声明:语音开源项目主要分享优秀的开源项目,促进开源社区的壮大。所写的内容主要是我个人看法,如有错误,还望指正。如有转载,请标注来源。 欢迎关注微信公众号:低调奋进
VCTUBE : A Library for Automatic Speech Data Annotation
本文是自动语音标注库,主要为了自动生成语音合成系统的训练语料<audio, text>,相关的文章发表在interspeech2020,具体的文章链接
https://www.isca-speech.org/archive/Interspeech_2020/pdfs/4004.pdf
该python库的使用方法
https://dsail-skku.github.io/VCTUBE.github.io/
1 项目简介
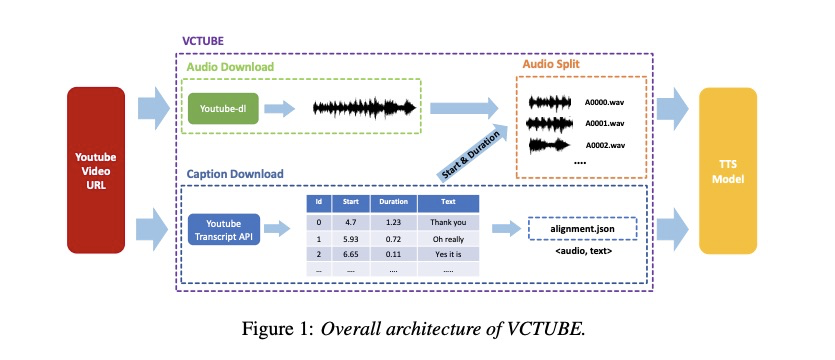
通常语音合成系统需要大量的训练语料<audio, text>,本文提出的python库VCTUBE是从youtube上自动下载视频和字幕,然后生成语音合成的训练语料。详细的体统结构如图1所示,该系统为三模块组成:1)audio 下载模块;2)字幕下载模块;3)音频分割模块。
2, 使用方法
How To Use VCTUBE?
Requirment for VCTUBE
- Currently requires python >= 3.6
- FFmpeg
- At first you need to install VCTUBE library by pip install command
1
pip3 install vctube
cs
Command for VCTUBE1
2
3
4
5
6
7
8
9
10
from vctube import VCtube
playlist_name = ""
playlist_url = ""
lang = "" # ex) ko, en, fr, de ...
vc = VCtube(playlist_name, playlist_url, lang)
vc.download_audio() #download audios from youtube
vc.download_captions() #download captions from youtube
vc.audio_split() #split audio with captions
cs
VCTUBE Example
- Setting for VCTUBE
| 1 2 3 4 5 |
from vctube import VCtube playlist_url = "https://www.youtube.com/watch?v=fj5BcN6Blks" playlist_name="TEST" lang = "en" #ex) ko, en, fr, de... vc = VCtube(playlist_name, playlist_url, lang) |
cs |
- Result of this process
| 1 2 3 |
vc.download_audio() vc.download_captions() vc.audio_split() |
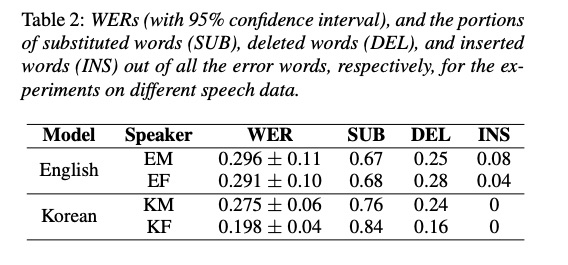
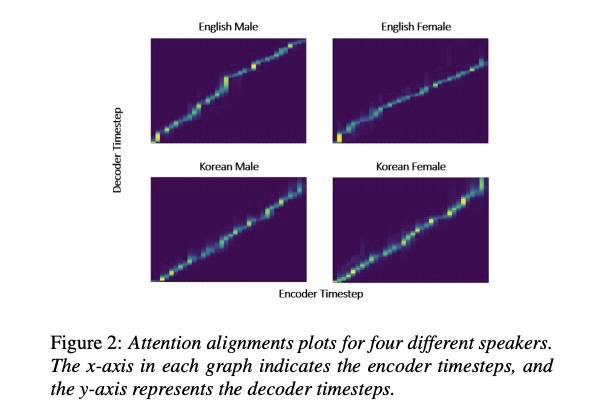
3 实验
本文给出了英文和韩语的实验,从youtube上自动获取数据然后在tacotron上进行测试。table2为合成音频的WER测试,图2为对齐情况,说明自动生成的训练语料可用。