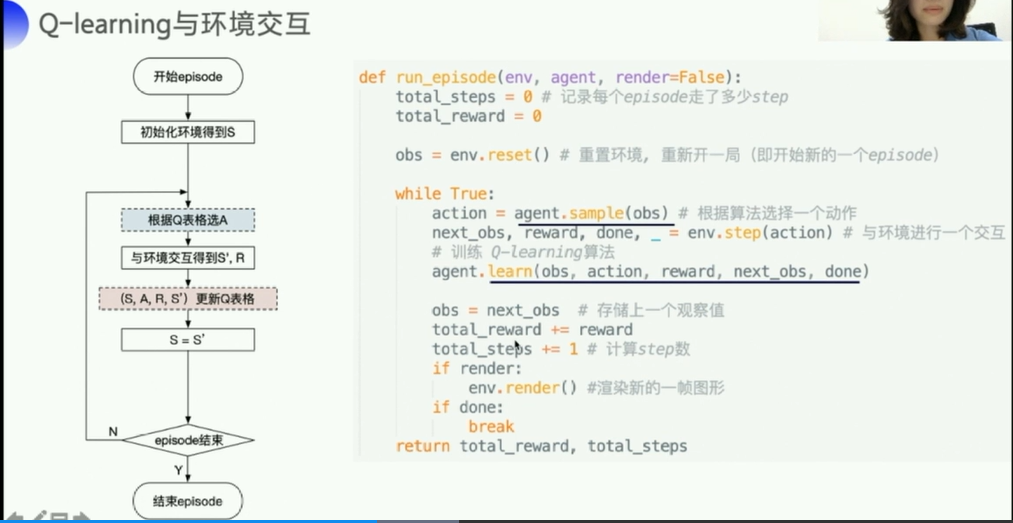
也可以使用月Sarsa一样的加入gridworld的可视化界面,来看看学习的过程
可以看到,最终的reward是-13,比Sarsa高
Q-learning的平均分可能没有sarsa高,但是最后评估的结果可能比sarsa高
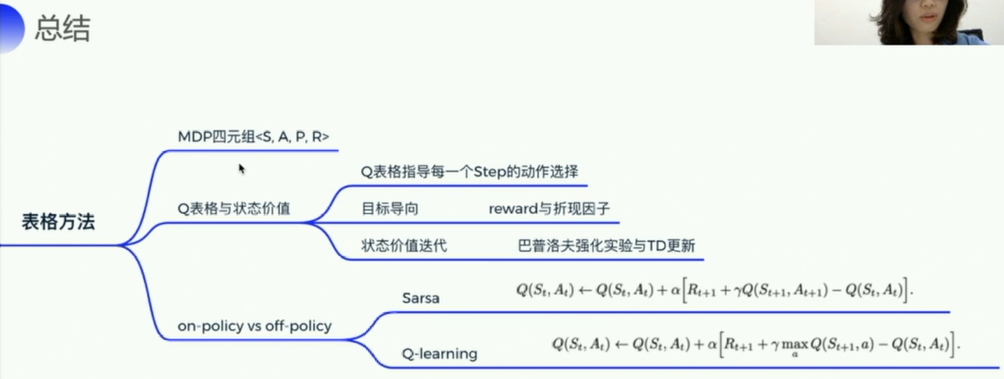
4. MDP、Q表格
使用的是基于value_based的方法来求解强化学习
4.1MDP
马尔科夫决策过程(Markov Decision Process,以下简称MDP)
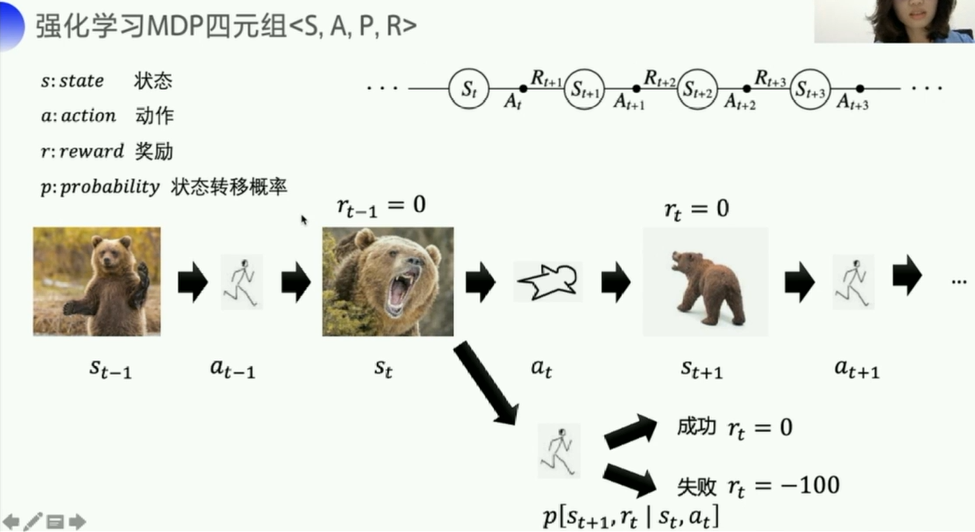
p [ s t + 1 , r t ∣ s t , a t ] p[s_{t+1},r_t|s_t,a_t] p[st+1,rt∣st,at]这个概率描述的是,
-
agent(上图中的小人)从 s t s_t st状态,采取行动 s t s_t st之后
-
转移到新的状态 s t + 1 s_{t+1} st+1并获取reward(奖励) r t r_t rt的概率
-
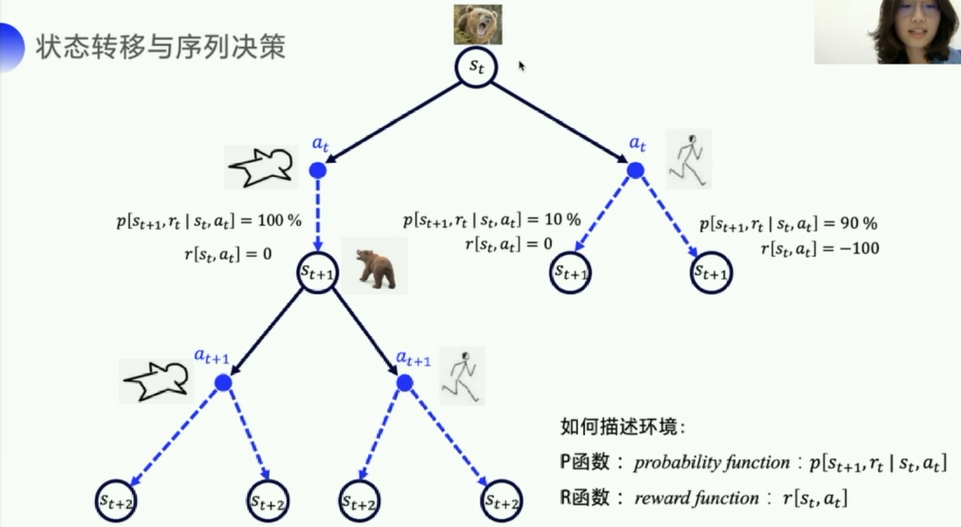
上述其实是一个假设情况,如果概率和奖励都已知,可以直接使用动态规划的方式来求解。
-
但实际上更多的场景里,无法知道p函数,比如熊追你,你有多大概率逃走或者逃不走,装死有多大概率生还或者XXX。
-
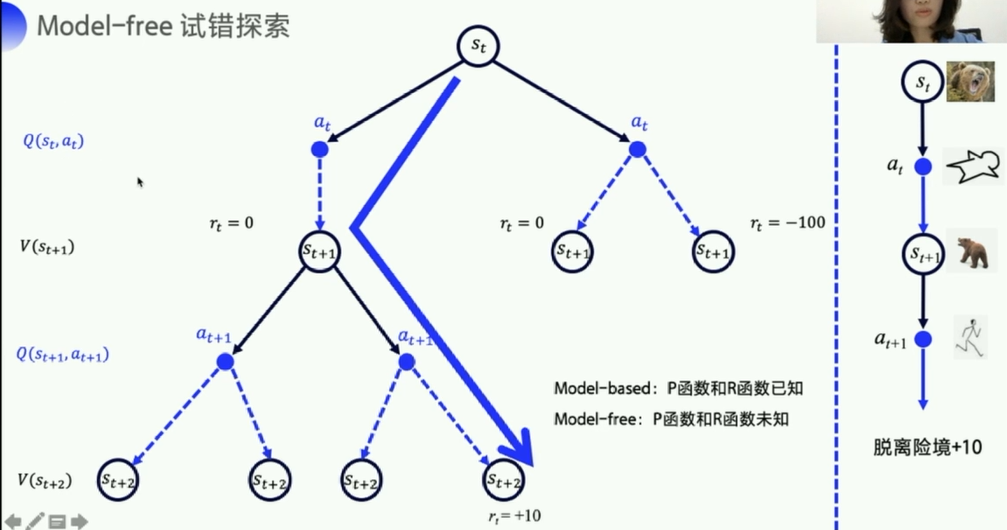
价值函数V, V ( s t + 1 ) V(s_{t+1}) V(st+1)来代表状态的好坏,
-
Q函数, Q ( s t , a t ) Q(s_t,a_t) Q(st,at)来描述在某种状态下,进行何种动作能得到最大的奖励,
状态动作价值- Q 基于表格对RL进行求解的方式所建立的Q表格就是对应于Q函数(状态是行,动作是列)
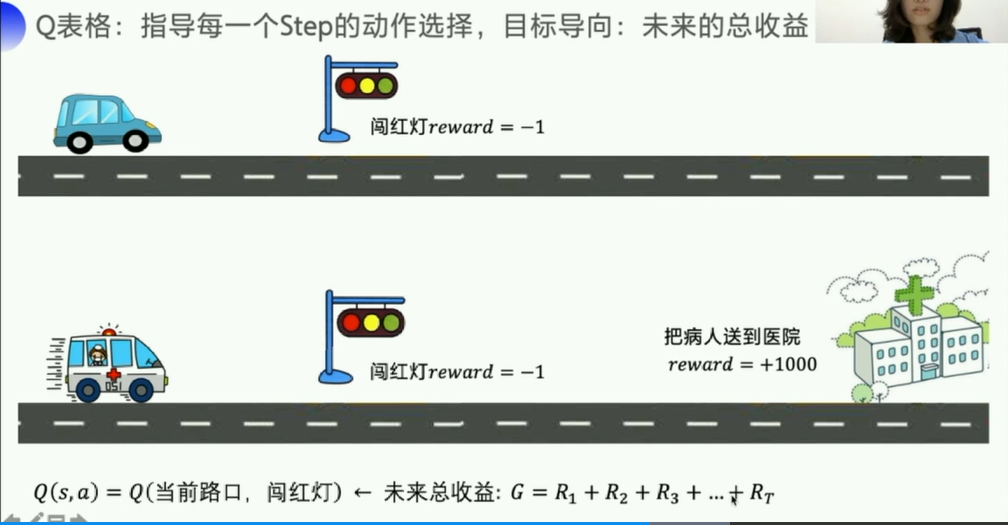
强化学习有一个非常明显的目标导向:未来的总收益
单步收益 vs 未来总收益
从当前步开始到后面总共的价值,这个数据才能够说明当前这步的价值如何,是否是好/坏!
高考英语考试/考研英语考试/公务员考试
对于英语考试:听力分值不多,但是占的时间还长。分配时间的时候适当放弃一部分分数,以得到更高的分数;
公务员考试:计算题分值低,耗时长,放弃一部分,但是后面题目带来的收益提高了整体最后的长期收益。
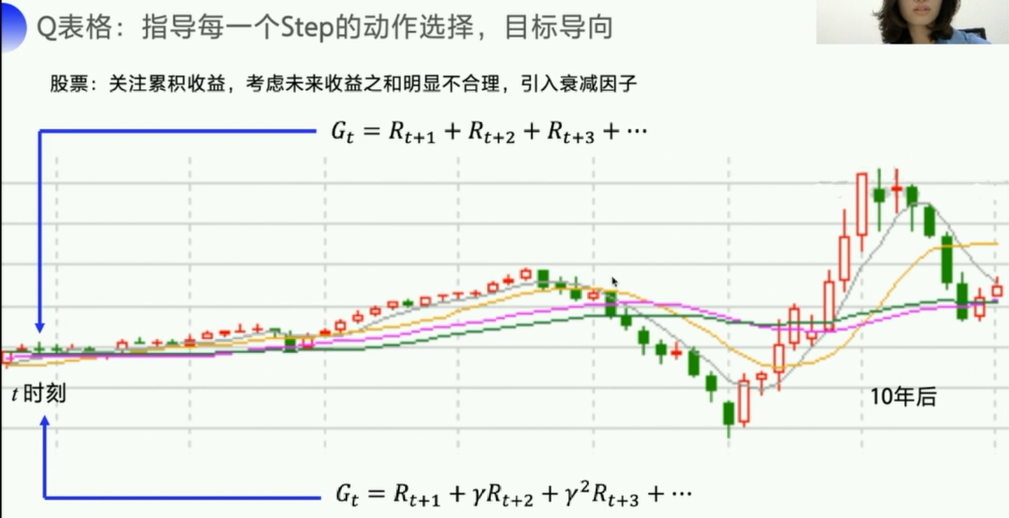
引入衰减因子。
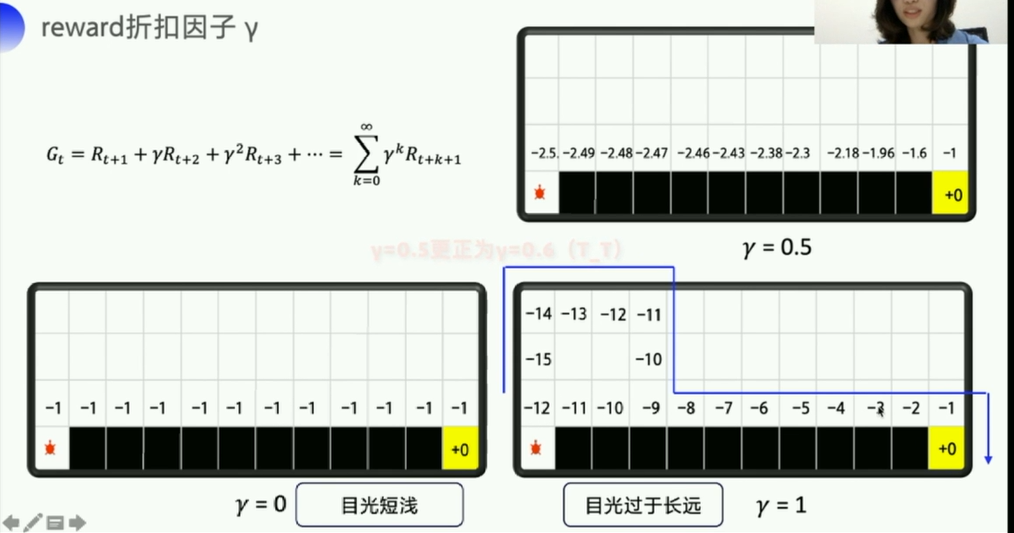
以悬崖问题为例
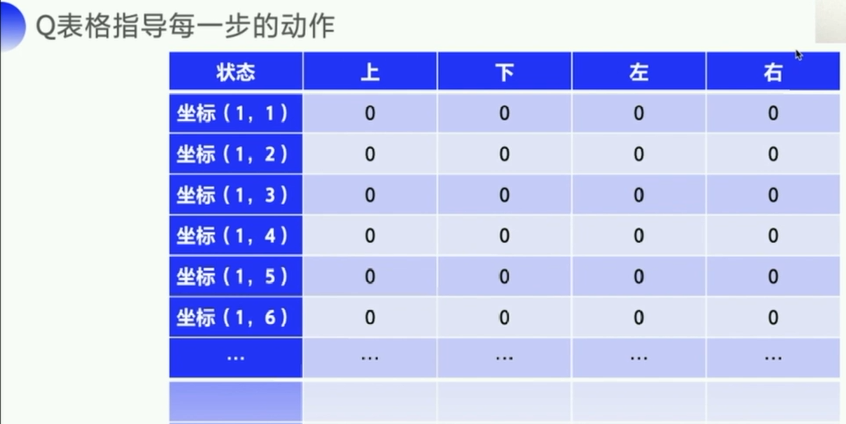
Q表格,一开始初始化为0,随着agent与环境的交互,就可以估算出
每个状态下:每个行动的平均总收益
4.2 如何更新Q表格
强化学习的概念就是:
- 可以用下一个状态的价值来更新当前状态的价值
- 强化学习中有一个bootstrap自举的概念
- 每走一步,更新一次Q表格中对应的内容(用下一个状态来更新当前状态)
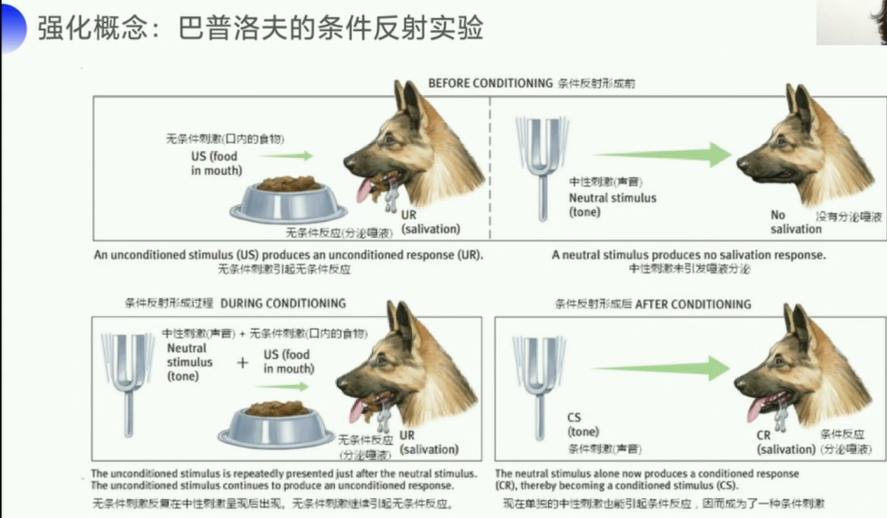
- 这里要表达一个概念:下一个状态的价值是可以影响上一个状态的。
- 比如:
看到杨梅→吃杨梅→感到酸, - 但是多次吃过杨梅之后,会造成,
看到杨梅→感到酸
- 比如:

https://cs.stanford.edu/people/karpathy/reinforcejs/gridworld_td.html
4.2.1 时序差分 TD单步更新

4.3 总结

其实很简单,把环境修改就可以了,因为动作和状态都是环境规定的,优化策略不变,直接改变环境就可以。

参考