最近频繁遇到生成环境CPU、内存告警、频繁FGC等问题,总结了一些排查思路,分享出来。
1、做好记录
有时候问题产生只是某段时间内,当你发现再去追踪时,可能已经恢复了,所以我们要提前写好一套脚本,当产生告警时能够立刻生成相关数据的快照信息,以便后续问题排查。
2、需要记录哪些信息
top
top命令可以反映系统整体的负载情况,特别是在查看CPU使用率时尤其重要
top -Hp pid
top直接查看的进程id,我们还需要根据进程id,查看里面具体的线程,分析到底是哪些线程占用cpu较高
jstack
jstack是java自带的命令,主要用于生成虚拟机当前时刻线程快照信息,用于跟踪并调试虚拟机堆栈信息,通过这个命令可以检测死锁、死循环、线程长时间停顿等问题。
netstat -natp
netstat命令可以监控网络连接的状态,查看tcp连接,以及每个连接的状态位。
lsof -p pid
lsof命令可显示系统打开的文件
jmap
jmap是java自带的内存映像工具,一般通过jmap可以生成堆的当前使用情况的快照,然后用它来分析或者调优JVM内存使用。
jmap -histo:live pid(查看对象信息)
jmap -heap pid(查看内存分配信息)
jmap -dump:format=b,file=文件名.phrof pid (生成内存的快照信息)
jmap的有些命令可能会触发gc,并且如果内存较大时,生成快照可能会造成较长时间的卡顿,系统正常运行时这些命令需慎重使用,使用时注意观察运行状态。
jstat
jstat -gcutil pid
同样也是java自带的命令,我们主要用来观察虚拟机在运行时垃圾收集状况
3、JVM启动参数
JVM启动时,有一些参数是必须要配置的,不然出了问题很难定位
日志类:
从GC日志中,可以看出每次GC前后的内存大小对比,从而帮助分析内存大小设置的合理性,以及是否有内存泄露等问题存在。
-XX:+PrintGCDetails(输出GC的详细日志)
-XX:+PrintGCDateStamps(输出GC的时间戳)
-Xloggc:/opt/xxx/logs/xxx-xxx-gc-%t.log(日志文件的输出路径)
OOM后生成快照:
产生OOM后,需要通过堆的快照分析具体导致OOM的原因。
-XX:+HeapDumpOnOutOfMemoryError (OOM时生成Dump文件)
-XX:HeapDumpPath=/memory.hprof(OOM文件生成地址)
JVM堆内存参数:
合理的堆内存配置,可以帮助减少FGC的次数和时长。
-Xmn(新生代大小,G1垃圾收集器一般不用设置)
-Xms (初始分配内存,默认为物理内存的1/64)
-Xmx (最大分配内存大小,默认为物理内存的1/4)
-XX:SurvivorRatio(Eden区和Survivor区比例,默认8:1:1)
默认空余堆内存小于40%时,JVM就会增大堆直到-Xmx的最大限制;空余堆内存大于70%时,JVM会减少堆直到 -Xms的最小限制。
因此服务器一般设置-Xms、-Xmx相等以避免在每次GC后调整堆的大小。调大导致FGC时间变长,调小又会导致FGC频繁。
4、CPU100%排查
- 1、top命令找到使用cpu较高的进程id
- 2、top -Hp 进程id,找到进程中使用cpu较高的线程,这时候有可能是单个线程使用率高,也有可能是单个线程使用率低,但是线程数量超多。
- 3.1、如果是单个线程使用率高,则可直接找到对应线程,通过jstack 进程id,匹配对应线程id(jstack 线程id显示的是16进制,匹配时需转成16进程查询),通过线程栈的上下文信息,基本上可以分析出异常的原因了(自己写的业务代码还看不懂嘛!)。
- 3.2、如果是线程数量多,一般可以导出jstack文件后,进行统计分类分析,大多数都是线程池使用不当造成的(包括业务用到的线程池和tomcat等web容器用到的线程池)。
线程多,线程池没控制造成的。
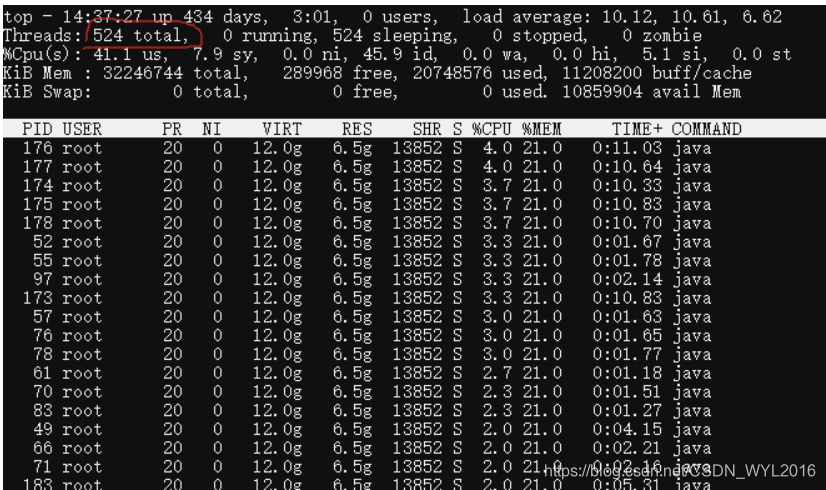
单个高
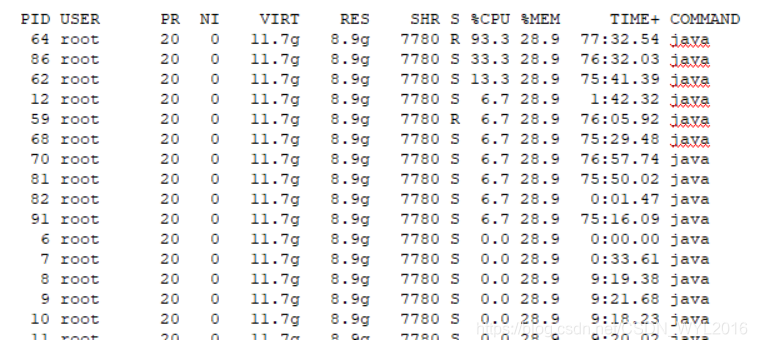
PID64,转成16进制就是0x40
这个一看就是json序列化造成的,一次性序列化对象太多

5、FGC频繁
- 1、关于FGC频繁并没有一个特定的数值去衡量,需要结合实际情况去进行优化。
- 2、一般情况下,可以结合垃圾回收的日志进行分析,这里又可以分几种情况。
- 2.1、每次回收的垃圾很少,这就有可能产生内存泄漏的问题。
- 2.2、每次能回收很多对象,但是很快就又满了,如果这种情况是常态,那么可能真的是你的服务器内存太小的。
- 2.3、如果2.2问题不是常态,那么很有可能是频繁产生了大对象(直接进入老年代的对象)。
- 2.4、现在一般都使用JDK1.8,那么默认是PS垃圾收集器,这款垃圾收集器一定要配置S区和E区的比例,如果会造成新生代对象提前进入老年代。具体问题可以参考这篇文章:记录一次使用ParallelGC导致线上FGC频繁、耗时长的原因
- 3、不管是上面哪种情况,一般都可以通过打印内存快照、垃圾日志、MAT等工具进行分析,找到前几个占用内存最多的对象进行追踪即可。
6、YGC频繁
有时候总是关于FGC是否正常,忽视了YGC的情况,有些特定的场景,YGC也是可以优化的
比如系统遇到突发流量时,最熟悉的就是秒杀之类的场景了,这种情况可能会造成YGC频繁,因为会大量的产生很多新对象,此时可以适当调整新生代的占比,以此YGC的次数,当然你可能会觉得新生代大了,自然一次YGC的时间也长了,所以这个值是需要你通过实际压测后确定的,并不能凭空YY,这篇文章可以作为参考:JVM调优实战系列—堆内存分配优化
7、OOM
最后一点,关于OOM,分析的思路实际和FGC差不多,最主要的就是要得到内存快照,通过MAT工具可以帮助我们进行分析。
最后注意搞清楚到底是内存泄漏还是内存溢出。
内存泄漏是问题
内存溢出不一定是问题,随着业务的发展,有可能是当前的服务器配置该升级了。
8、总结
总之,在分析线上问题时,一定要注意保存好事故现场,完整的现场信息更有利用后续问题的分析,然后尽快重启服务(重启有时候真的非常管用),一般情况下重启后还是可以继续运行一段时间。