
论文统计每月第一周更新一次,主要跟踪语音合成的发展状况(很多文章都是在会议后才发出,但不影响统计。统计过程难免存在疏漏,因此统计结果仅供参考。读者有什么建议可以直接向我发消息,我将不断修改该统计。历年文章统计可访问 http://yqli.tech/page/tts_paper.html)。如有转载,请注明出处。欢迎关注微信公众号:低调奋进。
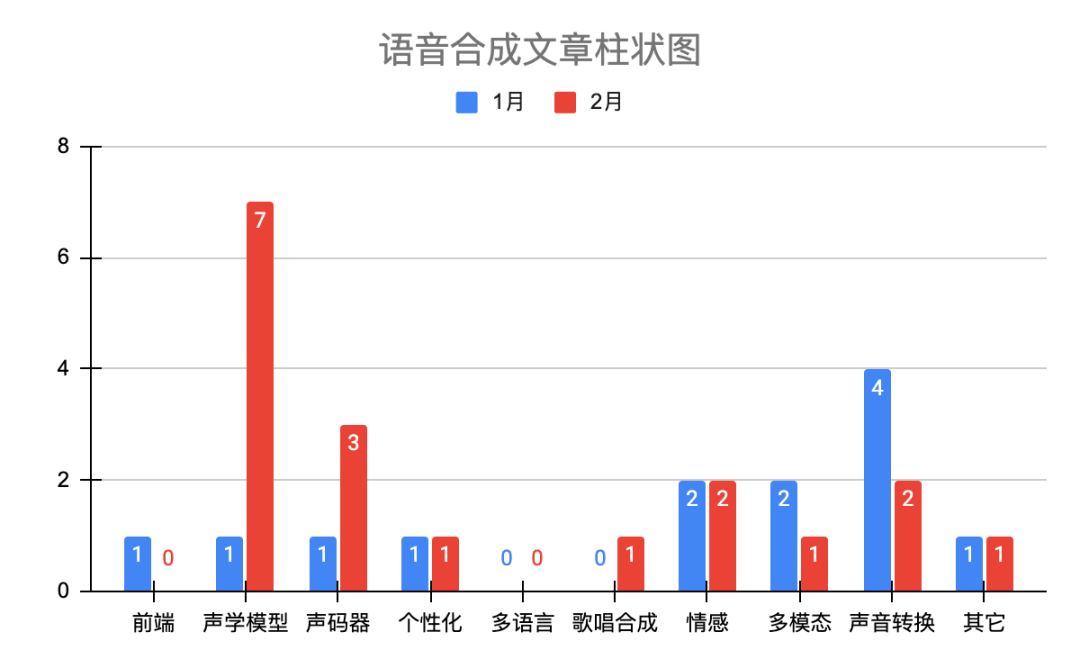
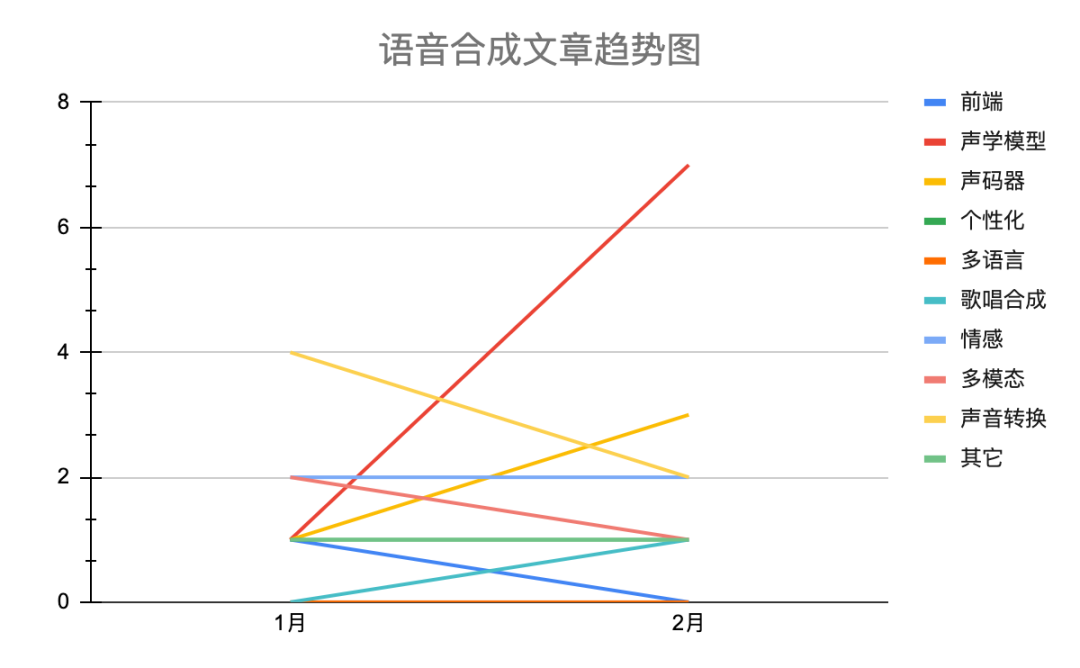
语音合成文章情况表(单位:篇)
| 1月 | 2月 | ||
| 前端 | 多音字,韵律,g2p等等。 | 1 | 0 |
| 声学模型 | 语言特征转声学特征,attention工作以及双重学习 | 1 | 7 |
| 声码器 | 波形生成 | 1 | 3 |
| 个性化 | 少数据,脏数据应用等 | 1 | 1 |
| 多语言 | 多语言多说话人模型 | 0 | 0 |
| 歌唱合成 | 歌唱和音乐合成 | 0 | 1 |
| 情感 | 风格和情感 | 2 | 2 |
| 多模态 | talking head等等 | 2 | 1 |
| 声音转换 | 基于GAN方案和特征解耦方案 | 4 | 2 |
| 其它 | 基于EEG合成,数据,MOS评测以及语音合成的应用 | 1 | 1 |
文章列表:
1月
扫描二维码关注公众号,回复:
12909383 查看本文章

| 类型 | ||
| 1 | Supervised and Unsupervised Approaches for Controlling Narrow Lexical Focus in Sequence-to-Sequence Speech Synthesis | am |
| 2 | Polyphone Disambiguition in Mandarin Chinese with Semi-Supervised Learning | frontend |
| 3 | Generating coherent spontaneous speech and gesture from text | multimodality |
| 4 | Creating Song From Lip and Tongue Videos With a Convolutional Vocoder | multimodality |
| 5 | On Interfacing the Brain with Quantum Computers: An Approach to Listen to the Logic of the Mind | other |
| 6 | Whispered and Lombard Neural Speech Synthesis | expression |
| 7 | Expressive Neural Voice Cloning | expression/ personalization |
| 8 | High-Quality Vocoding Design with Signal Processing for Speech Synthesis and Voice Conversion | vc |
| 9 | EmoCat: Language-agnostic Emotional Voice Conversion | vc |
| 10 | Hierarchical disentangled representation learning for singing voice conversion | vc |
| 11 | Adversarially learning disentangled speech representations for robust multi-factor voice conversion | vc |
| 12 | Improved parallel WaveGAN vocoder with perceptually weighted spectrogram loss | vocoder |
2月
| 1 | Triple M: A Practical Neural Text-to-speech System With Multi-guidance Attention And Multi-band Multi-time Lpcnet | am |
| 2 | Mixture Density Network for Phone-Level Prosody Modelling in Speech Synthesis | am |
| 3 | VARA-TTS: Non-Autoregressive Text-to-Speech Synthesis based on Very Deep VAE with Residual Attention | am |
| 4 | Alternate Endings: Improving Prosody for Incremental Neural TTS with Predicted Future Text Input | am |
| 5 |
Bidirectional Variational Inference for Non-Autoregressive Text-to-Speech | am |
| 6 | LightSpeech: Lightweight and Fast Text to Speech with Neural Architecture Search | am |
| 7 | Data-Efficient Training Strategies for Neural TTS Systemsmatch | am |
| 8 | Model architectures to extrapolate emotional expressions in DNN-based text-to-speech | expression |
| 9 | Model architectures to extrapolate emotional expressions in DNN-based text-to-speech | expression |
| 10 | SPEAK WITH YOUR HANDS Using Continuous Hand Gestures to control Articulatory Speech Synthesizer | modal |
| 11 | MBNet: MOS Prediction for Synthesized Speech with Mean-Bias Network | other |
| 12 | Voice Cloning: a Multi-Speaker Text-to-Speech Synthesis Approach based on Transfer Learning | personalization |
| 13 | Anyone GAN Sing | sing |
| 14 | Towards Natural and Controllable Cross-Lingual Voice Conversion Based on Neural TTS Model and Phonetic Posteriorgram | vc |
| 15 | Investigating Deep Neural Structures and their Interpretability in the Domain of Voice Conversion | vc |
| 16 | Universal Neural Vocoding with Parallel WaveNet | vocoder |
| 17 | LVCNet: Efficient Condition-Dependent Modeling Network for Waveform Generation | vocoder |
| 18 | High-Quality Vocoding Design with Signal Processing for Speech Synthesis and Voice Conversion | vocoder |