首先
建立一个类就是建立了一个模型,调用一般方法,就是对这个模型复制,复制产生的变量叫做这个类的对象。
我们对类的对象进行操作,不会改变原来的模型
而对类操作,不仅改变类,还会改变所有的对象
先看代码,后解释
class A(object):
a = 'a'
@classmethod
def repeat_a(cls, times=1):
cls.a=cls.a * times
foo1=A()
print('foo1.a:',foo1.a)
foo = A()
foo.repeat_a(2)
print('foo1.a:',foo1.a)
foo.repeat_a(3)
print('foo1.a:',foo1.a)
输出为: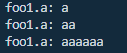
foo1.a的值没变
class A(object):
a = 'a'
def repeat_a(self, times=1):
self.a=self.a * times
foo1=A()
print('foo1.a:',foo1.a)
foo = A()
foo.repeat_a(2)#aa
print'foo.a:',(foo.a)
foo.repeat_a(3)
print('foo1.a:',foo1.a)
输出为:
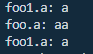
foo1.a的值没变
解释:
@classmethod修饰的第一个函数的参数只能是 cls 也就是class,是呆代指这个类本身!,我们进行的操作是对这个模型进行修改,会影响每一个已经被创建的对象!
而一般方法的第一个函数参数是self,是这个类的对象,是复制模型 产生的复制体,对其操作并不会影响类和其他对象
自己画了下面的图,方便理解

但是,假如对象的属性已经被重新被赋值,那么就该属性就不会被影响
class A(object):
a = 'a'
b='b'
@classmethod
def repeat_a(cls, times=1):
cls.a=cls.a * times
cls.b=cls.b * times
foo1=A()
print('foo1.a:',foo1.a)
print('foo1.b:',foo1.b)
foo1.a='zzz'#被赋值
foo = A()
foo.repeat_a(2)
print('foo1.a:',foo1.a)
print('foo1.b:',foo1.b)
输出为:
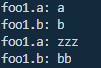
对象的属性a被重新赋值,就不会被影响,而对象的属性b未被重新赋值,就会受到影响
@staticmethod
我觉得最好理解
就是,一般的函数,只不过被放在了类的里面,调用的时候多大几个字符
class A(object):
@staticmethod
def pow(x):
return x*x
a=A()
print(a.pow(2))
没有对象或者类被传进去,就是一个放在类里面的普通函数