原问题如下:
opinion extraction system,information retrieval system是如何通过syntactic parsing实现的?
解答如下:
这里面有两个问题:1. 在opinion extraction/IR中如何使用句法分析;
2. 句法分析在多大程度上对这两个任务有帮助(原题)。
由于我自己主要还是做句法分析本身,暂时很少做上层应用,所以简单谈谈我对应用的理解,抛砖引玉。
1 在opinion extraction/IR中如何使用句法分析。
举几个例子吧。
比如在opinion extraction中我们常常要抽取评价对象(aspect):
例:“知乎的内容质量很好”
这里 “很好” 形容的是 “内容质量”。通过依存句法分析,就可以抽取出对应的搭配。如下图:
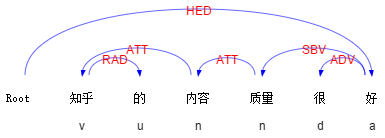
(顺手插个广告,分析结果来自我们实验室的语言云:在线演示 | 语言云(语言技术平台云 LTP-Cloud))
再说说IR,以百度框计算为例。对于以下两个query:
Query 1: 谢霆锋的儿子是谁?
Query 2: 谢霆锋是谁的儿子?
这两个Query的bag-of-words完全一致,如果不考虑其语法结构,很难直接给用户返回正确的结果。
类似的例子还有很多。在这种情况下,通过句法分析,我们就能够知道用户询问的真正对象是什么。
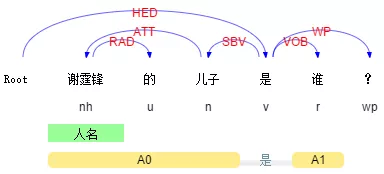
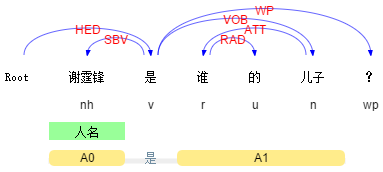
推而广之,对Query进行更general的需求分析大都离不开描述对象的提取,很多时候句法结构非常关键,更是下一步语义分析的前提。
2 句法分析在多大程度上对这两个任务有帮助(原题)。
原问题很好,可以扩展出很多思考。在炼丹纪到来之前,也许我们可以给一个非常乐观的回答,比如60%。但是现如今,我们需要思虑再三。主要原因在于,RNN/LSTM等强大的时序模型(sequential modeling)能够在一定程度上刻画句子的隐含语法结构。
尽管我们暂时无法提供一个清晰的解释,但是它在很多任务上的确表现出非常promising的性能。
推荐一下车万翔老师前段时间写的一个简单的survey:哈工大车万翔:自然语言处理中的深度学习模型是否依赖于树结构?(google一下就有)
文中的一个性能对比能够说明问题:Tree-LSTM是基于句法结构之上的LSTM,Bi-LSTM则是简单的双向(left<->right)LSTM。
在很多任务上,Bi-LSTM都表现得比Tree-LSTM更好。
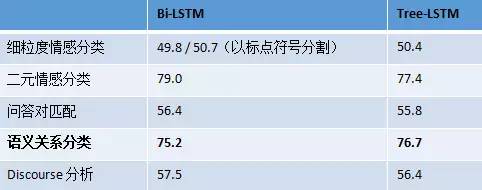
但是,这并不说明句法结构是没有用的,详细分析请参考上面提到的survey。
需要提及的是,句法分析目前的性能是防碍其实际应用的一个关键因素,尤其是在open-domain上。
目前在英文WSJ上的parsing性能最高能够做到94%,但是一旦跨领域,性能甚至跌到80%以下,是达不到实际应用标准的。而中文上parsing性能则更低。