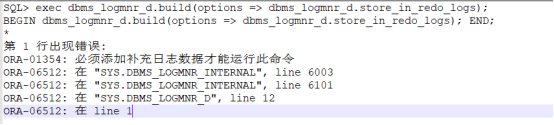
这种方法必须启动supplemental log,否则会报ORA-01354错误,如下
使用DICT_FROM_REDO_LOGS方式,进程会将数据库的数据字典信息抽取到online redo log里去,如果数据库的数据字典较大,或者redo log太小,或者DML操作较频繁,就有可能在抽取数据字典信息时发生日志切换操作。利用这种方式可以使用其他数据库(测试数据库)来分析生产库的归档日志信息,需要将包含所有数据字典信息的归档日志和需要分析归档日志一起发送到其他数据库(测试服务器),以减少直接在生产库上操作对生产数据库带来的压力。
1.查看数据库是否打开最小补充日志
| select SUPPLEMENTAL_LOG_DATA_MIN,SUPPLEMENTAL_LOG_DATA_PK,SUPPLEMENTAL_LOG_DATA_UI from v$database; |

2.创建测试表
| create table logmnr_test(id number,name varchar2(10)); insert into logmnr_test values(1,'stream'); insert into logmnr_test values(2,'dbdream'); commit;
扫描二维码关注公众号,回复:
12899677 查看本文章

update logmnr_test set name='streamsong' where name='stream'; commit; |
3.将数据字典抽取到联机日志
| exec dbms_logmnr_d.build(options => dbms_logmnr_d.store_in_redo_logs); |
4.查看日志信息
| set line 300 col NAME format a80 select RECID,NAME,DICTIONARY_BEGIN,DICTIONARY_END from v$archived_log; |
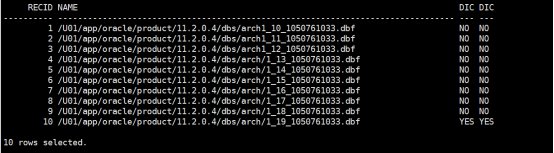
DICTIONARY_BEGIN表示开始抽取数据字典,DICTIONARY_END表示数据字典抽取完成,也就是数据字典信息包含在DICTIONARY_BEGIN状态是YES和DICTIONARY_END状态是YES的日志文件内。
5.归档日志上传到测试服务器
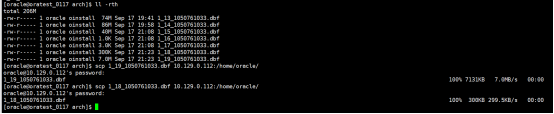
6.添加日志
测试服务器没有过多要求,不需要打开归档模式,只要OPEN就可以分析。
| exec dbms_logmnr.add_logfile(logfilename=>'/home/oracle/1_18_1050761033.dbf',options=>dbms_logmnr.new); exec dbms_logmnr.add_logfile(logfilename=>'/home/oracle/1_19_1050761033.dbf',options=>dbms_logmnr.addfile); |
7.开始分析
| execute dbms_logmnr.start_logmnr(options =>dbms_logmnr.dict_from_redo_logs); |
8.查看分析
| select timestamp,sql_redo from v$logmnr_contents where table_name='LOGMNR_TEST'; |

DICT_FROM_REDO_LOGS模式相对用的比较广泛,比如客户需要帮他们看下4天之内一条记录的修改情况,客户的数据库又没有设置UTL_FILE_DIR参数,就可以用这种方法把数据字典抽取到日志文件中,然后客户只需要将包含数据文件的日志和分析时间段的日志发给我就可以了,而不需要设置UTL_FILE_DIR参数和重启数据库。