Kotlin协程解析
协程是什么
-
协程是什么?
- 协程是一种在程序中处理并发任务的⽅案,也是这种⽅案的一个组件。
- 它和线程属于一个层级的概念,是一种和线程不同的并发任务解决⽅案:一套系统(可以是操作系统,也可以是一种编程语⾔)可以选择不同的⽅案来
处理并发任务,你可以使⽤线程,也可以使⽤协程。
-
Kotlin的协程是什么?
- Kotlin 的协程(确切说是 Kotlin for Java 的协程)是一个线程框架,其实本质上与AsyncTask(已废弃)和Executor(Java)没有什么区别
简单的例子
launch{
val user = api.getUser() // 网络请求(IO 线程)
nameTv.text = user.name // 更新 UI(主线程)
}
这个例子是一个简单的协程片段,值得注意的是, 上述代码中的launch并不是一个顶层函数,所以不能直接将这段代码拿过来用,这里只关心他内部业务逻辑的写法,具体怎么用,后面会详细说明
根据以上的代码,launch函数加上一对{}就构成了一个协程(通常协程的开启方法都是launch)
这里的api.getUser是一个挂起函数,这涉及到了协程的非阻塞式挂起,至于这个非阻塞式挂起,后面会说
像上面这种方法名+大括号的形式,是Kotlin的语法糖,launch是一个方法
它接收的参数是一个lambda表达式:launch({})
这个lambda表达式由于是launch方法的最后一个参数,所以可以放到小括号的外面写 launch(){}
如果lambda是方法的唯一参数,就可以把小括号省略了: launch{}
协程初体验
基本使用
依赖:
implementation 'org.jetbrains.kotlinx:kotlinx-coroutines-core:1.3.8'
implementation 'org.jetbrains.kotlinx:kotlinx-coroutines-android:1.3.8'
简单使用
// 方法一,使用 runBlocking 顶层函数
runBlocking {
getImage(imageId)
}
// 方法二,使用 GlobalScope 单例对象
// 可以直接调用 launch 开启协程
GlobalScope.launch {
getImage(imageId)
}
// 方法三,自行通过 CoroutineContext 创建一个 CoroutineScope 对象
val job = Job()
// 这里的CoroutineScope是一个方法,并不是一个对象
val coroutineScope = CoroutineScope(job)
coroutineScope.launch {
getImage(imageId)
}
- 方法一通常适用于单元测试的场景,而业务开发中不会用到这种方法,因为它是线程阻塞的。就是他会阻塞开启协程的那个线程
- 方法二和
runBlocking的区别在于不会阻塞线程,但是在Android中不推荐使用这种方法,因为他的生命周期会与进程一致,而且不能取消 - 方法三可以用,属于手动开启线程中最常用的方法
但是实际上在Android项目中,上述的三种方式我们大概率都不会选择…但是他们又足够简单,可以让我们先对协程有一个大致的概念,方便理解下面的部分
创建协程
在kotlin中,我们在绝大部分情况下都是用launch函数来创建协程,但其实还有两个其他的函数也可以用来创建协程
- runBlocking
- async
runblocking:它会阻塞当前的线程,适用情况有两种(使用的比较少):
- 单元测试,它会让测试的线程卡主,防止测试代码还没有跑完,主线程就停止了
- 部分Java的Api,有时候第三方的Java库会给我们提供一个运行在子线程的方法,并且需要我们提供返回值,此时就可以利用runblocking来开启一个协程,来调用我们的获取数据的
挂起函数
那么我们主要使用的就是launch和async这两个函数:
- 相同点:他们都可以用来启动一个协程
- 不同点: async的返回值Coroutine多实现了Deferred接口,让我们可以从这个协程中获取返回值
比如如下代码:
coroutineScope.launch(Dispatchers.Main) {
// async 函数启动新的协程
val avatar: Deferred = async {
api.getAvatar(user) } // 获取用户头像
val logo: Deferred = async {
api.getCompanyLogo(user) } // 获取用户所在公司的 logo
// 获取返回值
handle(avatar.await(), logo.await()) // 处理他们的结果
}
这段代码如果用Java写起来就不是很容易。。。
小结
根据以上的概念, 对协程会有一个大概的了解:
- 协程的本质就是一个线程切换框架,帮助我们方便的切换线程
- 协程比其他的线程框架的优势在于:
- 能够以看起来并行的代码,实现异步操作,从而避免多层的回调
- 通过async函数,可以让我们更容易的写出多任务并发的代码
更深入一些
作用域
所有的协程,必须在一个作用域中开启
比如如下的代码:
GlobalScope.launch {
// 这里是协程
}
上面的launch方法就是开启一个协程,他对应的作用域是GlobalScope,GlobalScope是一个单例对象:
public object GlobalScope : CoroutineScope {
/**
* Returns [EmptyCoroutineContext].
*/
override val coroutineContext: CoroutineContext
get() = EmptyCoroutineContext
}
在最早版本的协程中,是没有作用域的的概念的,那时候启动协程,只需要调用launch函数即可
fun requestSomeData() {
launch {
// 随时随地启动协程
updateUI(performRequest())
}
}
就跟启动线程是一样的,但是这种方式启动的协程,没有办法管理,比如在Activity中启动协程访问网络数据,但是此时用户销毁了这个页面,但是由于没有办法管理,所以实际上网络请求还在继续,所有现在的协程必须运行在一个作用域中,而我们也可通过操作作用域来管理这个域下的所有线程
按照我自己目前的理解,作用域可以对应着Java中的线程池,协程就是线程池中的task, 我们可以通过关闭线程池来让其中的所有task统一的被关闭,就好像是我们通过操作作用域来取消这个域下的所有协程一样
有了以上的概念,我们就可以理解为什么不推荐使用GlobalScope了, 因为它是一个单例的作用域, 所以他的生命周期与整个进程是一样的, 相当于无法管理,而我们推荐使用的CoroutineScope则由于是我们构建出来,所以我们可以单独的操作这个Scop来管理这个域下的所有线程
CoroutineScope
CoroutineScope实际上并不是一个类,而是一个方法, 实际上通过这个方法构建出来的是ContextScope对象
public fun CoroutineScope(context: CoroutineContext): CoroutineScope =
ContextScope(if (context[Job] != null) context else context + Job())
这个地方知不知道并没有什么影响
尝试在Android中使用协程
有了以上的概念:
- 所有的协程都需要在一个作用域中使用
- 相较于
GlobalScop,我们更应该使用CoroutineScope来启用协程 - 在作用域下,我们可以通过launch和async函数启用协程
我们很容易写出这样的代码:
class MainActivity : AppCompatActivity() {
private val job = Job()
private val scope = CoroutineScope(job)
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
scope.launch {
// 这里是协程(子线程)
}
scope.launch {
// 这里是协程(子线程)
}
}
override fun onDestroy() {
job.cancel()
super.onDestroy()
}
}
当然,我们将scope和job封装到基类中,就可以在所有Activity的子类中自由的使用协程了
线程的切换
默认我们开启的协程,都是运行在子线程中的,我们也可以通过指定调度器来告诉协程要运行在哪个线程中:
scope.launch(Dispatchers.IO) {
// 这里是协程(子线程)
}
scope.launch(Dispatchers.Main) {
// 这里是协程(主线程)
}
比如我们要在子线程请求数据,然后在主线程更新UI,结合以上的知识,我们很容易写出如下的代码
scope.launch(Dispatchers.IO) {
// 这里是协程(子线程)
val data = getNetData()
launch(Dispatchers.Main) {
// 这里是主线程
updateUI(data)
}
}
看起来跟想象的不一样…
如果我们只用launch函数, 协程并不能比线程做更多的事情,不过协程还提供了一个很实用的函数:
withContext,这个函数可以通过制定调度器,自动的切换到指定线程,比如上面的代码可以写成:
scope.launch(Dispatchers.Main) {
// 这里是协程(子线程)
val data = withContext(Dispatchers.IO) {
// 子线程
getNetData()
}
// 主线程
updateUI(data)
}
看起来差别不大,但是如果我们的工作需要频繁的切换线程,就不一样了:
coroutineScope.launch(Dispatchers.IO) {
...
launch(Dispatchers.Main){
...
launch(Dispatchers.IO) {
...
launch(Dispatchers.Main) {
...
}
}
}
}
// 通过第二种写法来实现相同的逻辑
coroutineScope.launch(Dispatchers.Main) {
...
withContext(Dispatchers.IO) {
...
}
...
withContext(Dispatchers.IO) {
...
}
...
}
由于可以自动来回切换,所以可以消除代码在写作时的嵌套
suspened
suspened被称为挂起,它可以用来修饰方法,添加了suspend关键字的方法通常被称为挂机函数
为什么需要挂起函数
接上面的例子, 如果我们想把耗时操作封装到一个函数中,我们大概会写出这样的代码:
scope.launch(Dispatchers.Main) {
// 这里是协程(子线程)
val data = getNetData()
// 主线程
updateUI(data)
}
private fun getNetData(): String {
val data = withContext(Dispatchers.IO){
delay(1000)//模拟耗时
"Hello"
}
return data
}
但是当我们这样写了之后,编译器就会报错:
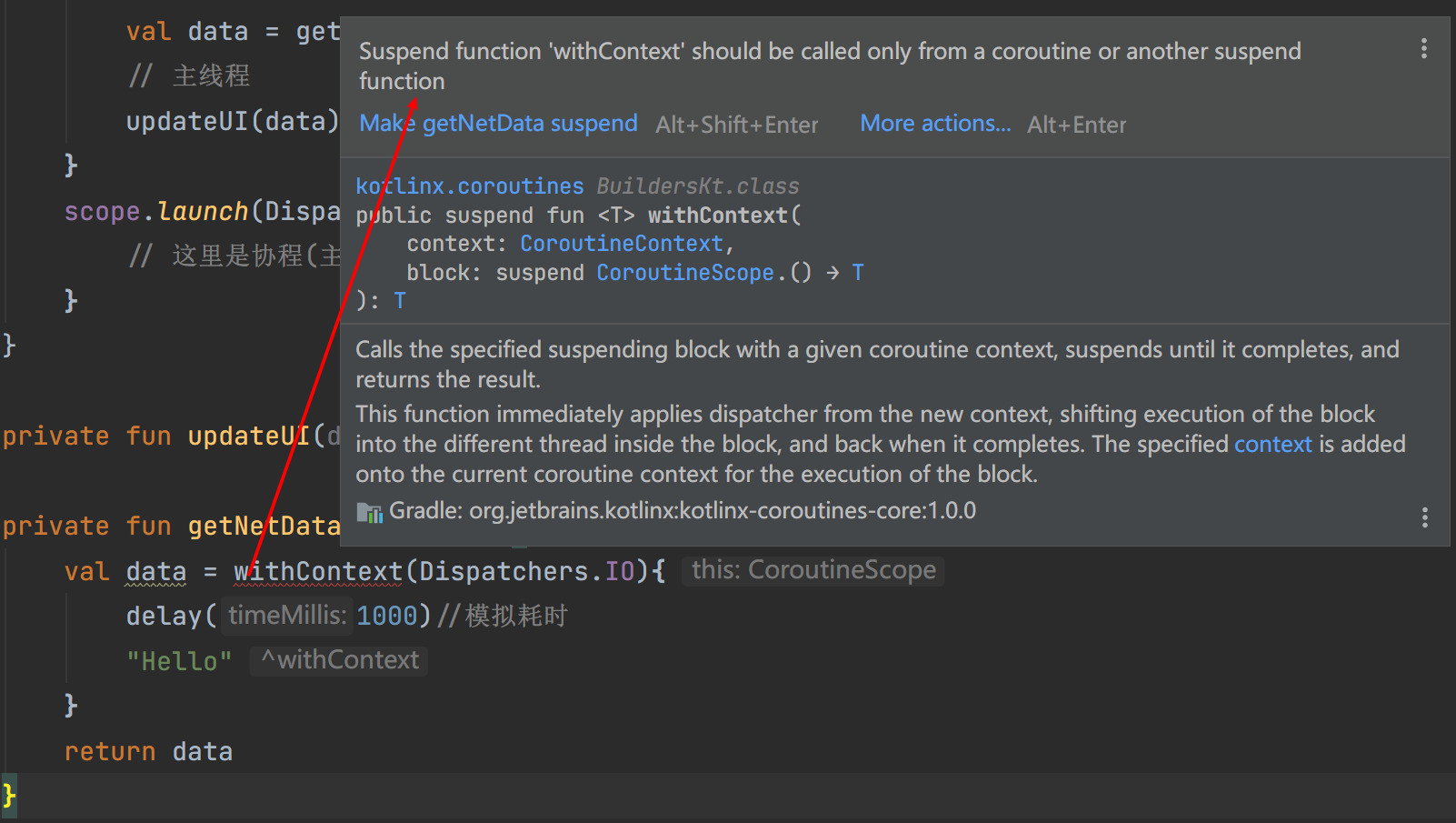
意思是说,withContext是一个suspend函数, 它需要在协程中或者另一个suspend函数中被调用,
实际上这句话的意思是, 所有标记了
suspend的函数必须直接或间接的在协程中使用
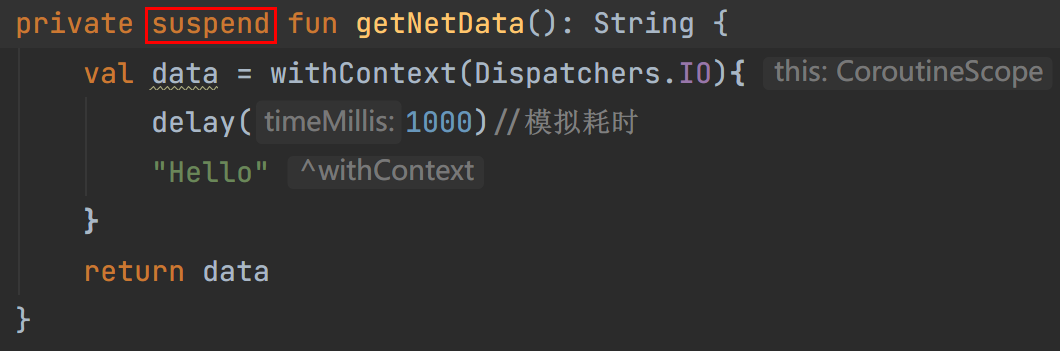
上面的代码,我们只需要添加上suspend关键字,就能正常编译并运行了:
挂起的本质
我们启动一个协程可以使用launch或者async函数, 而协程其实就是这两个函数的代码块,当协程执行到一个suspend函数的时候,这个协程就会被suspend,就是会被从当前线程挂起.换句话说,就是这个协程从正在执行他的线程上脱离
为了理解这个问题,我们会站在不同的视角来分别看看脱离的线程和协程都会分别做什么
线程
首先我们要牢记: 协程(在Android中)就是一个线程框架,比如以下代码:
scope.launch(Dispatchers.Main) {
initSomeThing()
val data = getNetData()
updateUI(data)
}
launch函数开启了一个协程,由于调度器指定为Dispatchers.Main,所以这个协程目前是运行在主线程上的
可以简单粗暴的理解为, launch代码块中相当于一个Runnable,通过handler.post()方法放到了主线程运行
所以协程代码块中的代码首先执行了initSomeThing()方法,此时协程还是运行在主线程上的
然后,主线程执行到suspend函数这里的时候,就暂时不再执行剩余的协程代码块,而是跳出了协程的代码块,那么接下来线程会做什么呢?
- 如果它是主线程(本例)
- 继续刷新UI
- 如果他是一个子线程
- 无事可做
那么launch包裹的剩下代码怎么办?
协程
线程的代码在到达 suspend 函数的时候被掐断,接下来协程会从这个 suspend 函数开始继续往下执行,不过是在指定的线程。
谁指定的?是 suspend 函数指定的,比如我们这个例子中,函数内部的 withContext 传入的Dispatchers.IO 所指定的 IO 线程。
Dispatchers 调度器,它可以将协程限制在一个特定的线程执行,或者将它分派到一个线程池
就是说我们的协程,此时从主线程脱离出来后,继续在Dispatchers所指定的IO线程中运行,接着suspend函数执行完成后, 协程会自动帮我们把线程再切回来
小结
协程在执行到有 suspend 标记的函数的时候,会被 suspend 也就是被挂起,而所谓的被挂起,就是切个线程;
不过区别在于,挂起函数在执行完成之后,协程会重新切回它原先的线程。
再简单来讲,在 Kotlin 中所谓的挂起,就是一个稍后会被自动切回来的线程调度操作。
非阻塞式挂起
看协程的时候, 都在说协程的suspend(挂起)是非阻塞式的, 其实因为协程会自动的在多个线程之间切换,所以肯定就不是阻塞式的,我们自己用handler切也是非阻塞式, 而协程的意义在于用单线程阻塞式的写法,实现了非阻塞的功能
Android中的实战
上面基本上把我所掌握的 关于协程概念都说过了一遍, 这一部分着重讲一下我在Android中关于使用协程上的一些写法
调度器
在Android中常见的Dispatchers有以下三种:
- Dispatchers.Main: Android中的主线程
- Dispatcher.IO: 针对磁盘和网络IO进行了优化,适合IO密集型的任务,比如:读写文件,操作数据库以及网络请求
- Dispatchers.Default: 适合CPU密集型的任务,比如计算
scope的选择
在Android中,建议两种scope:
1. lifecycleScope
lifecycleScope是在Androidx扩展库中的:
dependencies {
implementation 'androidx.lifecycle:lifecycle-runtime-ktx:2.2.0'
}
这个扩展库会被各种lifecycler依赖,所以一般都会很容易的集成到项目中
使用的时候:
lifecycleScope.launch {
// 这里是主线程
}
-
优点:
是不需要关系协程的取消, scope和生命周期绑定在一起, 当Activity/fragment被销毁后, 这个scope会自动的调用cancle方法,将内部的协程都取消掉 -
缺点:
只能在实现了LifecycleOwner接口的类中使用
MainScope
MainScope相当于指定了默认调度器为Dispatchers.Main的scope
val scope = MainScope()
scope.launch {
}
优点: 比lifesyclerScope更加灵活, 可以在Activity/Fragment中开启多个scope,分别管理
缺编: 需要在合适的时机手动调用cancle方法
调度器
常用的 Dispatchers ,有以下三种:
- Dispatchers.Main:Android 中的主线程
- Dispatchers.IO:针对磁盘和网络 IO 进行了优化,适合 IO 密集型的任务,比如:读写文件,操作数据库以及网络请求
- Dispatchers.Default:适合 CPU 密集型的任务,比如计算
写协程的建议
由于协程可以自动的将耗时操作放到子线程中, 并在执行完成后再切回来,所以 建议在开启协程时,指定Dispatchers.Main, 然后将所有的耗时操作方法都放到Dispatchers.IO或Dispatchers.Default的线程中,这样可以在耗时操作执行完成后,自动切回主线程更新UI
suspened
什么时候给方法添加suspened关键字: 只要这个方法是耗时的,就给这个方法添加上suspened关键字, 然后在方法内根据情况使用withContext函数切换到子线程去, 这也可以保证别人在用你的方法的时候, 编译器会自动警告他,这是一个耗时方法, 需要放到协程中去执行
一些例子:
1. scope的封装
如果使用的MainScop, 我们可以通过以下代码在基类中封装:
abstract class BaseActivity : AppCompatActivity(), CoroutineScope by MainScope() {
override fun onDestroy() {
cancel()
super.onDestroy()
}
}
思路是让BaseActivity通过MainScope的代理来实现CoroutineScope接口,这样就可以在BaseActivity的子类中,直接使用launch函数来开启一个运行在主线程的协程
override fun onCreate(savedInstanceState: Bundle?, persistentState: PersistableBundle?) {
super.onCreate(savedInstanceState, persistentState)
launch {
// 这里是主线程
}
}
同时由于在onDestroy方法中调动了cancel方法,所以子类在使用协程的时候不需要再关注协程的取消了
2. lifecycleScope的封装
如果想要封装lifecycleScope,则可以利用kotlin的扩展函数:
随便新建一个文件,然后使用如下代码:
// 在所有实现了LifecycleOwner接口的类中,可以直接使用launch方法
fun LifecycleOwner.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
) = lifecycleScope.launch(context, start, block)
相当于在调用launch方法的时候, 实际上是调用lifecycleScope的launch方法, 而lifecycleScope是跟Activity等的生命周期绑定在一起的, 所以也不需要关系协程的取消, 使用的时候,在子类中直接调用launch方法即可
3. suspened的书写
suspened 标记的函数一定是一个耗时的操作, 这个时候我们可以尽量将内部的方法都切换到子线程中去做, 因为我们默认开启的协程都是运行在主线程上的, 如果我们不去做线程的切换,调用方在代码不熟悉的情况下还是有可能会卡线程
推荐写法(我自己这两天这么写的,不一定好):
suspend fun testFun() = withContext(Dispatchers.IO) {
// 子线程
"Hello" //最后一行就是返回值, 不要写return
}
利用kotlin的语法糖, 可以少写一层{}, 对比正常写法:
suspend fun testFun2():String {
return withContext(Dispatchers.IO) {
"Hello"
}
}
4. runBlocking的使用
一般来说我们是用不上runBlocking方式来开启协程的, 但是有时候我们依赖的框架给我们做了线程的切换, 此时就需要用到runBlocking的方式了:
比如阿里云的OSS, 在框架检测到token过期后, 会帮我们切到子线程进行回调,让我们去重新获取token:
val credentialProvider = object : OSSFederationCredentialProvider() {
override fun getFederationToken(): OSSFederationToken {
// 这里是子线程
val ossInfo = runBlocking {
// 这个方法是挂起函数, 必须在协程中调用
getOSSInfo()
}
return OSSFederationToken(
ossInfo.accessKeyId,
ossInfo.accessKeySecret,
ossInfo.securityToken,
ossInfo.expiration
)
}
}
可以看到上面的代码: getFederationToken()方法是OSS框架提供的callback,这个方法本身就执行在子线程了, 而我们要获取新的Token的方法还是一个挂起函数, 必须放在协程中调用, 最关键的是: getFederationToken方法是需要返回值的, 如果我们利用普通的方式开启协程, 这个方法的返回值就不能够提供了, 所以这里使用runBlocking的方式,这样可以正常开启协程, 并且可以让getFederationToken方法所在的线程阻塞主, 等我们获取到Token后,方法再返回
Kotlin自动切换线程的原理
我们可以通过将Kotlin代码转换为Java来窥探一下Kotlin自动切换线程的原理
kotlin代码:
class TestAty:BaseActivity() {
fun test() {
launch {
testIO()
testMain()
}
}
suspend fun testIO() {
withContext(Dispatchers.IO) {
"耗时操作".logd()
}
}
fun testMain(){
"这里是主线程".logd()
}
}

如图,实际上我们编写协程代码,真正在执行的时候, 会传出各种不同的lable值, 从而实现自动切换线程的功能