1.如何在Python中管理内存?
(1)python中的内存管理由Python专用堆空间管理。所有Python对象和数据结构都位于私有堆中。程序员无权访问此私有堆。python解释器代替了它。
(2)Python对象的堆空间分配是由Python的内存管理器完成的。核心API允许访问一些工具,以便程序员进行编码。
(3)Python还具有一个内置的垃圾收集器,该垃圾收集器回收所有未使用的内存,并使其可用于堆空间。
2.什么是python模块?命名Python中一些常用的内置模块?
回答:Python模块是包含Python代码的文件。此代码可以是函数类或变量。Python模块是包含可执行代码的.py文件。
一些常用的内置模块是:
操作系统
系统
数学
随机
资料时间
JSON格式
3.什么是Python中的类型转换?举例说明
回答:类型转换是指将一种数据类型转换为另一种数据类型。
int()–将任何数据类型转换为整数类型
float()–将任何数据类型转换为float类型
ord()–将字符转换为整数
hex()–将整数转换为十六进制
oct()–将整数转换为八进制
tuple()–此函数用于转换为元组。
set()–此函数在转换为set后返回类型。
list()– 此函数用于将任何数据类型转换为列表类型。
dict()– 此函数用于将顺序(键,值)的元组转换为字典。
str()– 用于将整数转换为字符串。
4.什么是__init__?
回答:__init__是Python中的方法或构造函数。创建类的新对象/实例时,将自动调用此方法以分配内存。所有类都具有__init__方法。
这是一个如何使用它的例子。

输出:
XYZ
23
20000
5. [::-1}是做什么的?
Ans:[::-1]用于反转数组或序列的顺序。
例如:

输出:array('i',[5,4,3,2,1])
[::-1]重印有序数据结构(例如数组或列表)的反向副本。原始数组或列表保持不变。
6.您如何在Python中将列表项随机化?
答:请看下面的例子:
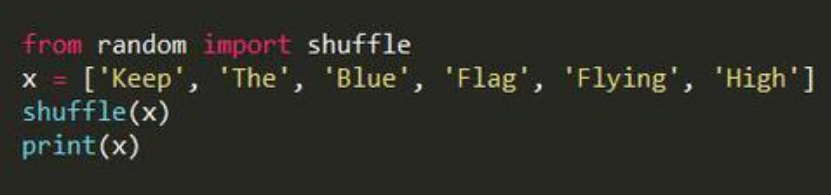
以下代码的输出如下。
[“Flying”,“Keep”,“Blue”,“High”,“ The”,“Flag”]
7.range和xrange有什么区别?
回答:就功能而言,在大多数情况下,xrange和range完全相同。它们都提供了一种生成整数列表供您使用的方法,但是您可以随意使用。唯一的区别是range返回一个Python列表对象,而x range返回一个xrange对象。
这意味着xrange在运行时实际上不会像range那样生成静态列表。它通过一种称为yield的特殊技术根据需要创建值。该技术与一种称为生成器的对象一起使用。这意味着,如果您有一个非常庞大的范围,您想生成一个列表,例如十亿,则使用xrange函数。
如果您有一个真正的内存敏感系统(例如正在使用的手机),则尤其如此,因为range将使用尽可能多的内存来创建整数数组,这可能导致内存错误并使您的崩溃程序。这是一个渴望记忆的野兽。
8.Python中help()和dir()函数的用法是什么?
回答:Help()和dir()这两个函数均可从Python解释器访问,并用于查看内置函数的合并转储。
(1)Help()函数:help()函数用于显示文档字符串,还可以帮助您查看与模块,关键字,属性等有关的帮助。
(2)Dir()函数:dir()函数用于显示定义的符号。
9.解释Python中“ re”模块的split(),sub(),subn()方法。
回答:为了修改字符串,Python的“ re”模块提供了3种方法。他们是:
(1)split()–使用正则表达式模式将给定的字符串“拆分”为列表。
(2)sub()–查找所有正则表达式模式匹配的子字符串,然后将其替换为其他字符串
(3)subn()–它类似于sub(),还返回新字符串以及替换的数目。
10.什么是负索引,为什么要使用它们?
回答:Python中的序列已编入索引,并且由正数和负数组成。正数使用“ 0”作为第一个索引,使用“ 1”作为第二个索引,过程继续进行。
负数的索引从代表序列中最后一个索引的“ -1”开始,而倒数第二个索引则是“ -2”,并且该序列像正数一样向前发展。
负索引用于从字符串中删除所有换行符,并允许字符串除以S [:-1]给出的最后一个字符外。负索引还用于显示索引以正确的顺序表示字符串。
11.Python是否具有OOps概念?
回答:Python是一种面向对象的编程语言。这意味着可以通过创建对象模型在python中解决任何程序。但是,Python既可以作为过程语言,也可以作为结构语言。
12.深层复制和浅层复制有什么区别?
回答:创建新实例类型时,将使用浅表复制,并将其复制的值保留在新实例中。浅复制用于复制参考指针,就像复制值一样。这些引用指向原始对象,并且在类的任何成员中所做的更改也会影响其原始副本。浅拷贝允许更快地执行程序,并且取决于所使用的数据大小。
深度复制用于存储已复制的值。深层复制不会将引用指针复制到对象。它引用一个对象,并存储其他对象指向的新对象。在原始副本中所做的更改不会影响使用该对象的任何其他副本。由于为每个被调用的对象制作了某些副本,因此深层复制会使程序的执行速度变慢。