课程目录 小象学院 - 人工智能
关注公众号【Python家庭】领取1024G整套教材、交流群学习、商务合作。整理分享了数套四位数培训机构的教材,现免费分享交流学习,并提供解答、交流群。
你要的白嫖教程,这里可能都有喔~
本关内容概述
从本关起,我们将正式进入到机器学习算法的学习啦,撒花~~

我们要学习的第一个算法是一个简单的分类算法-- k近邻算法(k Nearest Neighbors,kNN)。

俗话说,好的开始是成功的一半!究竟选择哪个算法作为第一个学习的算法,我们也经历了一些思想斗争。出于以下两点考虑,我们最终做出了“这个艰难的决定”:
-
kNN算法的思想非常简单,几乎用不到数学知识,不超过5分钟就可以理解其核心思想;
-
kNN算法的代码实现非常简单,核心代码不超过5行。
在本关,我们先从kNN算法的原理开始学习,然后会一步一步地教会你如何实现一个kNN算法。话不多说,快开始这一关的学习吧!
kNN算法原理
kNN算法属于有监督学习,通常用于完成分类任务。我们先通过一个例子来形象地理解一下kNN算法是如何完成分类这个任务的:

-
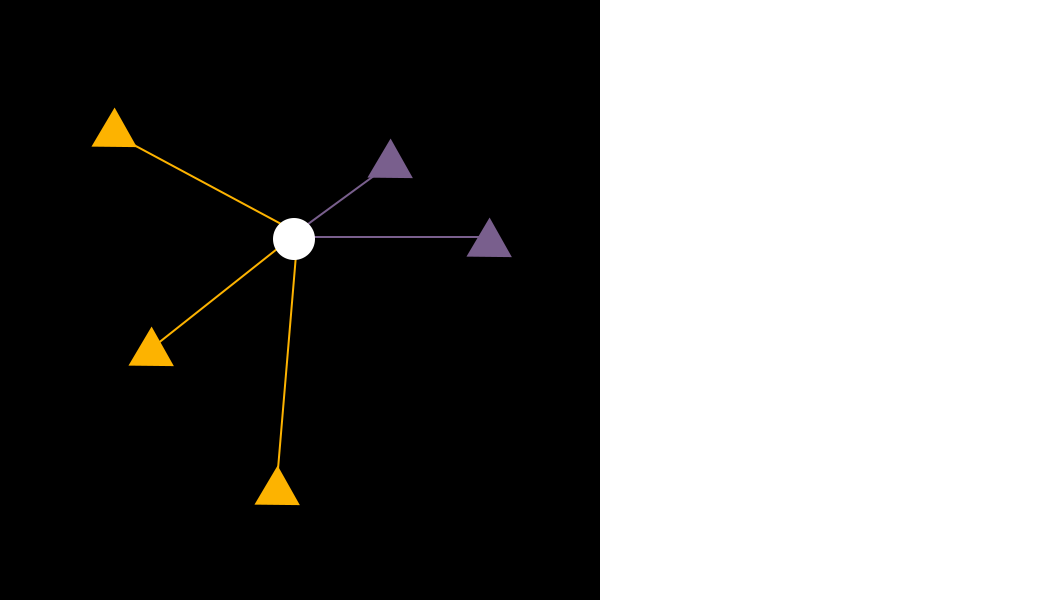
如图1所示,黄色和紫色的三角形是我们提前标记好的数据样本,我们的任务是预测一个新样本(白色的圆圈)属于黄色和紫色中的哪个类别。
-
如图2所示,我们找到距离白色样本最近的3个样本,其中紫色样本有2个,黄色样本有1个,因此,我们将新样本预测为紫色这一类别。
怎么样?是不是很简单?前面说5分钟就可以理解kNN算法,没有吹牛吧?
现在你对kNN算法已经有了初步的了解,先别着急往下学,停下来想一想:如果现在让你跟别人讲一下kNN算法的原理,你会怎么去描述呢?

kNN算法核心思想与三要素
我们可以用一句话来概括kNN算法的核心思想:
对于一个待分类样本,找出距离它最近的k个样本,这k个样本中大多数样本所属的类别,即为该样本所属的类别。
如果你也是这样想的,那么恭喜你,你掌握得很不错!
实际上,用一句话来总结kNN算法还是有些繁琐,可以更加精炼地用3个关键词来刻画kNN算法:k值的选取、距离度量方式和投票规则。在上面的例子中,我们人为地将k值设置为3;距离度量方式采用的是我们最熟悉的计算两点距离的方式(也叫作“欧氏距离”);投票规则采用的是少数服从多数原则。
欧氏距离
学到这里,我们需要复习一下欧氏距离的计算公式。如下图所示,样本![]() 和 样本
和 样本![]() 之间的距离公式为
之间的距离公式为 ![]() 。
。

接下来,我们做一个小练习:使用Python编程计算样本![]() 和样本
和样本![]() 间的距离。
间的距离。
AI_4_0_1
import numpy as np
# 创建两个数组,分别存放(0.1, 0.1)和(1, 1.1)两个点的数据
x = np.array([0.1, 0.1])
z = np.array([1, 1.1])
# np.sqrt是numpy提供的开平方函数
d = np.sqrt((x[0] - z[0])**2 + (x[1] - z[1])**2)
print(d) 1.3453624047073711
程序的输出结果约为1.345。观察这个程序的实现,请你思考这样一个问题:为什么要引入ndarray来保存![]() 和
和![]() ,看上去用python自带的 list 就完全够用了啊?就像下面这样实现:
,看上去用python自带的 list 就完全够用了啊?就像下面这样实现:
AI_4_0_2
from math import sqrt
x = [0.1, 0.1]
z = [1, 1.1]
d = sqrt((x[0] - z[0])**2 + (x[1] - z[1])**2)
print(d)1.3453624047073711
似乎用list实现还更加简洁一些呢!但是出于以下两点考虑,在机器学习中,我们通常会用ndarray来取代list:
-
ndarray速度更快:list中可以包含不同类型的数据(如整型、浮点型、字符串类型等等),使用起来更加灵活,但这种灵活是以降低程序运行效率作为代价的;ndarray中只能存放相同类型的数据,运行速度要快很多。
-
ndarray支持向量化操作:ndarray将数据看作向量或矩阵,可以直接对数据进行向量化操作,这一点是list做不到的。
向量化操作
那么问题来了:什么是向量化操作?下面我们举个例子说明一下:

为了计算出样本 ![]() 和样本
和样本 ![]() 之间的距离,我们将样本看作是2维的向量,这样我们就可以利用向量的性质对样本进行减法运算:
之间的距离,我们将样本看作是2维的向量,这样我们就可以利用向量的性质对样本进行减法运算:

对向量进行平方操作也非常的方便:
最后,我们将0.81和1进行相加,并对结果开平方,就可以得到我们想要计算的距离。
在学习了向量化的操作之后,让我们赶紧来动手实现一下:
AI_4_0_3
import numpy as np
# 创建两个数组,分别存放(0.1, 0.1)和(1, 1.1)两个点的数据
x=np.array([0.1,0.1])
y=np.array([1,1.1])
print('**********************************')
print(np.sqrt(sum((x-y)**2)))**********************************
1.3453624047073711
相比之前的程序,运行结果是相同的,但代码更简洁,运行效率也更高,是不是感觉很方便?试想一下,假如样本不仅仅只有两个坐标维度,而是有成百上千个维度,上面这行代码仍然有效,厉害吧,这就是向量化操作的魅力!
让我们趁热打铁,再来做一个稍微具有挑战性的练习:

AI_4_0_4
import numpy as np
# 构造数据
x = np.array([0.1, 0.1])
X = np.array([
[1, 1.1],
[1, 1],
[0, 0],
[0, 0.1]
])
# 创建一个空的列表d,用于保存距离
d = []
# 利用循环分别计算与4个样本的距离,并保存到d中
for i in range(4):
d.append(np.sqrt(np.sum((x - X[i])**2)))
print(d)[1.3453624047073711, 1.2727922061357855, 0.14142135623730953, 0.1]有了前面的铺垫,我们很自然想到,可以利用一个循环,每次从X中取出一行(1个样本),然后用向量化的方式求出该样本与x的距离,程序输出的结果为:[1.3453624047073711, 1.2727922061357855, 0.14142135623730953, 0.1]。
本关后半部分内容,将教你亲自动手实现一下kNN算法。不过,在继续学习之前,还有一个彩蛋送给大家~~

广播机制
对于上面这个练习,我们可以利用Python语言提供的“广播(broadcasting)机制”给出一个更优雅的实现:

简单分析一下上面的计算过程会发现:当两个维度不一致的ndarray进行运算时,在不产生歧义的情况下,Python会很智能地对低维数据进行扩展。
了解了Python的这个特性后,我们用一行代码就可以完成上面的练习,让我们动手实现一下:
AI_4_0_5
import numpy as np
# 构造数据
x = np.array([0.1, 0.1])
X = np.array([
[1, 1.1],
[1, 1],
[0, 0],
[0, 0.1]
])
# 利用Python的广播机制求距离
d = np.sqrt(np.sum((x - X)**2, axis=1))
print(d)[1.3453624 1.27279221 0.14142136 0.1 ]
对np.sum(..., axis=...)这个求和函数不了解的小伙伴请看下面这张图:

好了,彩蛋到这里结束,让我们回到正题上。
动手实现kNN算法
想必你已经迫不及待地想要实现一个属于自己的kNN算法了,先给自己定个“小目标”吧:用5行以内的代码实现kNN算法。你准备好接受挑战了吗?

正所谓“磨刀不误砍柴工”,我们先来梳理一下kNN算法的流程,可分为四个步骤:
首先,计算待预测新样本与已有数据集中每个样本的距离;
其次,将距离按从小到大进行排序;
然后,选出前k个距离最近的样本,并统计这k个样本对应类别出现的次数;

最后,将出现次数最多的类别作为最终的预测结果。

有了算法流程,那接下来的事情就好办了,对这四个步骤,我们逐个击破就可以了,是不是已经看到了胜利的曙光呢?


第一步 计算距离
第一步:计算待预测新样本与已有数据集中每个样本的距离
d = np.sqrt(np.sum((x - X)**2, axis=1)) # 这一步已经在前面进行了详细的介绍
AI_4_0_6
import numpy as np
x = np.array([0.1, 0.1])
X = np.array([
[1, 1.1],
[0, 0],
[0, 0.1],
[1, 1]
])
y = np.array(['蓝', '红', '红', '蓝'])
d = np.sqrt(np.sum((x - X)**2, axis=1))
print(d)[1.3453624 0.14142136 0.1 1.27279221]
第二步 距离排序
第二步:将距离按从小到大进行排序
我们可以直接调用numpy给我们提供的函数来实现对距离的排序。numpy中关于排序的函数有两个:np.sort() 和 np.argsort(),它们的作用分别如下所示:

不难发现, np.sort(d)是将d中的元素从小到大进行排序,而np.argsort(d)返回的是排好序的元素原来的索引值 ,因此这一步的代码实现很简单:
index = np.argsort(d) # np.sort(d)得到的结果后面用不到,因此这里没有使用
AI_4_0_7
import numpy as np
x = np.array([0.1, 0.1])
X = np.array([
[1, 1.1],
[0, 0],
[0, 0.1],
[1, 1]
])
y = np.array(['蓝', '红', '红', '蓝'])
d = np.sqrt(np.sum((x - X)**2, axis=1))
index = np.argsort(d)
print(index)[2 1 3 0]
第三步 频数统计
第三步:选出前k个距离最近的样本,并统计这k个样本对应类别出现的次数
这一步的实现,稍微麻烦一点,但也难不倒我们!在学完下面内容后,你会发现仍然只需要1行代码就可以搞定这一步!

先来看一下,如何选出前k个距离最近的样本:
假设取k=3,很容易就可以得到3个距离最近的样本的索引以及对应的标签:
index[0:3] # [2,1,3][y[i] for i in index[0:3]] # [y[2], y[1], y[3]] = ['红', '红', '蓝']
AI_4_0_8
import numpy as np
x = np.array([0.1, 0.1])
X = np.array([
[1, 1.1],
[0, 0],
[0, 0.1],
[1, 1]
])
y = np.array(['蓝', '红', '红', '蓝'])
d = np.sqrt(np.sum((x - X)**2, axis=1))
index = np.argsort(d)
print(index[0:3])
print([y[i] for i in index[0:3]])[2 1 3]
['红', '红', '蓝']
这里偷偷地告诉大家一个小技巧,numpy中提供了一种叫作“Fancy Indexing”的机制,若y是ndarray类型,传入索引的列表,就可以同时得到多个索引位置的元素,如下所示:
y[index[0:3]] # [y[2], y[1], y[3]] = ['红', '红', '蓝']
AI_4_0_9
import numpy as np
x = np.array([0.1, 0.1])
X = np.array([
[1, 1.1],
[0, 0],
[0, 0.1],
[1, 1]
])
y = np.array(['蓝', '红', '红', '蓝'])
d = np.sqrt(np.sum((x - X)**2, axis=1))
index = np.argsort(d)
print(y[index[0:3]])['红' '红' '蓝']
再来看一下,如何统计这k个样本对应类别出现的次数:
通常我们会用字典来完成“统计”这类任务,将“类别”作为key,“出现次数”作为value:
count = {} # 创建一个空字典for label in y[index[0:3]]:# count.get(label, 0)作用:若label已存在于字典count中,返回count[label]的值,否则返回0count[label] = count.get(label, 0) + 1print(count) # count:{'红': 2, '蓝': 1}
AI_4_0_10
import numpy as np
x = np.array([0.1, 0.1])
X = np.array([
[1, 1.1],
[0, 0],
[0, 0.1],
[1, 1]
])
y = np.array(['蓝', '红', '红', '蓝'])
d = np.sqrt(np.sum((x - X)**2, axis=1))
index = np.argsort(d)
count = {}
for label in y[index[0:3]]:
count[label] = count.get(label, 0) + 1
print(count)正因为统计次数这个需求很常见,因此Python提供了一个Counter类,可以帮助我们自动统计每个元素的出现次数,下面的代码可以实现与上面相同的功能:
from collections import Counter # 从collections包中导入Counter类count = Counter(y[index[0:3]]) # count:{'红': 2, '蓝': 1}
AI_4_0_11
import numpy as np
from collections import Counter
x = np.array([0.1, 0.1])
X = np.array([
[1, 1.1],
[0, 0],
[0, 0.1],
[1, 1]
])
y = np.array(['蓝', '红', '红', '蓝'])
d = np.sqrt(np.sum((x - X)**2, axis=1))
index = np.argsort(d)
count = Counter(y[index[0:3]])
print(count)Counter({'红': 2, '蓝': 1})
第四步 预测分类
第四步:将出现次数最多的类别作为最终的预测结果
终于到最后一步啦,胜利已经在向你招手了!
有了前面的铺垫,这一步就很容易了。Counter类提供了一个most_common(n)方法,用于返回Counter中n个元素,并且是按照“出现次数”由大到小的顺序返回的(若不传入参数n,则默认返回Counter中所有元素):
count.most_common() # [('红', 2), ('蓝', 1)]
我们希望得到的是出现次数最多的类别,因此代码可以这样实现:
count.most_common()[0][0] # '红'
AI_4_0_12
import numpy as np
from collections import Counter
x = np.array([0.1, 0.1])
X = np.array([
[1, 1.1],
[0, 0],
[0, 0.1],
[1, 1]
])
y = np.array(['蓝', '红', '红', '蓝'])
d = np.sqrt(np.sum((x - X)**2, axis=1))
index = np.argsort(d)
count = Counter(y[index[0:3]])
print(count.most_common()[0][0])恭喜你,到这里,我们已经完成了对kNN算法每一步的实现,终于可以松一口气了,是不是很有成就感?

今天我们就先学到这里吧,下一关见,拜拜~
联系我们,一起学Python吧
分享Python实战代码,入门资料,进阶资料,基础语法,爬虫,数据分析,web网站,机器学习,深度学习等等。
 关注公众号「Python家庭」领取1024G整套教材、交流群学习、商务合作
关注公众号「Python家庭」领取1024G整套教材、交流群学习、商务合作