最近公司需要拉取一组数据,需求是查出每个会员消费订单中按照消费时间排序的倒数第二个订单的消费时间。
例如某个顾客在今年5月份、6月份、7月份、8月份分别消费了一笔订单,消费时间分别为2020-5-1、2020-6-1、2020-7-1、2020-8-1,则查找出7月份的那笔订单的消费时间2020-7-1
sql语句如下:
select o.member_id ,
substring_index(substring_index(group_concat(o.begin_date order by o.begin_date desc),',',2),',',-1) as 倒数第二次消费时间
from `order` o
group by o.member_id
having (count(o.member_id) >= 2)
查询结果:
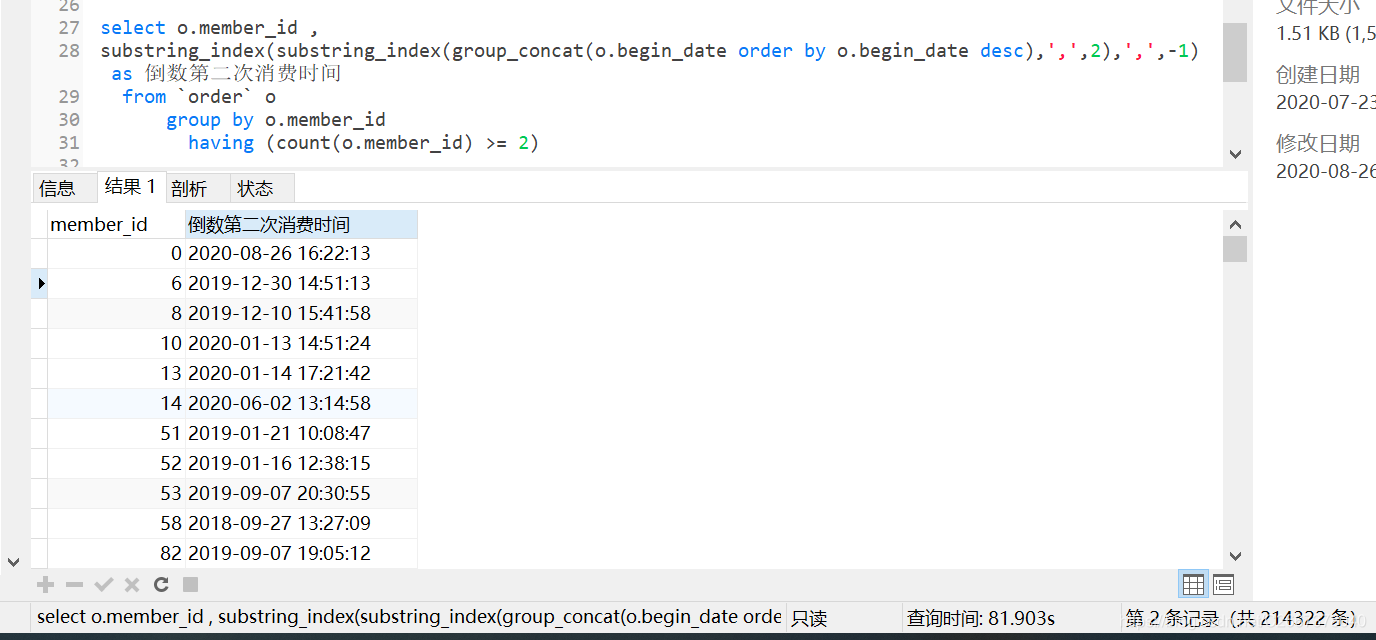
结果显示member_id = 6 的会员倒数第二次消费时间为2019-12-30 14:51:13,我们看一下编号member_id = 6 的会员的消费情况验证一下:

member_id = 6 的会员倒数第二次消费时间确实为2019-12-30 14:51:13。
如有有显示整条数据的需求只需要添加上对应字段即可,我这里添加了订单id(o.id)与订单金额(o.actual_amount)

至此大功告成!
理解不了sql的小伙伴可以看一下下面的内容
例如某个顾客在今年5月份、6月份、7月份、8月份分别消费了一笔订单,消费时间分别为2020-5-1、2020-6-1、2020-7-1、2020-8-1
1、首先将订单表(order)中所有订单按照会员的编号(member_id)进行分组,并且使用过滤条件count(o.member_id) >= 2确保所查询到的会员消费订单都在2笔及以上
2、然后再使用函数group_concat将每组数据中多条数据的消费时间倒序之后(begin_date)进行合并,合并后的消费时间为2020-8-1、2020-7-1、2020-6-1、2020-5-1
3、接着使用函数substring_index截取倒序之后的消费时间的前两条,截取后的消费时间为2020-8-1、2020-7-1
4、最后再使用一次substring_index截取两条中的第二条,截取后的消费时间为2020-7-1
这样就能够查询分组后每组数据中按照时间排序的倒数第二条数据
group_concat与substring_index的用法我参考的以下两位博主的博客,感谢!不会使用的小伙伴也可以参考一下
group_concat:
https://blog.csdn.net/u012620150/article/details/81945004
substring_index:
https://blog.csdn.net/iris_xuting/article/details/38415181
希望我的分享能对你的工作和学习有所帮助O(∩_∩)O