文章目录
1. 什么是循环依赖
类与类之间的依赖关系形成了闭环,就会导致循环依赖问题的产生。
比如下图中A类依赖了B类,B类依赖了C类,而最后C类又依赖了A类,这样就形成了循环依赖问题:

1.1 演示代码
(1)演示代码:
public class ClassA {
private ClassB classB;
public ClassB getClassB() {
return classB;
}
public void setClassB(ClassB classB) {
this.classB = classB;
}
}
public class ClassB {
private ClassA classA;
public ClassA getClassA() {
return classA;
}
public void setClassA(ClassA classA) {
this.classA = classA;
}
}
(2)配置文件:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="classA" class="ioc.cd.ClassA">
<property name="classB" ref="classB"></property>
</bean>
<bean id="classB" class="ioc.cd.ClassB">
<property name="classA" ref="classA"></property>
</bean>
</beans>
(3)测试代码:
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class MainStart {
public static void main(String[] args) {
String resource = "spring-ioc-circular-dependency.xml";
ApplicationContext context = new ClassPathXmlApplicationContext(resource);
// 获取ClassA的实例(此时会发生循环依赖)
ClassA classA = (ClassA) context.getBean(ClassA.class);
}
}
2. 如何解决
2.1 bean的创建过程
下面我们展示bean的创建过程,假设这是没有解决死循环问题之前的情况 :

从图中可以看以看到,在设置属性时,递归处理依赖的bean,出现了死循环。
这个问题其实很好解决,加缓存,对象创建后先缓存再进行属性注入,如果出现循环依赖直接使用缓存的对象注入即可。
2.2 添加一个简单的缓存
加缓存,对象A创建后先缓存再进行属性B的注入,如果B的实例化出现循环依赖直接使用缓存中A的对象注入即可。避免了重新去实例化A,也就解决了循环问题。参见下图中绿色部分。
看上去这个问题就解决了,但是我们知道Spring AOP是在对象创建后的后置处理器中完成的,这就会出现一种情况如下图中红色部分展示的问题,可以看到B注入的是原始的A对象,而不是增强后的代理对象,这会导至AOP失效,这显然不是我们想要的结果。

3. spring的解决方法
通过三级缓存来实现,后面会详细解释他们的作用:
/** Cache of singleton objects: bean name --> bean instance */
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<String, Object>(256);
/** Cache of singleton factories: bean name --> ObjectFactory */
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<String, ObjectFactory<?>>(16);
/** Cache of early singleton objects: bean name --> bean instance */
private final Map<String, Object> earlySingletonObjects = new HashMap<String, Object>(16);
原理:
Spring 是通过提前暴露 bean 的引用来解决的。
什么叫提前暴露呢?Spring 首先使用构造函数创建一个 “不完整” 的 bean A实例(之所以说不完整,是因为此时该 bean 实例还未初始化),并且将 bean 实例放入 ObjectFactory缓存(将 ObjectFactory 放到 singletonFactories 缓存),下次别的bean B能从缓存中查到A的实例,虽然A还是未实例化的,但是能帮助B完成属性设置。相比于正常思维等A完全实例化后,才被B访问的场景来说,加入缓存这个过程就叫提前暴露。
大致步骤:

举个例子:A 依赖了 B,B 也依赖了 A,那么依赖注入过程如下:
-
检查 A 是否在缓存中,发现不存在,进行实例化
-
通过构造函数创建 bean A,并通过 ObjectFactory 提前曝光 bean A
-
A 走到属性填充阶段,发现依赖了 B,所以开始实例化 B。
-
首先检查 B 是否在缓存中,发现不存在,进行实例化
-
通过构造函数创建 bean B,并通过 ObjectFactory 曝光创建的 bean B
-
B 走到属性填充阶段,发现依赖了 A,所以开始实例化 A。
-
检查 A 是否在缓存中,发现存在,拿到 A 对应的 ObjectFactory 来获得 bean A,并返回。
-
B 继续接下来的流程,直至创建完毕,然后返回 A 的创建流程,A 同样继续接下来的流程,直至创建完毕。
这边通过缓存中的 ObjectFactory 拿到的 bean 实例虽然拿到的是 “不完整” 的 bean 实例,但是由于是单例,所以后续初始化完成后,该 bean 实例的引用地址并不会变,所以最终我们看到的还是完整 bean 实例。
蓝色字体很重要,这就是为什么单例才能实施的方案,针对多例无效的原因!因为多例有多个,缓存起来,没法对应了,而单例全局就一个,不会混淆
详细步骤:
步骤一
首先生成A的实例,就是调用getBean(A),把A加入到三级缓存中,经过步骤1、2、3,把A实例封装成ObjectFactory后放入三级缓存中:

(图1)把A加入三级缓存
- AbstractBeanFactory#doGetBean()方法中会调用2次getSingleton(),但是入参不同
- getSingleton(beanName),从多级缓存中查询A的实例,当然返回null
- getSingleton(String beanName, ObjectFactory<?> singletonFactory)
1.也是从缓存查询A的实例,但是仅从一级缓存查,没查到触发新建bean的操作,如蓝色箭头
2. 往singletonsCurrentlyInCreation集合增加一条记录,标记正在创建中- AbstractAutowireCapableBeanFactory#doCreateBean() 是创建bean的核心方法,重点的关注的是经过步骤1、2、3,把A实例
原始对象封装成ObjectFactory后放入三级缓存中
我们看下步骤3的实现,把ObjectFactory加入到singletonFactories中:
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
synchronized (this.singletonObjects) {
if (!this.singletonObjects.containsKey(beanName)) {
//加入ObjectFactory到singletonFactories中
this.singletonFactories.put(beanName, singletonFactory);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
}
A进行到步骤4,进行属性填充时,会发现需要注入B,因此要去实例化B,就是调用getBean(B)
步骤二
那么B的实例化和图1相同,经过步骤1、2、3会把B的实例也加入到三级缓存中。
步骤三
B继续进行,参照图1,到步骤4时,需要去注入A,因此去getBean(A),这个过程参见下图2:

图2 B循环依赖注入A
- 图2的第一步是指AbstractBeanFactory#doGetBean()方法中第1次getSingleton()方法,从多级缓存中试图读取A的实例,最终是从第三级缓存中读取到
- 图2的第三步有点瑕疵,没有列出方法名,仅列出方法的参数,指的是getSingleton(String beanName, boolean allowEarlyReference)方法
- 注意图2中的步骤4处代码,当执行完ObjectFactory.getObject()后,需要移除三级缓存,加入二级缓存,目的是避免多次执行三次缓存(执行完就删除即可,并且代理bean被放入二级缓存,查询顺序是1、2、3,下次就能从2中获取bean)
如果出现循环依赖就会先从三级缓存架构中获取bean对象,参见图2的1、2、3、4步骤。
图2的第三步是调用getSingleton,试图从缓存中获取bean实例,这个步骤是从一级缓存、二级缓存、三级缓存顺序来的,其中二级缓存有个前提条件是isSingletonCurrentlyInCreation(),如果返回true,表示当前待实例化的beanName处于实例化中(也就是出现了循环依赖),此时不需要重复创建,从二级缓存中创建。如果返回false,说明是首次需要创建的beanName,直接创建新的实例即可。那么这个方法时怎么实现的呢:
DefaultSingletonBeanRegistry#isSingletonCurrentlyInCreation()
public boolean isSingletonCurrentlyInCreation(String beanName) {
//原来有个记录正在创建的beanName集合
return this.singletonsCurrentlyInCreation.contains(beanName);
}
原来有个记录正在创建的beanName集合,集合的数据哪来的呢?往前文搜索singletonsCurrentlyInCreation即可
图2的第4步,提前触发构建代理对象(如果继承了ware接口,否则还是原始的对象):
DefaultSingletonBeanRegistry.java#getSingleton(String beanName, boolean allowEarlyReference)
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
//1. 先从一级缓存获取
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
//2. 一级缓存没有,查找二级缓存
singletonObject = this.earlySingletonObjects.get(beanName);
//2. 二级缓存也没有,查找三级缓存
if (singletonObject == null && allowEarlyReference) {
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
//4.三级缓存存在,使用工厂创建对象,并移动到二级缓存
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}
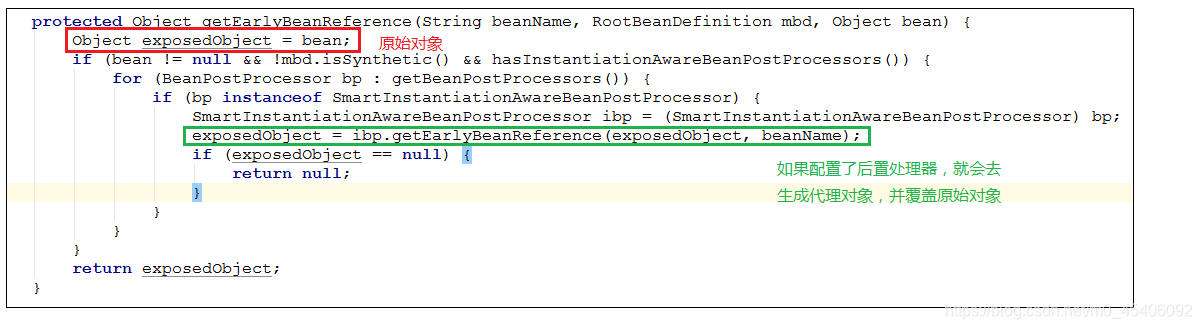
图2的第5步:通过工厂对象(ObjectFactory.getObject())来获取实际的bean对象并返回,可以看到如果没有配置后置处理器,那么返回的就是原始对象,如果配置了,就是代理后的对象:
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
return exposedObject;
如果配置了后置处理器,就会去生成代理对象:
三级缓存触发提前创建A的代理对象A1,并且把代理对象A1设置为B的属性,这样就解决了<2.1 添加一个简单的缓存>章节提到的AOP失效问题。
@Override
public Object getEarlyBeanReference(Object bean, String beanName) {
Object cacheKey = getCacheKey(bean.getClass(), beanName);
this.earlyProxyReferences.put(cacheKey, bean);
//生成代理对象
return wrapIfNecessary(bean, beanName, cacheKey);
}
3.1 三级缓存变量的作用
定义在DefaultSingletonBeanRegistry类中
/** Cache of singleton objects: bean name --> bean instance */
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<String, Object>(256);
/** Cache of singleton factories: bean name --> ObjectFactory */
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<String, ObjectFactory<?>>(16);
/** Cache of early singleton objects: bean name --> bean instance */
private final Map<String, Object> earlySingletonObjects = new HashMap<String, Object>(16);
3.1.1 、一级缓存 singletonObjects:
Map <String, Object> singletonObjects:
(1)第一级缓存的作用:
用于存储单例模式下创建的Bean实例(已经创建完毕)。
该缓存是对外使用的,指的就是使用Spring框架的程序员,即程序员写的业务程序调用的。
(2)存储什么数据?
K:bean的名称
V:bean的实例对象(有代理对象则指的是代理对象,已经创建完毕)
3.1.2、第二级缓存 earlySingletonObjects:
Map<String, Object> earlySingletonObjects
(1)第二级缓存的作用:
用于存储单例模式下创建的Bean实例(该Bean被提前暴露的引用,该Bean还在创建中)。
该缓存是对内使用的,指的就是Spring框架内部逻辑使用该缓存。
为了解决第一个classA引用最终如何替换为代理对象的问题(如果有代理对象),也就是说二级缓存里面的对象时经代理增强后的bean对象,而不是原始对象。
当然,如果bean没有继承ware接口的话,不需要代理,此时仍是原始对象
3.1.3、第三级缓存 singletonFactories:
Map<String, ObjectFactory<?>> singletonFactories
(1)第三级缓存的作用:
通过ObjectFactory对象来存储单例模式下提前暴露的Bean实例的引用(正在创建中)。
该缓存是对内使用的,指的就是Spring框架内部逻辑使用该缓存。
此缓存是解决循环依赖最大的功臣,作用是解决AOP问题。
(2)存储什么数据?
K:bean的名称
V:ObjectFactory,该对象持有提前暴露的bean的引用
怎么解决AOP问题的?简单来说,ObjectFactory持有原始对象bean实例,ObjectFactory顾名思义,是个工厂相关的东西,负责把原始对象提前进行代理增强。
为什么说提前增强呢?因为按照一般bean的初始化过程,在设置属性之后才会执行代理增强的逻辑,而此时,B设置属性A时,产生循环依赖问题,A还没设置B的属性,A还没有进行代理增强,B倘若设置A的原始对象,就会出错,因此B需要提前让A进行代理增强,这样B就是设置A的代理对象,即AOP对象
3.2 为什么第三级缓存要使用ObjectFactory?
如果仅仅是解决循环依赖问题,使用二级缓存就可以了,但是如果对象实现了AOP,那么注入到其他bean的时候,并不是最终的代理对象,而是原始的。这时就需要通过三级缓存的ObjectFactory才能提前产生最终的需要代理的对象。
3.3 为什么Spring不能解决构造器的循环依赖?
从流程图应该不难看出来,先放入三级缓存的是什么?是封装了原始bean对象的ObjectFactory,那么原始对象是怎么来的?反射,调用构造函数,因此,出现悖论,构造器A完成构造过程后才能放入缓存中,因此A的构造过程暂时不能放入缓存,但是A的构造过程会产生循环依赖,A要去实例化B,B在循环依赖的缓存中无法获取A,就出现循环问题,导致A永远无法构造完成,无法解决了!
因此,不能解决构造器问题。
3.4 为什么多例Bean不能解决循环依赖?
解决循环依赖的代码就是缓存,核心是利用一个map,来解决这个问题的,这个map就相当于缓存。
为什么可以这么做,因为我们的bean是单例的,而且是字段注入(setter注入)的,单例意味着只需要创建一次对象,后面就可以从缓存中取出来,key/vlue是一对一的关系,key是beanName。
如果是原型bean,那么就意味着每次都要去创建对象,无法利用缓存,怎么用map保存多对多的关系?而且beanName要相同。做不到
参考:
《【Spring源代码阅读之十二】spring的Bean创建过程和图解spring是如何解决循环依赖的》
《spring相互依赖怎么解决_Spring是怎么解决循环依赖的》
《Spring如何解决循环依赖问题》