1.1 本文概述:
先简单介绍PCA算法,再使用PCA结合adaboost和kNN分析IBM员工满意度,最后使用PCA结合kNN分析基于综合国力指标的国家分类。
1.2 小结
- 运用PCA将特征向量限定为2,可以有效进行可视化。
- PCA进行解释上存在困难。
- PCA用于分类器的数据整理,有时候可能效果一般。但在特征较多的分类器会有明显效果,在特征较少的分类器效果一般。
- 采用PCA python源码和sklearn调包可以同时参照使用。
1.3 百度硬盘分享
已将数据源和代码打包上传百度硬盘,若需要数据,请留下联系邮箱,将给予密码。
https://pan.baidu.com/s/1jZEEszfaOAX9TnBwrGCo9w
2. PCA伪代码
- Remove the mean
- Compute the covariance matrix
- Find the eigenvalues and eigenvectors of the covariance matrix
- Sort the eigenvalues from largest to smallest
- Take the top N eigenvectors
- Transform the data into the new space created by the top N eigenvectors
3. PCA
import pandas as pd
import numpy as np
%matplotlib inline
%matplotlib notebook
import matplotlib.pyplot as plt
from numpy import *
import pca
# 导入数据
dataMat = pca.loadDataSet('testSet.txt')
# 进行PCA
lowDMat, reconMat = pca.pca(dataMat,1)
reconMat.shape
#(1000, 2)
# 检查PCA后的数据
shape(lowDMat)
#(1000, 1)
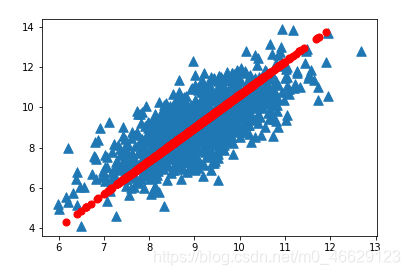
# 画出转化后的数据和原始数据
import matplotlib
import matplotlib.pyplot as plt
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(dataMat[:,0].flatten().A[0],dataMat[:,1].flatten().A[0],marker='^',s=90)
ax.scatter(reconMat[:,0].flatten().A[0],reconMat[:,1].flatten().A[0],marker='o',s=50,c='red')
4.例子:HR employee数据集分析
从https://www.datafountain.cn/datasets/12下载IBM员工满意度的虚拟数据,并做好员工满意度类型标签,并整理成txt或excel档案。

4.1 PCA转化数据:python代码
# 导入数据
train_dataMat,train_label = pca.loadDataSet2('HR_Employee_traindata2.txt')
test_dataMat,test_label = pca.loadDataSet2('HR_Employee_testdata2.txt')
# 原训练数据
train_dataMat
#matrix([[49., 2., 2., ..., 7., 1., 7.],
# [33., 2., 2., ..., 7., 3., 0.],
# [32., 2., 2., ..., 7., 3., 6.],
# ...,
# [36., 2., 2., ..., 2., 0., 3.],
# [27., 3., 2., ..., 2., 0., 3.],
# [34., 3., 2., ..., 3., 1., 2.]])
# 训练数据PCA化
train_lowDMat, train_reconMat = pca.pca2(train_dataMat,train_dataMat, topNfeat=2)
#print(train_lowDMat)
print(train_reconMat)
#[[35.67819662 2.59038249 2.27426855 ... 3.70269889 1.87499348 3.36467109]
# [33.44664184 2.58006477 2.2463986 ... 3.0579964 1.27380872 2.81726997]
# [33.43313878 2.60603005 2.20877739 ... 3.2540059 1.1553323 3.17338808]
# ...
# [32.94618716 2.60191623 2.2053757 ... 3.09901994 1.03236377 3.02822026]
# [36.38350649 2.64043231 2.21575047 ... 4.26583471 1.85856511 4.18381494]
# [34.73469768 2.61817288 2.21621902 ... 3.6770742 1.47894995 3.5772444 ]]
# 测试数据PCA化
test_lowDMat, test_reconMat = pca.pca2(test_dataMat,train_dataMat, topNfeat=2)
#print(test_lowDMat)
print(test_reconMat)
#[[36.4663323 2.61872289 2.24776821 ... 4.05858971 1.83784653 3.78498602]
# [32.59755474 2.61388361 2.24537484 ... 3.25416768 1.42410035 3.16091617]
# [34.06463853 2.61157705 2.24381457 ... 3.43679556 1.36893017 3.20159122]
# ...
# [33.6526533 2.60755682 2.24147128 ... 3.24753644 1.1454081 2.96928643]
# [40.23790023 2.6312754 2.25476991 ... 5.07437851 2.64236649 4.76411082]
# [35.82429866 2.61973548 2.24845292 ... 3.97876109 1.86215334 3.76733613]]
# 画出转化后的数据和原始数据
import matplotlib
import matplotlib.pyplot as plt
fig = plt.figure()
ax = fig.add_subplot(111)
for i in range(0,len(train_label)):
if train_label[i]==1:
marker = 'o'; s=10 ; c='red';
#ax.scatter(train_reconMat[i].A[0][0],train_reconMat[i].A[0][1],marker=marker,s=s,c=c)
ax.scatter(train_lowDMat[i].A[0][0],train_lowDMat[i].A[0][1],marker=marker,s=s,c=c)
else:
marker = '^' ; s=10 ; c='blue';
#ax.scatter(train_reconMat[i].A[0][0],train_reconMat[i].A[0][1],marker=marker,s=s,c=c)
ax.scatter(train_lowDMat[i].A[0][0],train_lowDMat[i].A[0][1],marker=marker,s=s,c=c)

4.2 PCA转化数据:调用sklearn,产生与4.1类似的图
from sklearn.decomposition import PCA
import mglearn
pca = PCA(n_components=2)
pca.fit(train_reconMat)
X_pca = pca.transform(train_reconMat)
plt.figure(figsize=(8, 8))
mglearn.discrete_scatter(X_pca[:, 0], X_pca[:, 1], train_label)
plt.legend(loc="best")
plt.xlabel("First principal component")
plt.ylabel("Second principal component")

4.3 将PCA运用在adaboost元算法,发现正确率无明显提升
import adaboost
# 转换数据
datArr = array(train_reconMat)
labelArr = train_label
testArr = array(train_reconMat)
testLabelArr = test_label
#建立分类器
classifierArray,_ = adaboost.adaBoostTrainDS(datArr,labelArr,10)
#进行分类
prediction10 = adaboost.adaClassify(testArr,classifierArray)
#错误统计
errArr=mat(ones((735,1)))
errnum = errArr[prediction10!=mat(testLabelArr).T].sum()
errnum
#151.0
#错误率
errnum/len(errArr)
#0.2054421768707483
4.4 将PCA运用于K近邻分类算法,效果也一般
import kNN
import pca
# 导入数据
filename='WA_Fn-UseC_-HR-Employee-Attrition_转化为数字-分类-1和1V2.xlsx'
feature_num=30
returnMat,classLabelVector = kNN.file2matrix(filename,feature_num)
# PCA化
train_lowDMat, train_reconMat = pca.pca(returnMat, topNfeat=2)
#2. 准备数据:归一化数据
normMat, ranges, minVals = kNN.autoNorm(train_reconMat)
#4. 测试算法:作为完整程序验证分类器
kNN.datingClassTest(filename,feature_num)
#the classifier came back with: 1, the real answer is: -1
#the classifier came back with: 1, the real answer is: 1
#the classifier came back with: 1, the real answer is: 1
#the classifier came back with: 1, the real answer is: -1
#the classifier came back with: 1, the real answer is: 1
#the classifier came back with: 1, the real answer is: 1
#the classifier came back with: 1, the real answer is: 1
#the classifier came back with: 1, the real answer is: -1
#the total error rate is: 0.205442
#151.0
其实kNN在这里的效果跟adaboost差不多。
5.例子:综合国力的数据集分析
从网上下载综合国力的指标数据。
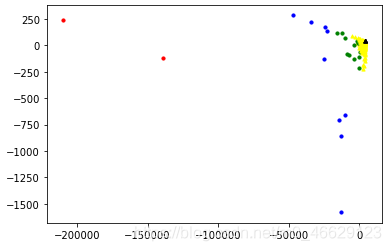
5.1 对比试验: 将PCA运用于K近邻分类算法(这次用综合国力的dataset)
import kNN
import pca
# 1.导入数据
filename='Nation20200923_np2.xlsx'
feature_num=30
returnMat,classLabelVector = kNN.file2matrix(filename,feature_num)
# PCA化
train_lowDMat, train_reconMat = pca.pca(returnMat, topNfeat=2)
#2. 准备数据:归一化数据
normMat, ranges, minVals = kNN.autoNorm(train_reconMat)
#4. 测试算法:作为完整程序验证分类器
kNN.datingClassTest(filename,feature_num)
#the classifier came back with: 4, the real answer is: 4
#the classifier came back with: 2, the real answer is: 2
#the classifier came back with: 3, the real answer is: 3
#the classifier came back with: 4, the real answer is: 4
#the classifier came back with: 3, the real answer is: 3
#the total error rate is: 0.056075
#6.0
# 3. 分析数据:使用matplotlib
import matplotlib
import matplotlib.pyplot as plt
fig = plt.figure()
ax = fig.add_subplot(111)
for i in range(0,len(classLabelVector)):
if classLabelVector[i]==0:
marker = 'o'; s=10 ; c='red';
ax.scatter(train_lowDMat[i].A[0][0],train_lowDMat[i].A[0][1],marker=marker,s=s,c=c)
elif classLabelVector[i]==1:
marker = 'o'; s=10 ; c='blue';
ax.scatter(train_lowDMat[i].A[0][0],train_lowDMat[i].A[0][1],marker=marker,s=s,c=c)
elif classLabelVector[i]==2:
marker = 'o'; s=10 ; c='green';
ax.scatter(train_lowDMat[i].A[0][0],train_lowDMat[i].A[0][1],marker=marker,s=s,c=c)
elif classLabelVector[i]==3:
marker = '^'; s=10 ; c='yellow';
ax.scatter(train_lowDMat[i].A[0][0],train_lowDMat[i].A[0][1],marker=marker,s=s,c=c)
else:
marker = '^' ; s=10 ; c='black';
ax.scatter(train_lowDMat[i].A[0][0],train_lowDMat[i].A[0][1],marker=marker,s=s,c=c)
5.2 对比试验: 不将PCA运用于K近邻分类算法(这次用综合国力的dataset)
import kNN
import pca
# 1.导入数据
filename='Nation20200923_np2.xlsx'
feature_num=30
returnMat,classLabelVector = kNN.file2matrix(filename,feature_num)
#2. 准备数据:归一化数据
normMat, ranges, minVals = kNN.autoNorm(train_reconMat)
#4. 测试算法:作为完整程序验证分类器
kNN.datingClassTest(filename,feature_num)
#the classifier came back with: 4, the real answer is: 4
#the classifier came back with: 3, the real answer is: 3
#the classifier came back with: 3, the real answer is: 3
#the classifier came back with: 3, the real answer is: 3
#the classifier came back with: 3, the real answer is: 3
#the total error rate is: 0.018692
#2.0
小结
- 运用PCA将特征向量限定为2,可以有效进行可视化。
- PCA进行解释上存在困难。
- PCA用于分类器的数据整理,有时候可能效果一般。但在特征较多的分类器会有明显效果,在特征较少的分类器效果一般。
- 采用PCA python源码和sklearn调包可以同时参照使用。
pca.py
from numpy import *
def loadDataSet(fileName, delim='\t'):
fr = open(fileName)
stringArr = [line.strip().split(delim) for line in fr.readlines()]
datArr = [list(map(float,line)) for line in stringArr]
return mat(datArr)
def loadDataSet2(fileName): #general function to parse tab -delimited floats
numFeat = len(open(fileName).readline().split('\t')) #get number of fields
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr =[]
curLine = line.strip().split('\t')
for i in range(numFeat-1):
lineArr.append(float(curLine[i]))
dataMat.append(lineArr)
labelMat.append(float(curLine[-1]))
return mat(dataMat),labelMat
def pca(dataMat, topNfeat=9999999):
# 1.计算各属性的平均值
meanVals = mean(dataMat, axis=0)
# 2.减去平均值
meanRemoved = dataMat - meanVals #remove mean
# 3. 计算协方差矩阵的特征值和特征向量
covMat = cov(meanRemoved, rowvar=0)
eigVals,eigVects = linalg.eig(mat(covMat))
# 4. 将特征值的索引从大到小排序
eigValInd = argsort(eigVals) #sort, sort goes smallest to largest
eigValInd = eigValInd[:-(topNfeat+1):-1] #cut off unwanted dimensions
# 5. 保留topNfeat个最大的特征向量
redEigVects = eigVects[:,eigValInd] #reorganize eig vects largest to smallest
# 6. 将数据转换到上述topNfeat个特征向量构建的新空间中
lowDDataMat = meanRemoved * redEigVects #transform data into new dimensions
# 7. 重构
reconMat = (lowDDataMat * redEigVects.T) + meanVals
return lowDDataMat, reconMat
def pca2(dataMat, trandataMat, topNfeat=9999999):
#### 将训练数据的平均值用于测试集数据的PCA ####
# 1.计算各属性的平均值
meanVals = mean(trandataMat, axis=0)
# 2.减去平均值
meanRemoved = dataMat - meanVals #remove mean
# 3. 计算协方差矩阵的特征值和特征向量
covMat = cov(meanRemoved, rowvar=0)
eigVals,eigVects = linalg.eig(mat(covMat))
# 4. 将特征值的索引从大到小排序
eigValInd = argsort(eigVals) #sort, sort goes smallest to largest
eigValInd = eigValInd[:-(topNfeat+1):-1] #cut off unwanted dimensions
# 5. 保留topNfeat个最大的特征向量
redEigVects = eigVects[:,eigValInd] #reorganize eig vects largest to smallest
# 6. 将数据转换到上述topNfeat个特征向量构建的新空间中
lowDDataMat = meanRemoved * redEigVects #transform data into new dimensions
# 7. 重构
reconMat = (lowDDataMat * redEigVects.T) + meanVals
return lowDDataMat, reconMat
def replaceNanWithMean():
datMat = loadDataSet('secom.data', ' ')
numFeat = shape(datMat)[1]
for i in range(numFeat):
meanVal = mean(datMat[nonzero(~isnan(datMat[:,i].A))[0],i]) #values that are not NaN (a number)
datMat[nonzero(isnan(datMat[:,i].A))[0],i] = meanVal #set NaN values to mean
return datMat
adaboost.py
from numpy import *
def loadSimpData():
datMat = matrix([[ 1. , 2.1],
[ 2. , 1.1],
[ 1.3, 1. ],
[ 1. , 1. ],
[ 2. , 1. ]])
classLabels = [1.0, 1.0, -1.0, -1.0, 1.0]
return datMat,classLabels
def loadDataSet(fileName): #general function to parse tab -delimited floats
numFeat = len(open(fileName).readline().split('\t')) #get number of fields
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr =[]
curLine = line.strip().split('\t')
for i in range(numFeat-1):
lineArr.append(float(curLine[i]))
dataMat.append(lineArr)
labelMat.append(float(curLine[-1]))
return dataMat,labelMat
def stumpClassify(dataMatrix,dimen,threshVal,threshIneq):#just classify the data
retArray = ones((shape(dataMatrix)[0],1))
if threshIneq == 'lt':
retArray[dataMatrix[:,dimen] <= threshVal] = -1.0
else:
retArray[dataMatrix[:,dimen] > threshVal] = -1.0
return retArray
def buildStump(dataArr,classLabels,D):
dataMatrix = mat(dataArr); labelMat = mat(classLabels).T
m,n = shape(dataMatrix)
numSteps = 10.0; bestStump = {
}; bestClasEst = mat(zeros((m,1)))
minError = inf #init error sum, to +infinity
for i in range(n):#loop over all dimensions
rangeMin = dataMatrix[:,i].min(); rangeMax = dataMatrix[:,i].max();
stepSize = (rangeMax-rangeMin)/numSteps
for j in range(-1,int(numSteps)+1):#loop over all range in current dimension
for inequal in ['lt', 'gt']: #go over less than and greater than
threshVal = (rangeMin + float(j) * stepSize)
predictedVals = stumpClassify(dataMatrix,i,threshVal,inequal)#call stump classify with i, j, lessThan
errArr = mat(ones((m,1)))
errArr[predictedVals == labelMat] = 0
weightedError = D.T*errArr #calc total error multiplied by D
#print "split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" % (i, threshVal, inequal, weightedError)
if weightedError < minError:
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump,minError,bestClasEst
def adaBoostTrainDS(dataArr,classLabels,numIt=40):
weakClassArr = []
m = shape(dataArr)[0]
D = mat(ones((m,1))/m) #init D to all equal
aggClassEst = mat(zeros((m,1)))
for i in range(numIt):
bestStump,error,classEst = buildStump(dataArr,classLabels,D)#build Stump
#print "D:",D.T
alpha = float(0.5*log((1.0-error)/max(error,1e-16)))#calc alpha, throw in max(error,eps) to account for error=0
bestStump['alpha'] = alpha
weakClassArr.append(bestStump) #store Stump Params in Array
#print "classEst: ",classEst.T
expon = multiply(-1*alpha*mat(classLabels).T,classEst) #exponent for D calc, getting messy
D = multiply(D,exp(expon)) #Calc New D for next iteration
D = D/D.sum()
#calc training error of all classifiers, if this is 0 quit for loop early (use break)
aggClassEst += alpha*classEst
#print "aggClassEst: ",aggClassEst.T
aggErrors = multiply(sign(aggClassEst) != mat(classLabels).T,ones((m,1)))
errorRate = aggErrors.sum()/m
print ("total error: ",errorRate)
if errorRate == 0.0: break
return weakClassArr,aggClassEst
def adaClassify(datToClass,classifierArr):
dataMatrix = mat(datToClass)#do stuff similar to last aggClassEst in adaBoostTrainDS
m = shape(dataMatrix)[0]
aggClassEst = mat(zeros((m,1)))
for i in range(len(classifierArr)):
classEst = stumpClassify(dataMatrix,
classifierArr[i]['dim'],
classifierArr[i]['thresh'],
classifierArr[i]['ineq'])#call stump classify
aggClassEst += classifierArr[i]['alpha']*classEst
print (aggClassEst)
return sign(aggClassEst)
def plotROC(predStrengths, classLabels):
import matplotlib.pyplot as plt
cur = (1.0,1.0) #cursor
ySum = 0.0 #variable to calculate AUC
numPosClas = sum(array(classLabels)==1.0)
yStep = 1/float(numPosClas); xStep = 1/float(len(classLabels)-numPosClas)
sortedIndicies = predStrengths.argsort()#get sorted index, it's reverse
fig = plt.figure()
fig.clf()
ax = plt.subplot(111)
#loop through all the values, drawing a line segment at each point
for index in sortedIndicies.tolist()[0]:
if classLabels[index] == 1.0:
delX = 0; delY = yStep;
else:
delX = xStep; delY = 0;
ySum += cur[1]
#draw line from cur to (cur[0]-delX,cur[1]-delY)
ax.plot([cur[0],cur[0]-delX],[cur[1],cur[1]-delY], c='b')
cur = (cur[0]-delX,cur[1]-delY)
ax.plot([0,1],[0,1],'b--')
plt.xlabel('False positive rate'); plt.ylabel('True positive rate')
plt.title('ROC curve for AdaBoost horse colic detection system')
ax.axis([0,1,0,1])
plt.show()
print ("the Area Under the Curve is: ",ySum*xStep)
kNN.py
from numpy import *
import operator
from os import listdir
import pandas as pd
import numpy as np
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={
}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
def file2matrix(filename,feature_num):
df = pd.read_excel(filename)
df = df.reindex(np.random.permutation(df.index))
df.to_excel('random.xlsx')
df_values = df.values
returnMat = df_values[:,:feature_num]
classLabelVector = df_values[:,-1]
return returnMat,classLabelVector
def autoNorm(dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - tile(minVals, (m,1))
normDataSet = normDataSet/tile(ranges, (m,1)) #element wise divide
return normDataSet, ranges, minVals
def datingClassTest(filename,feature_num):
hoRatio = 0.50 #hold out 10%
returnMat,classLabelVector = file2matrix(filename,feature_num) #load data setfrom file
normMat, ranges, minVals = autoNorm(returnMat)
m = normMat.shape[0]
numTestVecs = int(m*hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],classLabelVector[numTestVecs:m],3)
print("the classifier came back with: %d, the real answer is: %d" % (classifierResult, classLabelVector[i]))
if (classifierResult != classLabelVector[i]): errorCount += 1.0
print ("the total error rate is: %f" % (errorCount/float(numTestVecs)))
print (errorCount)
def classifyPerson(filename,feature_num):
resultList = ['超级大国','强国','中等国','较小国','微小国']
feature0 = float(input("your feature0-国土面积(万平方千米):"))
feature1 = float(input("your feature1-GDP(亿美元):"))
feature2 = float(input("your feature2-人口(亿):"))
returnMat,classLabelVector = file2matrix(filename,feature_num)
normMat, ranges, minVals = autoNorm(returnMat)
inArr = array([feature0, feature1, feature2])
classifierResult = int(classify0((inArr-minVals)/ranges,normMat,classLabelVector,3))
print("Result: ",resultList[classifierResult])