查看版本号:
mysql数据库: select version()
oracle数据库: select * from v$instance
sqlserver数据库: SELECT @@VERSION
SqlServer
创建临时表:
select * into #haha from heheda where id>9;
复制表数据到另一个表:
SQL Server中,如果目标表存在:
insert into 目标表 select * from 原表;
SQL Server中,如果目标表不存在:
select * into 目标表 from 原表;
Oracle中,如果目标表存在:
insert into 目标表 select * from 原表;
commit;
Oracle中,如果目标表不存在:
create table 目标表 as select * from 原表;
update set from的用法:
update t1
set
bo_user_id=d.bo_user_id
from
vlc_cdo_vehicle_relation_20201124_2 t1
inner join
#tmp5 d
on
t1.fin_code=d.fin_code
where
t1.bo_user_id=0 and t1.dealer_id=327 and d.bo_user_id is not null;
exists用法:
select
id,dmp_id
from
vlc_bundles a
where
exists (select dmp_id,count(*) from vlc_bundles b where a.dmp_id=b.dmp_id group by dmp_id having count(1)>1);
delete exists select用法:
delete from vlc_bundles a
where
exists (select id,dmp_id,count(*) from vlc_bundles b where a.dmp_id=b.dmp_id group by dmp_id,id having count(1)>1);
查字符串长度函数:
select len('dsd');
json_value用法:
当表中某个字段存的值是json格式时内容太多只想查看其中一个字段的值:
select json_value(profile,'$.close_reason') from vlc_bundles;
convert函数:
对于简单类型转换,CONVERT()函数和CAST()函数的功能相同,只是语法不同。CAST()函数一般更容易使用,其功能也更简单。CONVERT()函数的优点是可以格式化日期和数值,它需要两个参数:第1个是目标数据类型,第2个是源数据。以下是两个例子:
SELECT CONVERT(int, '123');
SELECT CONVERT(date, '2020-08-02');
-- 使用convert转换时间格式获取小时,并转成int类型
SELECT top 10 created_at,CONVERT(INT, CONVERT(varchar(2),created_at, 108)) FROM dbo.heheda;
结果:
2018-05-29 02:01:35.463 2
2019-11-02 10:12:35.463 10
执行存储过程语句:
exec [lf_jybtjcpg_yuan].[dbo].[PRO_491] @tjrq=201801;
使用循环执行存储过程:
declare @tjrq int
set @tjrq=201311
while @tjrq<=201910
begin
if (right(@tjrq,2)>=13 and right(@tjrq,2)<=99) or right(@tjrq,2)=00
begin
select '不是日期,不执行';
end
else
begin
exec [lf_jybtjcpg_yuan].[dbo].[PRO_421_1b] @tjrq;
end
set @tjrq=@tjrq +1
end
DATEDIFF() 函数返回两个日期之间的时间:
SELECT DATEDIFF(day,'2008-12-29','2008-12-30') AS DiffDate
结果:1
语法:
DATEDIFF(datepart,startdate,enddate)
startdate 和 enddate 参数是合法的日期表达式。
datepart 参数可以是下列的值:
| datepart | 缩写 |
|---|---|
| 年 | yy, yyyy |
| 季度 | qq, q |
| 月 | mm, m |
| 年中的日 | dy, y |
| 日 | dd, d |
| 周 | wk, ww |
| 星期 | dw, w |
| 小时 | hh |
| 分钟 | mi, n |
| 秒 | ss, s |
| 毫秒 | ms |
| 微妙 | mcs |
| 纳秒 | ns |
中文查不出来的问题:
数据库中有中文,但是查询条件有中文怎么也查不出来,原来客户的数据库是英文版的,所以数据库中的字段值是Unicode编码。然后在查询时加入N即可,N是将其内容xxx作为 Unicode字符常量(双字节)。而没有N的 ‘yyy’, 是将yyy 作为字符常量(单字节)。
如select * from table where city=N'北京';
报错:Cannot resolve the collation conflict
在同一个数据库中用两张表进行关联查询报错:
Cannot resolve the collation conflict between "SQL_Latin1_General_CP1_CI_AS" and "Chinese_PRC_CI_AS" in the equal to operation.
解决:
select * from vlc_bundles a left join bundles_dashboard b
on a.dmp_id collate SQL_Latin1_General_CP1_CI_AS=b.dmp_id;
insert或者update的字段数据类型为datetime想插入空值的时候
不要写为’’,否则插入之后该字段的值为’1900-01-01 00:00:00.000’,应该插入NULL,如:
update vlc_dealers set deleted_at=NULL where id=193;
快速查看表结构:
SELECT CASE WHEN col.colorder = 1 THEN obj.name
ELSE ''
END AS 表名,
col.colorder AS 序号 ,
col.name AS 列名 ,
ISNULL(ep.[value], '') AS 列说明 ,
t.name AS 数据类型 ,
col.length AS 长度 ,
ISNULL(COLUMNPROPERTY(col.id, col.name, 'Scale'), 0) AS 小数位数 ,
CASE WHEN COLUMNPROPERTY(col.id, col.name, 'IsIdentity') = 1 THEN '√'
ELSE ''
END AS 标识即是否自增 ,
CASE WHEN EXISTS ( SELECT 1
FROM dbo.sysindexes si
INNER JOIN dbo.sysindexkeys sik ON si.id = sik.id
AND si.indid = sik.indid
INNER JOIN dbo.syscolumns sc ON sc.id = sik.id
AND sc.colid = sik.colid
INNER JOIN dbo.sysobjects so ON so.name = si.name
AND so.xtype = 'PK'
WHERE sc.id = col.id
AND sc.colid = col.colid ) THEN '√'
ELSE ''
END AS 主键 ,
CASE WHEN col.isnullable = 1 THEN '√'
ELSE ''
END AS 允许空 ,
ISNULL(comm.text, '') AS 默认值
FROM dbo.syscolumns col
LEFT JOIN dbo.systypes t ON col.xtype = t.xusertype
inner JOIN dbo.sysobjects obj ON col.id = obj.id
AND obj.xtype = 'U'
AND obj.status >= 0
LEFT JOIN dbo.syscomments comm ON col.cdefault = comm.id
LEFT JOIN sys.extended_properties ep ON col.id = ep.major_id
AND col.colid = ep.minor_id
AND ep.name = 'MS_Description'
LEFT JOIN sys.extended_properties epTwo ON obj.id = epTwo.major_id
AND epTwo.minor_id = 0
AND epTwo.name = 'MS_Description'
WHERE obj.name = 'TableName'--表名
ORDER BY col.colorder ;
查询表索引:
SELECT 索引名称=a.name
,表名=c.name
,索引字段名=d.name
,索引字段位置=d.colid
FROM sysindexes a
JOIN sysindexkeys b ON a.id=b.id AND a.indid=b.indid
JOIN sysobjects c ON b.id=c.id
JOIN syscolumns d ON b.id=d.id AND b.colid=d.colid
WHERE a.indid NOT IN(0,255)
-- and c.xtype='U' and c.status>0 --查所有用户表
AND c.name='bundles_dashboard' --查指定表
ORDER BY c.name,a.name,d.name
重建索引:
alter index pk_my_users on my_users rebuild;
可参考:https://blog.csdn.net/mituan1234567/article/details/7950573或者http://lusanxiong.iteye.com/blog/1544950
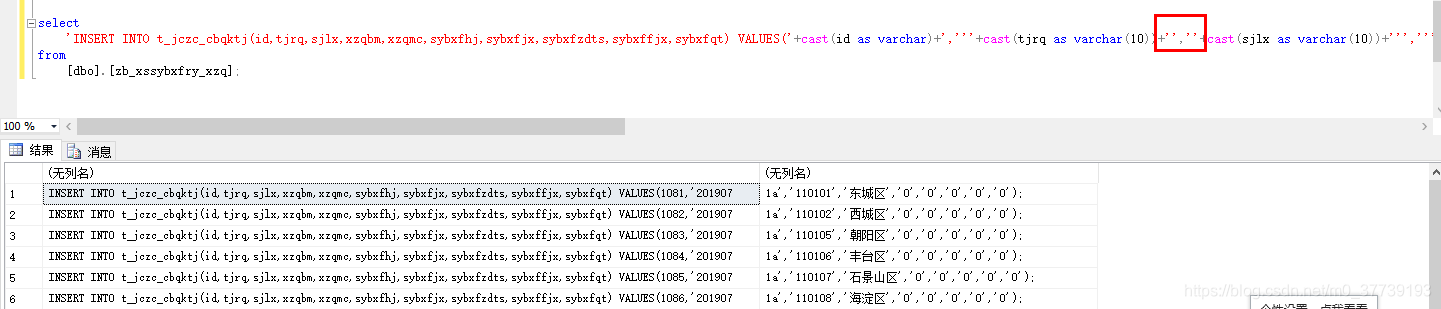
将表数据改造成insert语句:
方法一:
select
'INSERT INTO t_jczc_cbqktj(id,tjrq,sjlx,xzqbm,xzqmc,sybxfhj,sybxfjx,sybxfzdts,sybxffjx,sybxfqt) VALUES('+cast(id as varchar)+','''+tjrq+''','''+sjlx+''','''+xzqbm+''','''+xzqmc+''','''+sybxfhj+''','''+sybxfjx+''','''+sybxfzdts+''','''+sybxffjx+''','''+sybxfqt+''');'
from
[dbo].[zb_xssybxfry_xzq];
运行结果:
INSERT INTO t_jczc_cbqktj(id,tjrq,sjlx,xzqbm,xzqmc,sybxfhj,sybxfjx,sybxfzdts,sybxffjx,sybxfqt) VALUES(1081,'201907','1a','110101','东城区','0','0','0','0','0');
INSERT INTO t_jczc_cbqktj(id,tjrq,sjlx,xzqbm,xzqmc,sybxfhj,sybxfjx,sybxfzdts,sybxffjx,sybxfqt) VALUES(1082,'201907','1a','110102','西城区','0','0','0','0','0');

备注:
(1).经测试,该用法在SQLserver上可以,在gaussDb上不行
(2).这张表id字段为bigint类型,其他字段都为varchar类型,用+号拼接的时候会要求所有字段的数据类型一致,不一致的话它会自动强转
(3).两个单引号表示一个引号,如果用一个引号的话会导致成多列而不是一列
方法二:
select
concat('INSERT INTO t_jczc_cbqktj(id,tjrq,sjlx,xzqbm,xzqmc,sybxfhj,sybxfjx,sybxfzdts,sybxffjx,sybxfqt) VALUES(',id,',''',tjrq,''',''',sjlx,''',''',xzqbm,''',''',xzqmc,''',''',sybxfhj,''',''',sybxfjx,''',''',sybxfzdts,''',''',sybxffjx,''',''',sybxfqt,''');')
from
[dbo].[zb_xssybxfry_xzq];
备注:
(1).经测试,该用法在SQLserver上可以,在gaussDb上也适用
需要注意的点:
1.在做多表查询,每一个派生出来的表都必须有一个自己的别名,例如:
错误写法:select count(1) from (select hehe from haha);
正确写法:select count(1) from (select hehe from haha) a;
2.使用having的时候别名无效,例如:
错误写法:select count(1) a,haha from hehe group by haha having a>1;
正确写法:select count(1) a,haha from hehe group by haha having count(1)>1;
Oracle
创建表之前如果表存在则删除:
declare
num number;
begin
select count(1) into num from dba_tables where table_name = upper('AAA_HEHEDA') ;
if num > 0 then
execute immediate 'drop table xiao_qiang.aaa_heheda' ;
end if;
end;
java代码实现:
int count = GaussUttils.countoracle(conn_gauss);
if (count != 0) {
GaussUttils.executeSqls(conn_gauss);
}
public static int countoracle(Connection conn){
String sql = "select count(1) count from dba_tables where table_name = ('AAA_HEHEDA')";
ResultSet set = null;
int result = 0;
try {
Statement stmt = null;
stmt = conn.createStatement();
set = stmt.executeQuery(sql);
if(set.next()){
result = set.getInt("count");
}
} catch (SQLException e) {
e.printStackTrace();
}
return result;
}
public static void executeSqls(Connection conn) {
Statement stmt = null;
try {
stmt = conn.createStatement();
stmt.execute("drop table xiao_qiang.aaa_heheda");
stmt.close();
} catch (SQLException e) {
if (stmt != null) {
try {
stmt.close();
} catch (SQLException e1) {
e1.printStackTrace();
}
}
e.printStackTrace();
}
}
注意:在用Java执行oracle语句的时候双引号里面一定不要有分号,如stmt.execute("drop table xiao_qiang.aaa_heheda");不要写成stmt.execute("drop table xiao_qiang.aaa_heheda;");否则会报错“ORA-00911: 无效字符问题”,而在gauss的代码中加了分号也可以正常执行而不会报这个错误。
update和select结合使用:
(1)update tableName set (a,b,c)=(select a,b,c from ida where ida.id=tableName.id);
(2)update tableName t1 set a=(select t2.a from ida t2 where t1.id=t2.id),b=(select t2.b from ida t2 where t1.id=t2.id),c=(select t2.c from ida t2 where t1.id=t2.id);
(3)每条数据执行为:UPDATE tableName SET (A,B,C)=(select A,B,C from tableName where id=''xxxxxx) WHERE id='xxxxxxx';
with:
with
hehe as
(select * from xiao_ogg.t_heheda partition(jsrq_2019_12)),
haha as
(select * from xiao_ogg.t_hahada partition(jsrq_2019_12) where TZBZ='1')
select
a.he,
b.ha,
case
when b.qie is null then '否'
else '是'
end "小强签名设计"
from
xiao_ogg.t_qieda a
left join
hehe b
on
a.gid = b.gid;
注意:with和insert into在Oracle和Hive中的不同写法
Oracle:
INSERT INTO TABLE_B
WITH TEMP_A AS (
SELECT TIME,IOT_ID,NAME FROM IOT_XX_A
),TEMP_B AS (
SELECT TIME,IOT_ID,NAME,COUNT(DISTINCT IOT_ID) AS TIMES FROM TEMP_A
GROUP BY TIME,IOT_ID,NAME
)
SELECT TIME,IOT_ID,NAME,TIMES FROM TEMP_B;
按照上面的SQL语句,在ORACLE会执行,而在hive呢?他就会报错,具体的错是:Error: Error while compiling statement: FAILED: ParseException line 2:0 cannot recognize input near 'WITH' 'TABLE_B' 'AS' in statement
错误的原因就是INSERT INTO 位置放得不合适。把INSERT INTO语句换一下位置就可以执行了。
Hive:
WITH TEMP_A AS (
SELECT TIME,IOT_ID,NAME FROM IOT_XX_A
),TEMP_B AS (
SELECT TIME,IOT_ID,NAME,COUNT(DISTINCT IOT_ID) AS TIMES FROM TEMP_A
GROUP BY TIME,IOT_ID,NAME
)
INSERT INTO TABLE_B
SELECT TIME,IOT_ID,NAME,TIMES FROM TEMP_B;
add_months()函数:
ADD_MONTHS函数在输入日期上加上指定的几个月返回一个新的日期。如果给出一负数,返回值日期之前几个月日期。
ADD_MONTHS(DATE,NUMBER)中的NUMBER应当是整数,给出小数时,正数被截为小于该数的最大整数,负数被截为大于该数的最小整数。
例:add_months(to_date('29-Feb-96','d-mon-yyyy'),-12.99) 返回 28-Feb-95
注:上例中29调整为28,是因为96年二月份最后一天是29号,而95年二月份最后一天是28号。
add_months(to_date('15-Nov-1961','d-mon-yyyy'),1) 返回 15-Dec-1961
add_months(to_date('30-Nov-1961','d-mon-yyyy'),1) 返回 31-Dec-1961
注:从30调整为31,为了保持都是对应最后一天。
add_months(to_date('31-Jan-1999','d-mon-yyyy'),1) 返回 28-Feb-1999
注:函数将31日调为28日,以使结果对应新一月的最后一天,因1999年2月只有28天
例:从emp表查询列出来公司就职时间超过24年的员工名单
select ename, hiredate
from emp
where hiredate <= add_months(sysdate, -288);
注:负数代表系统时间(sysdate)之前的24年的时间-288 = -24*12
左连接数据变少:
前言:有一次我用两张表左关联后生成的结果比主表的数据量要少,一开始百思不得其解,后来终于想明白了。
原因:where加在了左关联之后,和放在左关联之前的结果数据量是不一样的。
select
*
from
hehe a
left join
haha b
on
a.dwid=b.dwid
where
a.bbyf='2020-07-01 00:00:00'
and
b.bbyf='2020-07-01 00:00:00';
注:当关联后的b表的bbyf字段不满足where条件的时候,上面的结果数量会少于下面的
select
*
from
(select * from hehe where bbyf='2020-07-01 00:00:00') a
left join
(select * from haha where bbyf='2020-07-01 00:00:00') b
on
a.dwid=b.dwid;
Mysql
分组之前进行排序:
SELECT * FROM(SELECT * FROM biz_messageboard ORDER BY CREATETIME DESC) a GROUP BY a.USERID;
select * from goonie_article_view where id%2=1 and id < 3094578 ORDER BY id DESC limit 50
查询媒体名称为"小强日报"的数据量:
SELECT COUNT(*) FROM goonie_article_view WHERE SUBSTRING_INDEX(`goonie_article_view`.`mediaNameZh`,'-',1) = "小强日报";
SELECT * FROM beauty_article_view WHERE SUBSTRING_INDEX(`beauty_article_view`.`mediaNameZh`,'-',-1) = "旅游";
SELECT * FROM goonie_article_view WHERE author LIKE "张%";
SELECT COUNT(*) FROM goonie_article_view WHERE pubdate > "2018-05-09 18:00:00";
SELECT * FROM beauty_article_view WHERE codename='礼仪' AND id BETWEEN 1216 AND 1318;
SELECT * FROM beauty_article_view WHERE codename='语录' OR codename='礼仪' AND id < 24658 ORDER BY id DESC LIMIT 50;
内连接:
SELECT COUNT(*) FROM goonie_article_view w INNER JOIN gooniewechat_key t ON w.`creator`=t.`weixin_name` WHERE w.`gather_time`>="2019-01-29";
去重:
SELECT COUNT(DISTINCT(codename)) FROM beauty_article_view;
SELECT DISTINCT(codename) FROM beauty_article_view;
简单的增删改:
UPDATE afacebooktoken SET token='EAACEdEose0' where id=1;
DELETE FROM afacebooktoken WHERE id=1;
INSERT INTO afacebooktoken VALUES(1,'EAAL7AMi5Z');
beauty_article_view视图:
CREATE ALGORITHM=UNDEFINED DEFINER=`woman`@`%` SQL SECURITY DEFINER VIEW `beauty1_article_view` AS
select
`a`.`id` AS `id`,
`a`.`creator` AS `author`,
`a`.`publish_time` AS `pubdate`,
`a`.`site_code` AS `media_level`,
`a`.`source` AS `trans_from_m`,
`a`.`title` AS `titleZh`,
`a`.`depth` AS `depth`,
`a`.`location` AS `page_place_src`,
`a`.`url` AS `url`,
`a`.`content_finger` AS `finger`,
`a`.`url_hash` AS `url_hash`,
`d`.`content` AS `textZh`,
`d`.`summary` AS `abstractZh`,
`d`.`keywords` AS `keywordsZh`,
`e`.`description` AS `codename`,
`a`.`detriment` AS `detriment`,
#`c`.`name` AS `mediaNameZh`,
`a`.`gather_time` AS `gather_time`
from ((`gooniearticle` `a`
join `gooniearticledetailed` `d`)
join `goonienewssort` `e`)
where (`a`.`id` = `d`.`pid`)
and (`d`.`infoid` = `e`.`id`)
order by `a`.`id`
创建表:
CREATE TABLE `biz_reply` (
`id` BIGINT(64) NOT NULL AUTO_INCREMENT,
`userid` VARCHAR(255) DEFAULT NULL COMMENT '用户id',
`shopid` VARCHAR(200) DEFAULT '' COMMENT '商家id',
`recontent` VARCHAR(1000) DEFAULT '' COMMENT '留言内容',
`createId` VARCHAR(32) DEFAULT NULL COMMENT '创建人',
`createTime` DATETIME DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8;
CHARSET=utf8mb4能存储Emoji表情
索引:
创建普通索引:
CREATE INDEX t_grhx_grbq_index ON t_grhx_grbq(sfzhm);
查看索引:
show index from t_grhx_grbq;
日期和字符相互转换:
date_format(date,'%Y-%m-%d') -------------->oracle中的to_char();
str_to_date(date,'%Y-%m-%d') -------------->oracle中的to_date();
%Y:代表4位的年份
%y:代表2为的年份
%m:代表月, 格式为(01……12)
%c:代表月, 格式为(1……12)
%d:代表月份中的天数,格式为(00……31)
%e:代表月份中的天数, 格式为(0……31)
%H:代表小时,格式为(00……23)
%k:代表 小时,格式为(0……23)
%h: 代表小时,格式为(01……12)
%I: 代表小时,格式为(01……12)
%l :代表小时,格式为(1……12)
%i: 代表分钟, 格式为(00……59)
%r:代表 时间,格式为12 小时(hh:mm:ss [AP]M)
%T:代表 时间,格式为24 小时(hh:mm:ss)
%S:代表 秒,格式为(00……59)
%s:代表 秒,格式为(00……59)
SELECT DATE_FORMAT(20130111191640,'%Y-%m-%d %H:%i:%s')
DATE_FORMAT(20130111191640,'%Y-%m-%d %H:%i:%s')
开窗函数:
说明:开窗函数与聚合函数一样,也是对行集组进行聚合计算,但是它不像普通聚合函数那样每组只返回一个值,开窗函数可以为每组返回多个值,因为开窗函数所执行聚合计算的行集组是窗口。
语法:
主要是over( PARTITION BY (根据某条件分组,形成一个小组)….ORDER BY(再组内进行排序) …. )
常用函数:
参考:https://www.bbsmax.com/A/q4zVkPLxJK/
1、row_number() over(partition by … order by …)
2、rank() over(partition by … order by …)
3、dense_rank() over(partition by … order by …)
rank(): 跳跃排序,如果有两个第一级时,接下来就是第三级。
dense_rank(): 连续排序,如果有两个第一级时,接下来仍然是第二级。
4、count() over(partition by … order by …)
5、max() over(partition by … order by …)
6、min() over(partition by … order by …)
7、sum() over(partition by … order by …)
8、avg() over(partition by … order by …)
9、first_value() over(partition by … order by …)
10、last_value() over(partition by … order by …)
11、lag() over(partition by … order by …)
12、lead() over(partition by … order by …)
lag 和lead 可以 获取结果集中,按一定排序所排列的当前行的上下相邻若干offset 的某个行的某个列(不用结果集的自关联);
lag ,lead 分别是向前,向后;
lag 和lead 有三个参数,第一个参数是列名,第二个参数是偏移的offset,第三个参数是 超出记录窗口时的默认值)
但是:mysql 8.0版本以下并不支持,只能通过变通的方法实现相同的功能
(1)实现自增:
SELECT
@num := @num+1 score_ranking,
id
FROM
`user`, (SELECT @num := 0) t1
ORDER BY
id DESC;
(2)实现rank():
参考:https://blog.csdn.net/justry_deng/article/details/80597916
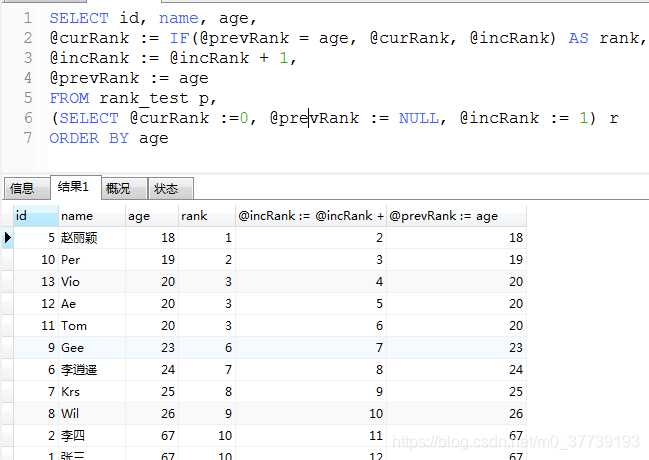
(3)8.0版本以上实现rank():rank()、row_number()、dense_rank()
参考:https://blog.csdn.net/sqsltr/article/details/94408487
create table students(
id int(4) auto_increment primary key,
name varchar(50) not null,
score int(4) not null
);
insert into students(name,score) values('curry', 100),
('klay', 99),
('KD', 100),
('green', 90),
('James', 99),
('AD', 96);
select id, name, rank() over(order by score desc) as r from students;
select id, name, DENSE_RANK() OVER(order by score desc) as dense_r from students;
select id, name, row_number() OVER(order by score desc) as row_r from students;
if函数:
语法: if(boolean testCondition, T valueTrue, T valueFalseOrNull)
说明: 当条件testCondition为TRUE时,返回valueTrue;否则返回valueFalseOrNull
mysql和hive都适用
实例1:
select if(hehe='小强',1,2) as flag from t_xiaoqiang;
实例2:
select if(haha is not null,'hehe',123) from t_xiaoqiang;
需要注意的点:
1.在做多表查询,或者查询的时候产生新的表的时候会出现这个错误:Every derived table must have its own alias(每一个派生出来的表都必须有一个自己的别名,同样适用于SqlServer)。
2.同级生成的别名字段不可以使用,只能嵌套使用(这样感觉增加了语句量,在Gauss是可以做到的)
mysql:
SELECT
a.hehe heheda,
heheda*12
FROM
haha a;
报错:Unknown column 'heheda' in 'field list'
Gauss:
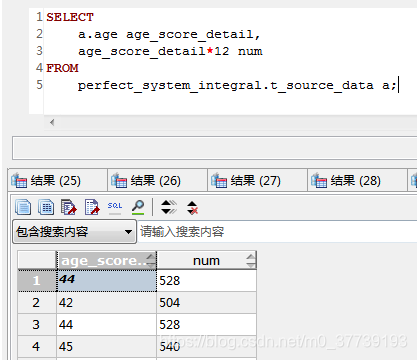
Hive
创建数据库:
create database jiuyebu;
使用数据库:
use jiuyebu;
重命名表名:
ALTER TABLE FaRen_JiChuShuJu141 RENAME TO FaRen_JiChuShuJu;
建表时判断该表是否存在:
create table if not exists zb_xsgsbqy_xzq。。。
查询某个表的分区信息:
show partitions employee;
展示表结构:
show create table + 表名;
desc命令:
desc 命令是为了展示hive表格的内在属性。例如列名,data_type,存储位置等信息。这个命令常常用在我们对hive表格观察之时,我们想要知道这个hive各个列名,hive表格的存储位置。
desc table + 表名;
要想获得更加详细的内容,我们可以使用 desc formatted 命令。
想获得表中有分区的情况:
desc formatted revr_bmbs_dmp_offline.rv_dmp_offline_tags_hist partition(dt=20210307);
双分区的情况:
+----------------------+
| partition |
+----------------------+
| dt=20210309/hour=6 |
+----------------------+
desc formatted revr_bmbs_dmp_offline.rt_recmd_message partition(dt=20210309,hour=6);
将生成的结果导入到一个文件中:
beeline --outputformat=tsv2 -e "select dmp_id from huiq.heheda where partition_date='20201205'" > 20201205_rd_tmp.csv
注:Beeline和其他工具有一些不同,执行查询都是正常的SQL输入,但是如果是一些管理的命令,比如进行连接,中断,退出,执行Beeline命令需要带上“!”,不需要终止符。常用命令介绍:
1、!connect url –连接不同的Hive2服务器
2、!exit –退出shell
3、!help –显示全部命令列表
4、!verbose –显示查询追加的明细
The Beeline CLI 支持以下命令行参数:
Option
Description
--autoCommit=[true/false] ---进入一个自动提交模式:beeline --autoCommit=true
--autosave=[true/false] ---进入一个自动保存模式:beeline --autosave=true
--color=[true/false] ---显示用到的颜色:beeline --color=true
--delimiterForDSV= DELIMITER ---分隔值输出格式的分隔符。默认是“|”字符。
--fastConnect=[true/false] ---在连接时,跳过组建表等对象:beeline --fastConnect=false
--force=[true/false] ---是否强制运行脚本:beeline--force=true
--headerInterval=ROWS ---输出的表间隔格式,默认是100: beeline --headerInterval=50
--help ---帮助 beeline --help
--hiveconf property=value ---设置属性值,以防被hive.conf.restricted.list重置:beeline --hiveconf prop1=value1
--hivevar name=value ---设置变量名:beeline --hivevar var1=value1
--incremental=[true/false] ---输出增量
--isolation=LEVEL ---设置事务隔离级别:beeline --isolation=TRANSACTION_SERIALIZABLE
--maxColumnWidth=MAXCOLWIDTH ---设置字符串列的最大宽度:beeline --maxColumnWidth=25
--maxWidth=MAXWIDTH ---设置截断数据的最大宽度:beeline --maxWidth=150
--nullemptystring=[true/false] ---打印空字符串:beeline --nullemptystring=false
--numberFormat=[pattern] ---数字使用DecimalFormat:beeline --numberFormat="#,###,##0.00"
--outputformat=[table/vertical/csv/tsv/dsv/csv2/tsv2] ---输出格式:beeline --outputformat=tsv (默认为talbe)
--showHeader=[true/false] ---显示查询结果的列名:beeline --showHeader=false
--showNestedErrs=[true/false] ---显示嵌套错误:beeline --showNestedErrs=true
--showWarnings=[true/false] ---显示警告:beeline --showWarnings=true
--silent=[true/false] ---减少显示的信息量:beeline --silent=true
--truncateTable=[true/false] ---是否在客户端截断表的列
--verbose=[true/false] ---显示详细错误信息和调试信息:beeline --verbose=true
-d <driver class> ---使用一个驱动类:beeline -d driver_class
-e <query> ---使用一个查询语句:beeline -e "query_string"
-f <file> ---加载一个文件:beeline -f filepath 多个文件用-e file1 -e file2
-n <username> ---加载一个用户名:beeline -n valid_user
-p <password> ---加载一个密码:beeline -p valid_password
-u <database URL> ---加载一个JDBC连接字符串:beeline -u db_URL
datediff,date_add和date_sub:
1、日期比较函数:datediff语法:datediff(string enddate,string startdate)
返回值:int
说明:返回结束日期减去开始日期的天数。
例如:
hive> select datediff('2019-10-13','2019-10-03');
OK
10
2、日期增加函数:date_add语法:date_add(string startdate, intdays)
返回值:String
说明:返回开始日期startdate增加days天后的日期
例如:
hive> select date_add('2019-10-13',10);
OK
2019-10-23
3、日期减少函数:date_sub语法: date_sub (string startdate,int days)
返回值:String
说明:返回开始日期startdate减少days天后的日期
例如:
hive> select date_sub('2019-10-13',10);
OK
2019-10-03