RDB存储的弊端
- 存储数据量较大,效率较低——基于快照思想,每次读写都是全部数据,当数据量巨大时,效率非常低
- 大数据量下的IO性能较低
- 基于fork创建子进程,内存产生额外消耗
- 宕机带来的数据丢失风险
解决思路
- 不写全数据,仅记录部分数据
- 改记录数据未记录操作过程
- 对所有操作均进行记录,排除丢失数据的风险
- 这也就是AOF的引入
AOF概念
- AOF持久化:以独立日志的方式记录每次写命令,重启时再重新执行AOF文件中命令达到恢复数据的目的。与RDB相比可以简单描述为改记录数据产生的过程
- AOF的主要作用是解决了数据持久化的实时性,目前已经是Redis持久化的主流方式
AOF写数据过程
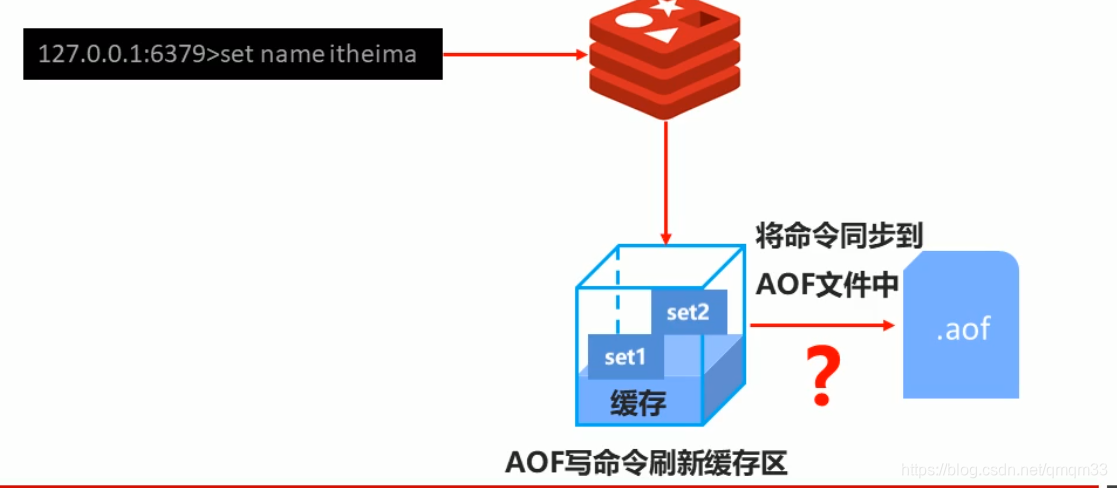
AOF写数据三种策略
- always(每次)
每次写入操作均同步到AOF文件中,数据零误差,性能较低 - everysec(每秒)
每秒将缓冲区中的指令同步到AOF文件中,数据准确性高,性能较高
再系统突然当即的情况下丢失1秒内的数据 - no(系统控制)
由操作系统每次同步到AOF文件的周期,整体过程不可控
AOF功能开启
- 配置
appendonly yes|no
- 作用
是否开启APF持久化功能,默认为不开启 - 配置
appendfsync always|everysec|no
- 作用
AOF写数据策略
AOF相关配置
- 配置
appendfilename filename
- 作用
AOF持久化文件名,默认文件名为appendonly.aof,建议配置为appendonly-端口号.aof - 配置
dir
- 作用
AOF持久化文件保存路径,与RDB持久化文件保持一致即可
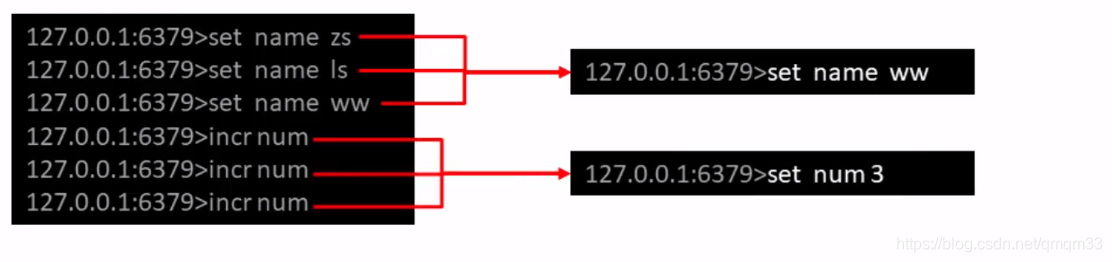
AOF写数据遇到的问题
如果连续执行如下指令该如何处理
AOF重写
随着命令的不断写入AOF,文件会越来越大,为了解决这个问题,Redis引入AOF重写机制压缩文件体积,AOF文件重写是将Redis进程内的数据转换为写命令同步到新AOF文件的过程,简单说就是将同样一个数据的若干个命令执行结果转换为最终结果数据对应的指令进行记录
AOF重写作用
- 降低磁盘占用量,提高磁盘利用路
- 提高持久化效率,降低持久化写时间,提高IO性能
- 降低数据恢复用时,提高数据恢复效率
AOF重写规则
- 进程内已超时的数据不再写入文件
- 忽略无效指令,重写时使用进程内数据直接生成,这样新的AOF文件只保留最终数据的写入命令
如del key1,hdel key2,srem key3,set key 222等 - 对统一数据的多条命令合并为一条命令
如 lpush list1 a ,lpush list1 b,lpush list1 c可以转化为lpush list1 a b c
为防止数据量过大造成客户端缓冲区溢出,对list,set,hash,set等类型,每条指令最多写入64个元素
AOF重写方式
- 手动重写
bgrewriteaof
- 自动重写
auto-aof-rewrite-min-size size
auto-aof-rewrite-percentage percentage
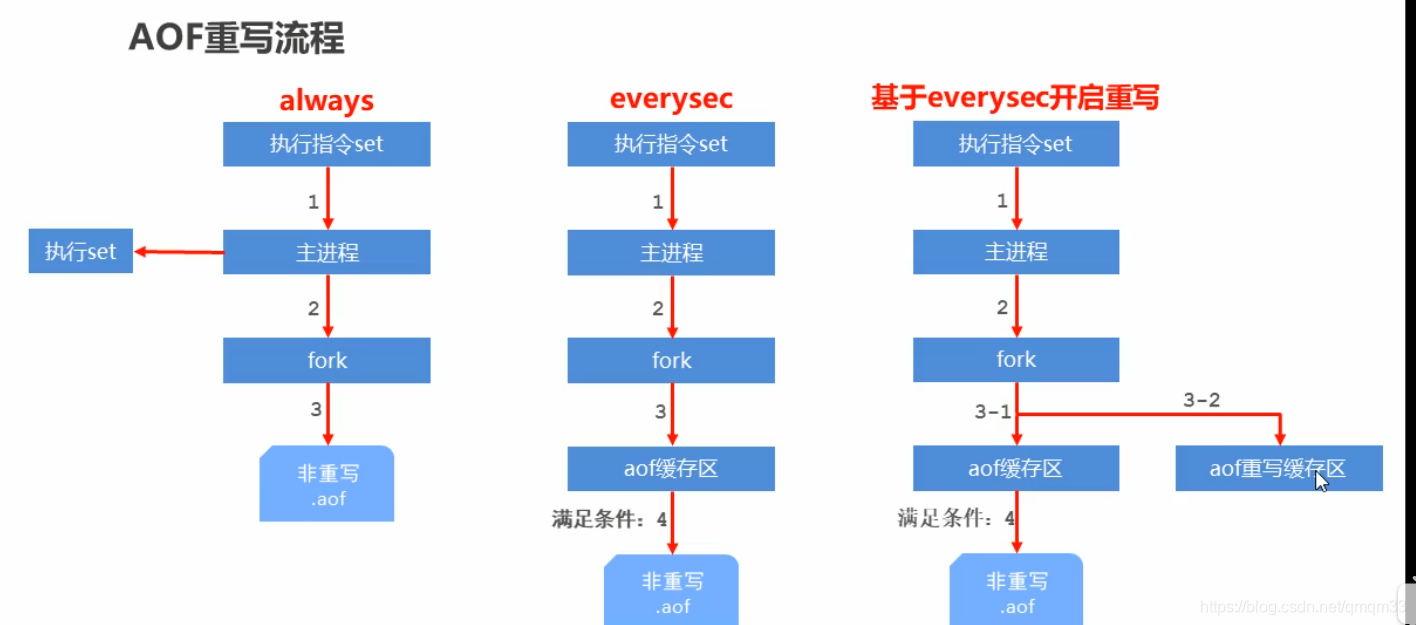
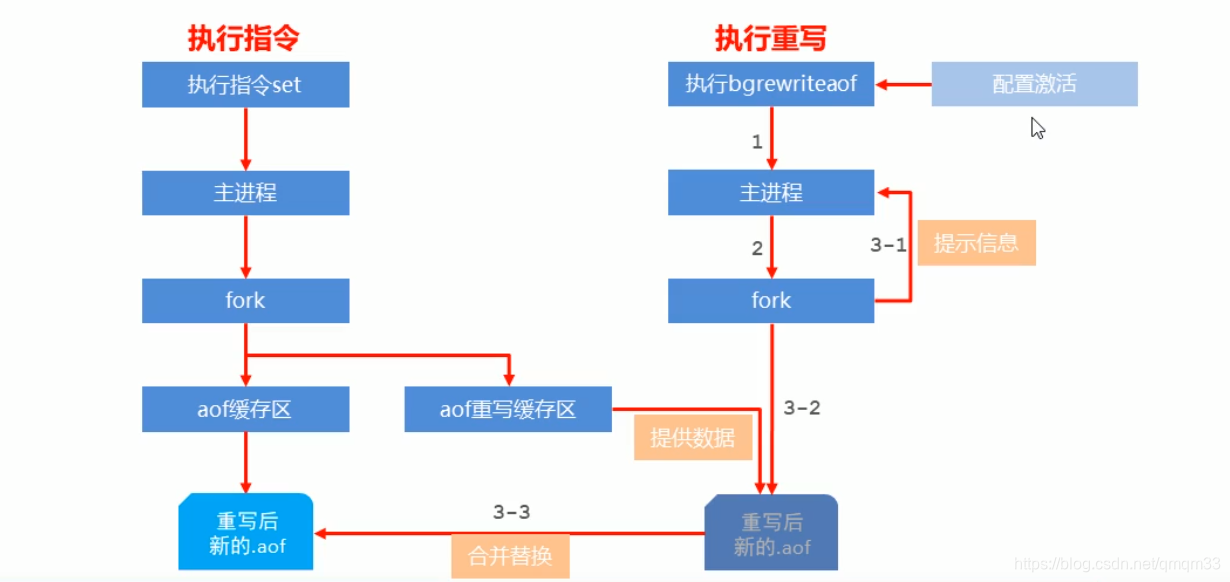
AOF手动重写——bgrewriteaof指令工作原理

AOF自动重写方式
- 自动重写触发条件设置
auto-aof-rewrite-min-size
auto-aof-rewrite-percentage percent
- 自动重写触发对比参数(运行指令info Persistence获取具体信息)
aof_current_size
aof_base_size
- 自动重写触发条件

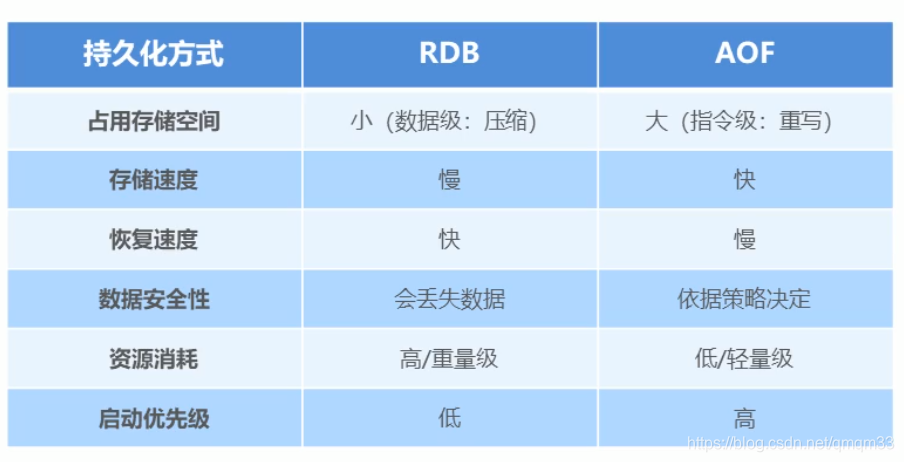
AOF和RDB的区别
RDB和AOF的选择之感
- 对数据非常敏感,建议使用默认的AOF持久化方案
AOF持久化策略使用erverysecond,每秒钟fsync一次。该策略redis任然可以保持很好的处理性能,当出现问题时,最多丢失0-1秒中的数据。
注意:由于AOF文件存储体积较大,且恢复数据较慢 - 数据呈现阶段有效性,建议使用RDB持久化方案
数据可以良好的做到阶段内无丢失(该阶段是开发者或运维人工手工维护的),且恢复速度较快,阶段点数据恢复通常采用RDB方案
注意:利用RDB实现紧凑的数据持久化会使Redis降得很低 - 综合对比
- RDB与AOF得选择实际上是在做一种权衡,每种都有利弊
- 如不能承受数分钟以内得数据丢失,对业务数据非常敏感,选用AOF
- 如能承受数分钟以内数据丢失,且追求大数据集得恢复速度,选用RDB
灾难恢复选用RDB - 双保险策略,同时开启RDB和AOF,重启后,Redis优先使用AOF来恢复数据,降低丢失数据的量
持久化应用场景

RDB存储的弊端
- 存储数据量较大,效率较低——基于快照思想,每次读写都是全部数据,当数据量巨大时,效率非常低
- 大数据量下的IO性能较低
- 基于fork创建子进程,内存产生额外消耗
- 宕机带来的数据丢失风险
解决思路
- 不写全数据,仅记录部分数据
- 改记录数据未记录操作过程
- 对所有操作均进行记录,排除丢失数据的风险
- 这也就是AOF的引入
AOF概念
- AOF持久化:以独立日志的方式记录每次写命令,重启时再重新执行AOF文件中命令达到恢复数据的目的。与RDB相比可以简单描述为改记录数据产生的过程
- AOF的主要作用是解决了数据持久化的实时性,目前已经是Redis持久化的主流方式
AOF写数据过程
AOF写数据三种策略
- always(每次)
每次写入操作均同步到AOF文件中,数据零误差,性能较低 - everysec(每秒)
每秒将缓冲区中的指令同步到AOF文件中,数据准确性高,性能较高
再系统突然当即的情况下丢失1秒内的数据 - no(系统控制)
由操作系统每次同步到AOF文件的周期,整体过程不可控
AOF功能开启
- 配置
appendonly yes|no
- 作用
是否开启APF持久化功能,默认为不开启 - 配置
appendfsync always|everysec|no
- 作用
AOF写数据策略
AOF相关配置
- 配置
appendfilename filename
- 作用
AOF持久化文件名,默认文件名为appendonly.aof,建议配置为appendonly-端口号.aof - 配置
dir
- 作用
AOF持久化文件保存路径,与RDB持久化文件保持一致即可
AOF写数据遇到的问题
如果连续执行如下指令该如何处理
AOF重写
随着命令的不断写入AOF,文件会越来越大,为了解决这个问题,Redis引入AOF重写机制压缩文件体积,AOF文件重写是将Redis进程内的数据转换为写命令同步到新AOF文件的过程,简单说就是将同样一个数据的若干个命令执行结果转换为最终结果数据对应的指令进行记录
AOF重写作用
- 降低磁盘占用量,提高磁盘利用路
- 提高持久化效率,降低持久化写时间,提高IO性能
- 降低数据恢复用时,提高数据恢复效率
AOF重写规则
- 进程内已超时的数据不再写入文件
- 忽略无效指令,重写时使用进程内数据直接生成,这样新的AOF文件只保留最终数据的写入命令
如del key1,hdel key2,srem key3,set key 222等 - 对统一数据的多条命令合并为一条命令
如 lpush list1 a ,lpush list1 b,lpush list1 c可以转化为lpush list1 a b c
为防止数据量过大造成客户端缓冲区溢出,对list,set,hash,set等类型,每条指令最多写入64个元素
AOF重写方式
- 手动重写
bgrewriteaof
- 自动重写
auto-aof-rewrite-min-size size
auto-aof-rewrite-percentage percentage
AOF手动重写——bgrewriteaof指令工作原理
AOF自动重写方式
- 自动重写触发条件设置
auto-aof-rewrite-min-size
auto-aof-rewrite-percentage percent
- 自动重写触发对比参数(运行指令info Persistence获取具体信息)
aof_current_size
aof_base_size
- 自动重写触发条件
AOF和RDB的区别
RDB和AOF的选择之感
- 对数据非常敏感,建议使用默认的AOF持久化方案
AOF持久化策略使用erverysecond,每秒钟fsync一次。该策略redis任然可以保持很好的处理性能,当出现问题时,最多丢失0-1秒中的数据。
注意:由于AOF文件存储体积较大,且恢复数据较慢 - 数据呈现阶段有效性,建议使用RDB持久化方案
数据可以良好的做到阶段内无丢失(该阶段是开发者或运维人工手工维护的),且恢复速度较快,阶段点数据恢复通常采用RDB方案
注意:利用RDB实现紧凑的数据持久化会使Redis降得很低 - 综合对比
- RDB与AOF得选择实际上是在做一种权衡,每种都有利弊
- 如不能承受数分钟以内得数据丢失,对业务数据非常敏感,选用AOF
- 如能承受数分钟以内数据丢失,且追求大数据集得恢复速度,选用RDB
灾难恢复选用RDB - 双保险策略,同时开启RDB和AOF,重启后,Redis优先使用AOF来恢复数据,降低丢失数据的量
持久化应用场景